 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Unlearning Doesn't Do What You Think: Lessons for Generative AI Policy, Research, and Practice
Dec 09, 2024



We articulate fundamental mismatches between technical methods for machine unlearning in Generative AI, and documented aspirations for broader impact that these methods could have for law and policy. These aspirations are both numerous and varied, motivated by issues that pertain to privacy, copyright, safety, and more. For example, unlearning is often invoked as a solution for removing the effects of targeted information from a generative-AI model's parameters, e.g., a particular individual's personal data or in-copyright expression of Spiderman that was included in the model's training data. Unlearning is also proposed as a way to prevent a model from generating targeted types of information in its outputs, e.g., generations that closely resemble a particular individual's data or reflect the concept of "Spiderman." Both of these goals--the targeted removal of information from a model and the targeted suppression of information from a model's outputs--present various technical and substantive challenges. We provide a framework for thinking rigorously about these challenges, which enables us to be clear about why unlearning is not a general-purpose solution for circumscribing generative-AI model behavior in service of broader positive impact. We aim for conceptual clarity and to encourage more thoughtful communication among machine learning (ML), law, and policy experts who seek to develop and apply technical methods for compliance with policy objectives.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Frontier AI Regulation: Managing Emerging Risks to Public Safety
Jul 11, 2023Advanced AI models hold the promise of tremendous benefits for humanity, but society needs to proactively manage the accompanying risks. In this paper, we focus on what we term "frontier AI" models: highly capable foundation models that could possess dangerous capabilities sufficient to pose severe risks to public safety. Frontier AI models pose a distinct regulatory challenge: dangerous capabilities can arise unexpectedly; it is difficult to robustly prevent a deployed model from being misused; and, it is difficult to stop a model's capabilities from proliferating broadly. To address these challenges, at least three building blocks for the regulation of frontier models are needed: (1) standard-setting processes to identify appropriate requirements for frontier AI developers, (2) registration and reporting requirements to provide regulators with visibility into frontier AI development processes, and (3) mechanisms to ensure compliance with safety standards for the development and deployment of frontier AI models. Industry self-regulation is an important first step. However, wider societal discussions and government intervention will be needed to create standards and to ensure compliance with them. We consider several options to this end, including granting enforcement powers to supervisory authorities and licensure regimes for frontier AI models. Finally, we propose an initial set of safety standards. These include conducting pre-deployment risk assessments; external scrutiny of model behavior; using risk assessments to inform deployment decisions; and monitoring and responding to new information about model capabilities and uses post-deployment. We hope this discussion contributes to the broader conversation on how to balance public safety risks and innovation benefits from advances at the frontier of AI development.
A Hazard Analysis Framework for Code Synthesis Large Language Models
Jul 25, 2022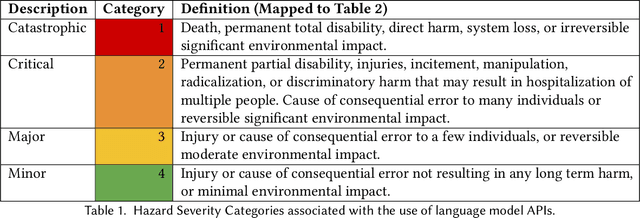
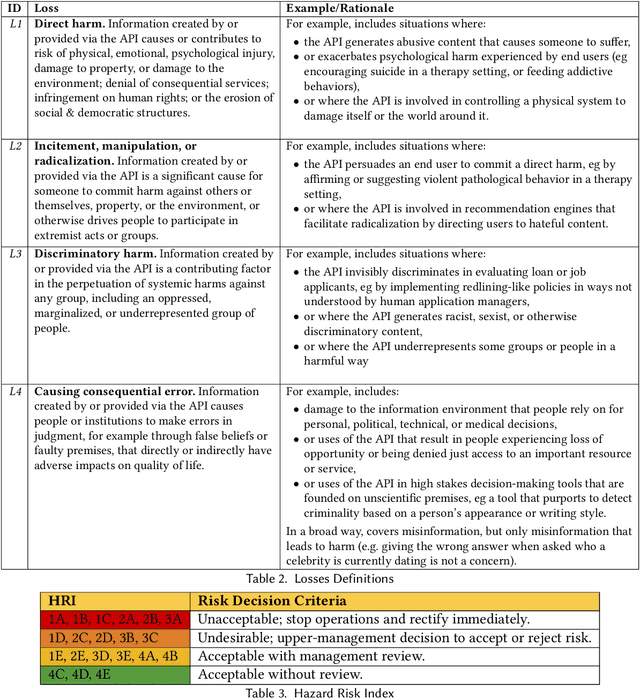
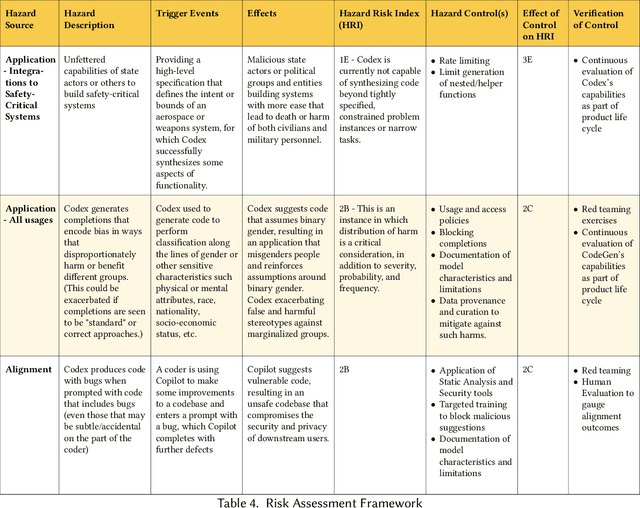
Codex, a large language model (LLM) trained on a variety of codebases, exceeds the previous state of the art in its capacity to synthesize and generate code. Although Codex provides a plethora of benefits, models that may generate code on such scale have significant limitations, alignment problems, the potential to be misused, and the possibility to increase the rate of progress in technical fields that may themselves have destabilizing impacts or have misuse potential. Yet such safety impacts are not yet known or remain to be explored. In this paper, we outline a hazard analysis framework constructed at OpenAI to uncover hazards or safety risks that the deployment of models like Codex may impose technically, socially, politically, and economically. The analysis is informed by a novel evaluation framework that determines the capacity of advanced code generation techniques against the complexity and expressivity of specification prompts, and their capability to understand and execute them relative to human ability.
Filling gaps in trustworthy development of AI
Dec 14, 2021The range of application of artificial intelligence (AI) is vast, as is the potential for harm. Growing awareness of potential risks from AI systems has spurred action to address those risks, while eroding confidence in AI systems and the organizations that develop them. A 2019 study found over 80 organizations that published and adopted "AI ethics principles'', and more have joined since. But the principles often leave a gap between the "what" and the "how" of trustworthy AI development. Such gaps have enabled questionable or ethically dubious behavior, which casts doubts on the trustworthiness of specific organizations, and the field more broadly. There is thus an urgent need for concrete methods that both enable AI developers to prevent harm and allow them to demonstrate their trustworthiness through verifiable behavior. Below, we explore mechanisms (drawn from arXiv:2004.07213) for creating an ecosystem where AI developers can earn trust - if they are trustworthy. Better assessment of developer trustworthiness could inform user choice, employee actions, investment decisions, legal recourse, and emerging governance regimes.
Evaluating CLIP: Towards Characterization of Broader Capabilities and Downstream Implications
Aug 05, 2021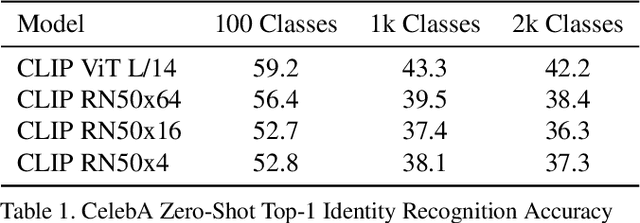
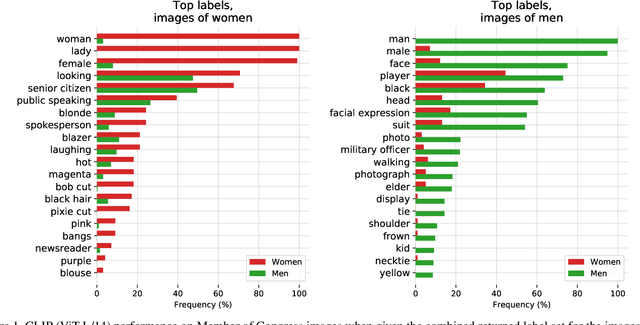


Recently, there have been breakthroughs in computer vision ("CV") models that are more generalizable with the advent of models such as CLIP and ALIGN. In this paper, we analyze CLIP and highlight some of the challenges such models pose. CLIP reduces the need for task specific training data, potentially opening up many niche tasks to automation. CLIP also allows its users to flexibly specify image classification classes in natural language, which we find can shift how biases manifest. Additionally, through some preliminary probes we find that CLIP can inherit biases found in prior computer vision systems. Given the wide and unpredictable domain of uses for such models, this raises questions regarding what sufficiently safe behaviour for such systems may look like. These results add evidence to the growing body of work calling for a change in the notion of a 'better' model--to move beyond simply looking at higher accuracy at task-oriented capability evaluations, and towards a broader 'better' that takes into account deployment-critical features such as different use contexts, and people who interact with the model when thinking about model deployment.
Evaluating Large Language Models Trained on Code
Jul 14, 2021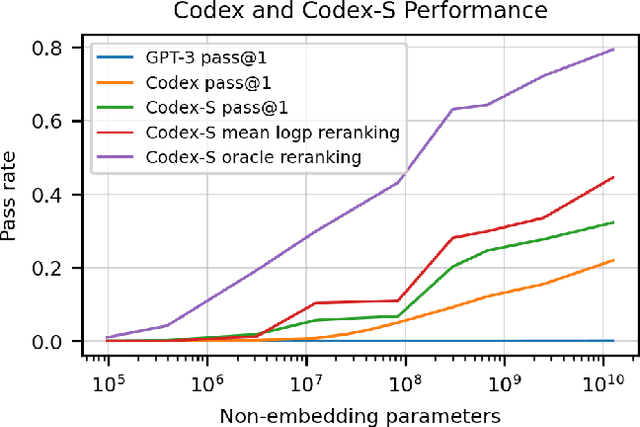
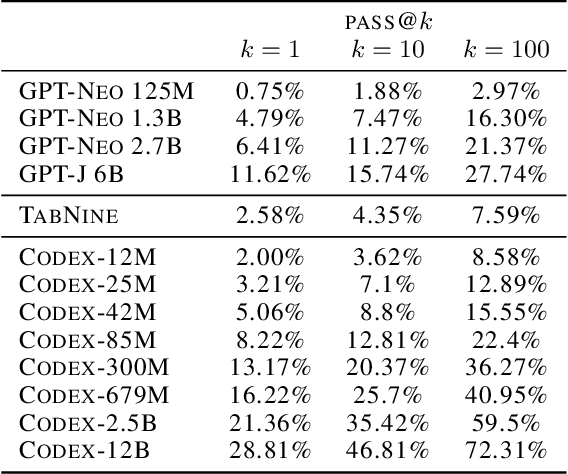
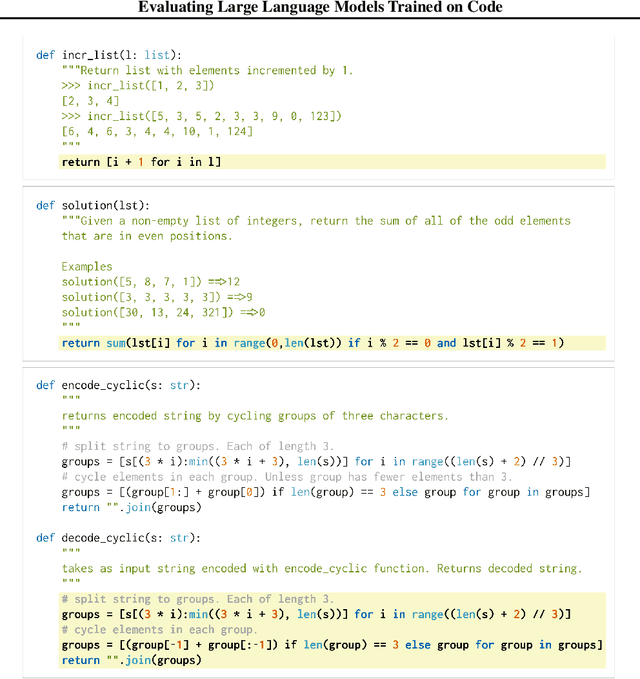
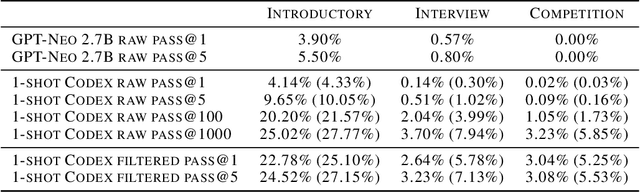
We introduce Codex, a GPT language model fine-tuned on publicly available code from GitHub, and study its Python code-writing capabilities. A distinct production version of Codex powers GitHub Copilot. On HumanEval, a new evaluation set we release to measure functional correctness for synthesizing programs from docstrings, our model solves 28.8% of the problems, while GPT-3 solves 0% and GPT-J solves 11.4%. Furthermore, we find that repeated sampling from the model is a surprisingly effective strategy for producing working solutions to difficult prompts. Using this method, we solve 70.2% of our problems with 100 samples per problem. Careful investigation of our model reveals its limitations, including difficulty with docstrings describing long chains of operations and with binding operations to variables. Finally, we discuss the potential broader impacts of deploying powerful code generation technologies, covering safety, security, and economics.
Understanding the Capabilities, Limitations, and Societal Impact of Large Language Models
Feb 04, 2021On October 14th, 2020, researchers from OpenAI, the Stanford Institute for Human-Centered Artificial Intelligence, and other universities convened to discuss open research questions surrounding GPT-3, the largest publicly-disclosed dense language model at the time. The meeting took place under Chatham House Rules. Discussants came from a variety of research backgrounds including computer science, linguistics, philosophy, political science, communications, cyber policy, and more. Broadly, the discussion centered around two main questions: 1) What are the technical capabilities and limitations of large language models? 2) What are the societal effects of widespread use of large language models? Here, we provide a detailed summary of the discussion organized by the two themes above.
Release Strategies and the Social Impacts of Language Models
Aug 24, 2019Large language models have a range of beneficial uses: they can assist in prose, poetry, and programming; analyze dataset biases; and more. However, their flexibility and generative capabilities also raise misuse concerns. This report discusses OpenAI's work related to the release of its GPT-2 language model. It discusses staged release, which allows time between model releases to conduct risk and benefit analyses as model sizes increased. It also discusses ongoing partnership-based research and provides recommendations for better coordination and responsible publication in AI.
The Role of Cooperation in Responsible AI Development
Jul 10, 2019In this paper, we argue that competitive pressures could incentivize AI companies to underinvest in ensuring their systems are safe, secure, and have a positive social impact. Ensuring that AI systems are developed responsibly may therefore require preventing and solving collective action problems between companies. We note that there are several key factors that improve the prospects for cooperation in collective action problems. We use this to identify strategies to improve the prospects for industry cooperation on the responsible development of AI.