 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Attention Sorting Combats Recency Bias In Long Context Language Models
Sep 28, 2023



Current language models often fail to incorporate long contexts efficiently during generation. We show that a major contributor to this issue are attention priors that are likely learned during pre-training: relevant information located earlier in context is attended to less on average. Yet even when models fail to use the information from a relevant document in their response, they still pay preferential attention to that document compared to an irrelevant document at the same position. We leverage this fact to introduce ``attention sorting'': perform one step of decoding, sort documents by the attention they receive (highest attention going last), repeat the process, generate the answer with the newly sorted context. We find that attention sorting improves performance of long context models. Our findings highlight some challenges in using off-the-shelf language models for retrieval augmented generation.
Mastering the Game of No-Press Diplomacy via Human-Regularized Reinforcement Learning and Planning
Oct 11, 2022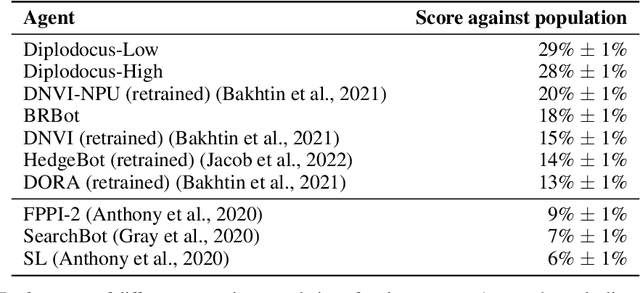

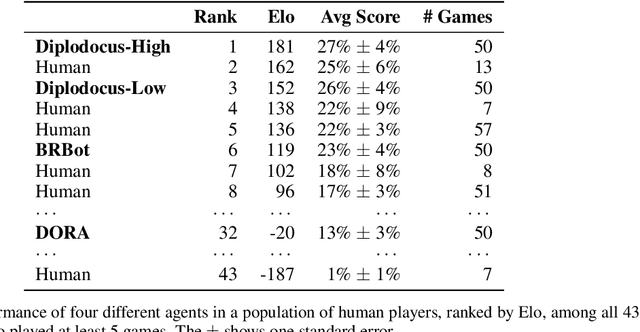
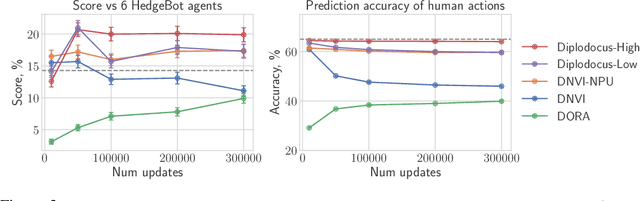
No-press Diplomacy is a complex strategy game involving both cooperation and competition that has served as a benchmark for multi-agent AI research. While self-play reinforcement learning has resulted in numerous successes in purely adversarial games like chess, Go, and poker, self-play alone is insufficient for achieving optimal performance in domains involving cooperation with humans. We address this shortcoming by first introducing a planning algorithm we call DiL-piKL that regularizes a reward-maximizing policy toward a human imitation-learned policy. We prove that this is a no-regret learning algorithm under a modified utility function. We then show that DiL-piKL can be extended into a self-play reinforcement learning algorithm we call RL-DiL-piKL that provides a model of human play while simultaneously training an agent that responds well to this human model. We used RL-DiL-piKL to train an agent we name Diplodocus. In a 200-game no-press Diplomacy tournament involving 62 human participants spanning skill levels from beginner to expert, two Diplodocus agents both achieved a higher average score than all other participants who played more than two games, and ranked first and third according to an Elo ratings model.
Human-AI Coordination via Human-Regularized Search and Learning
Oct 11, 2022
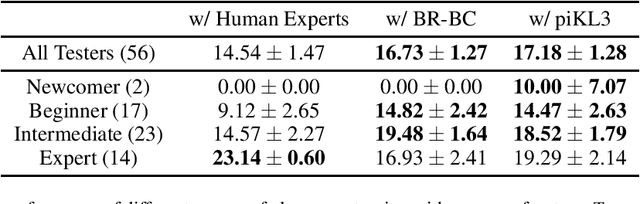
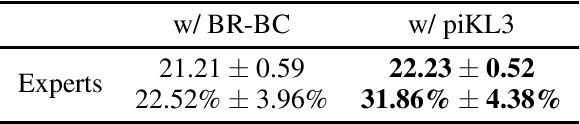
We consider the problem of making AI agents that collaborate well with humans in partially observable fully cooperative environments given datasets of human behavior. Inspired by piKL, a human-data-regularized search method that improves upon a behavioral cloning policy without diverging far away from it, we develop a three-step algorithm that achieve strong performance in coordinating with real humans in the Hanabi benchmark. We first use a regularized search algorithm and behavioral cloning to produce a better human model that captures diverse skill levels. Then, we integrate the policy regularization idea into reinforcement learning to train a human-like best response to the human model. Finally, we apply regularized search on top of the best response policy at test time to handle out-of-distribution challenges when playing with humans. We evaluate our method in two large scale experiments with humans. First, we show that our method outperforms experts when playing with a group of diverse human players in ad-hoc teams. Second, we show that our method beats a vanilla best response to behavioral cloning baseline by having experts play repeatedly with the two agents.
Efficient Heterogeneous Treatment Effect Estimation With Multiple Experiments and Multiple Outcomes
Jun 10, 2022
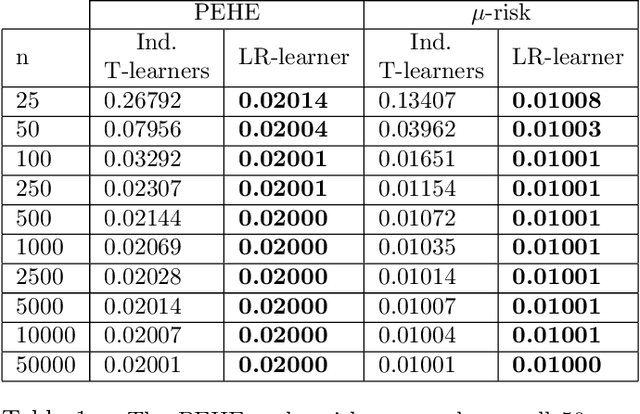
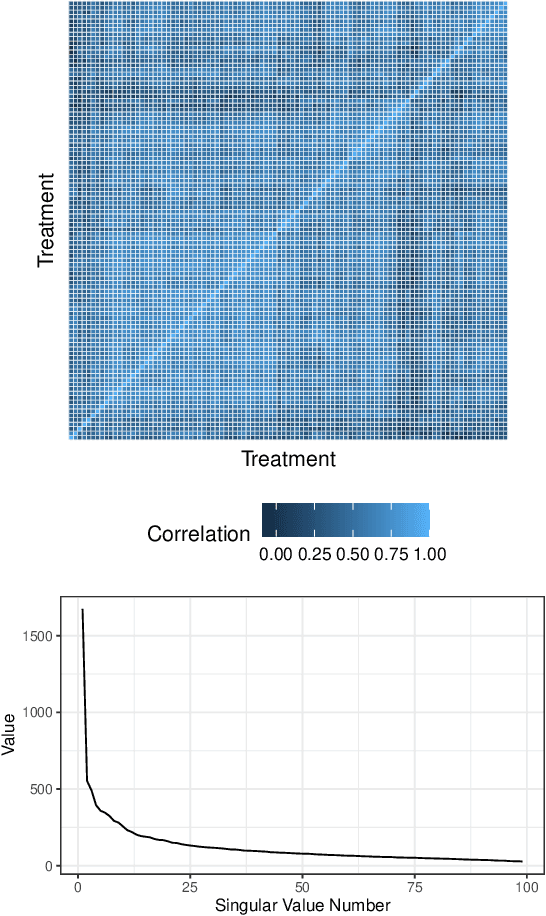
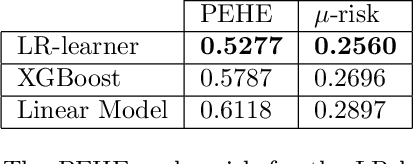
Learning heterogeneous treatment effects (HTEs) is an important problem across many fields. Most existing methods consider the setting with a single treatment arm and a single outcome metric. However, in many real world domains, experiments are run consistently - for example, in internet companies, A/B tests are run every day to measure the impacts of potential changes across many different metrics of interest. We show that even if an analyst cares only about the HTEs in one experiment for one metric, precision can be improved greatly by analyzing all of the data together to take advantage of cross-experiment and cross-outcome metric correlations. We formalize this idea in a tensor factorization framework and propose a simple and scalable model which we refer to as the low rank or LR-learner. Experiments in both synthetic and real data suggest that the LR-learner can be much more precise than independent HTE estimation.
Modeling Strong and Human-Like Gameplay with KL-Regularized Search
Dec 14, 2021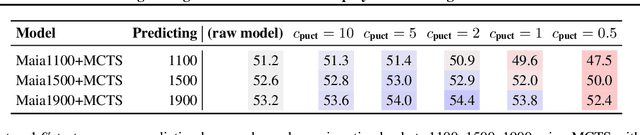
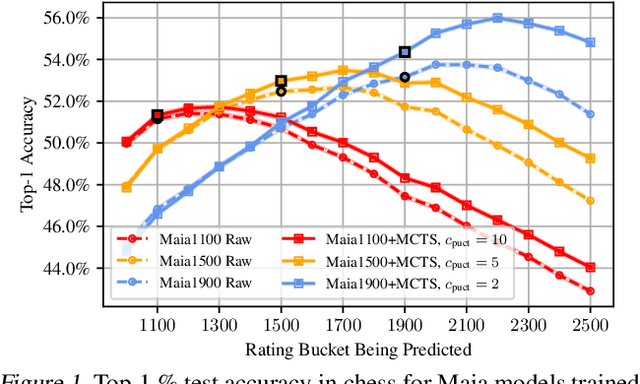

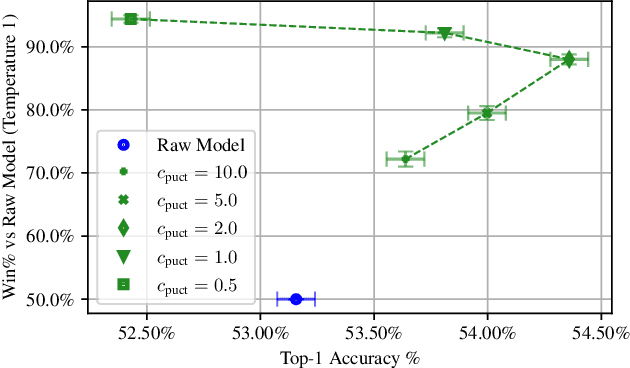
We consider the task of building strong but human-like policies in multi-agent decision-making problems, given examples of human behavior. Imitation learning is effective at predicting human actions but may not match the strength of expert humans, while self-play learning and search techniques (e.g. AlphaZero) lead to strong performance but may produce policies that are difficult for humans to understand and coordinate with. We show in chess and Go that regularizing search policies based on the KL divergence from an imitation-learned policy by applying Monte Carlo tree search produces policies that have higher human prediction accuracy and are stronger than the imitation policy. We then introduce a novel regret minimization algorithm that is regularized based on the KL divergence from an imitation-learned policy, and show that applying this algorithm to no-press Diplomacy yields a policy that maintains the same human prediction accuracy as imitation learning while being substantially stronger.
No-Press Diplomacy from Scratch
Oct 06, 2021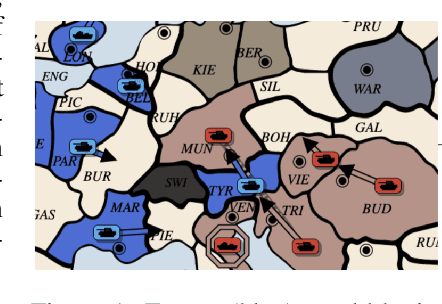


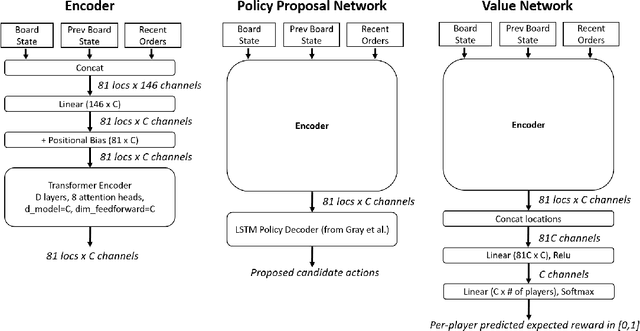
Prior AI successes in complex games have largely focused on settings with at most hundreds of actions at each decision point. In contrast, Diplomacy is a game with more than 10^20 possible actions per turn. Previous attempts to address games with large branching factors, such as Diplomacy, StarCraft, and Dota, used human data to bootstrap the policy or used handcrafted reward shaping. In this paper, we describe an algorithm for action exploration and equilibrium approximation in games with combinatorial action spaces. This algorithm simultaneously performs value iteration while learning a policy proposal network. A double oracle step is used to explore additional actions to add to the policy proposals. At each state, the target state value and policy for the model training are computed via an equilibrium search procedure. Using this algorithm, we train an agent, DORA, completely from scratch for a popular two-player variant of Diplomacy and show that it achieves superhuman performance. Additionally, we extend our methods to full-scale no-press Diplomacy and for the first time train an agent from scratch with no human data. We present evidence that this agent plays a strategy that is incompatible with human-data bootstrapped agents. This presents the first strong evidence of multiple equilibria in Diplomacy and suggests that self play alone may be insufficient for achieving superhuman performance in Diplomacy.
Learned Belief Search: Efficiently Improving Policies in Partially Observable Settings
Jun 16, 2021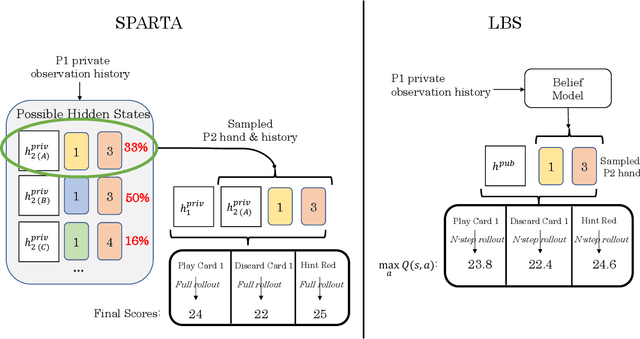

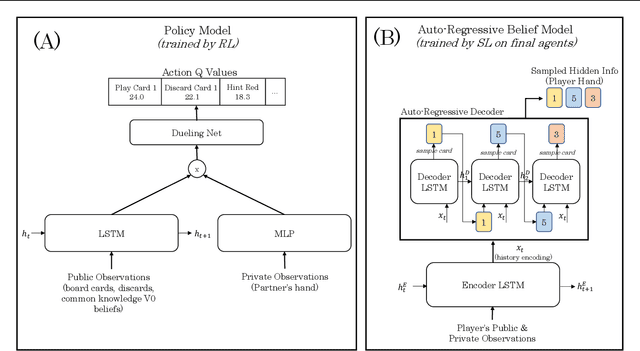
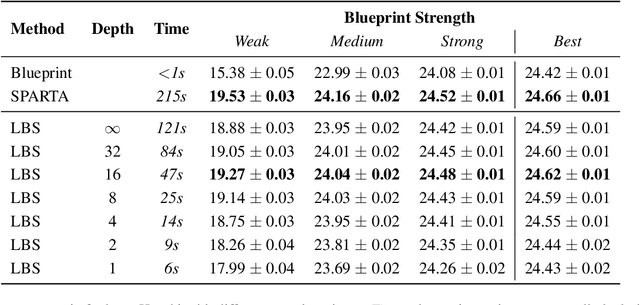
Search is an important tool for computing effective policies in single- and multi-agent environments, and has been crucial for achieving superhuman performance in several benchmark fully and partially observable games. However, one major limitation of prior search approaches for partially observable environments is that the computational cost scales poorly with the amount of hidden information. In this paper we present \emph{Learned Belief Search} (LBS), a computationally efficient search procedure for partially observable environments. Rather than maintaining an exact belief distribution, LBS uses an approximate auto-regressive counterfactual belief that is learned as a supervised task. In multi-agent settings, LBS uses a novel public-private model architecture for underlying policies in order to efficiently evaluate these policies during rollouts. In the benchmark domain of Hanabi, LBS can obtain 55% ~ 91% of the benefit of exact search while reducing compute requirements by $35.8 \times$ ~ $4.6 \times$, allowing it to scale to larger settings that were inaccessible to previous search methods.
Off-Belief Learning
Mar 06, 2021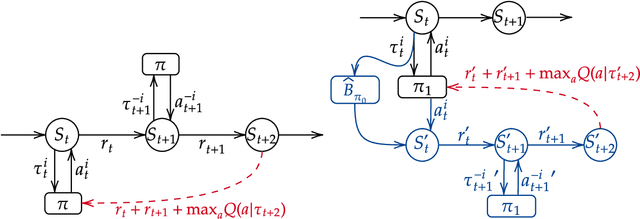
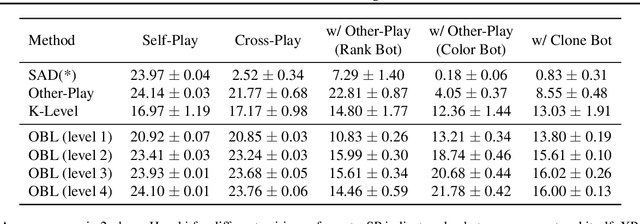
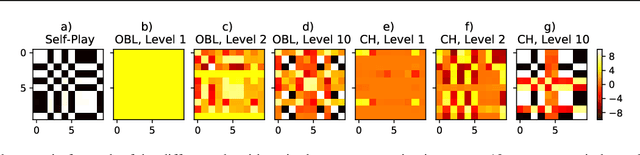

The standard problem setting in Dec-POMDPs is self-play, where the goal is to find a set of policies that play optimally together. Policies learned through self-play may adopt arbitrary conventions and rely on multi-step counterfactual reasoning based on assumptions about other agents' actions and thus fail when paired with humans or independently trained agents. In contrast, no current methods can learn optimal policies that are fully grounded, i.e., do not rely on counterfactual information from observing other agents' actions. To address this, we present off-belief learning} (OBL): at each time step OBL agents assume that all past actions were taken by a given, fixed policy ($\pi_0$), but that future actions will be taken by an optimal policy under these same assumptions. When $\pi_0$ is uniform random, OBL learns the optimal grounded policy. OBL can be iterated in a hierarchy, where the optimal policy from one level becomes the input to the next. This introduces counterfactual reasoning in a controlled manner. Unlike independent RL which may converge to any equilibrium policy, OBL converges to a unique policy, making it more suitable for zero-shot coordination. OBL can be scaled to high-dimensional settings with a fictitious transition mechanism and shows strong performance in both a simple toy-setting and the benchmark human-AI/zero-shot coordination problem Hanabi.