 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Update Equivalence Framework for Decision-Time Planning
Apr 25, 2023



The process of revising (or constructing) a policy immediately prior to execution -- known as decision-time planning -- is key to achieving superhuman performance in perfect-information settings like chess and Go. A recent line of work has extended decision-time planning to more general imperfect-information settings, leading to superhuman performance in poker. However, these methods requires considering subgames whose sizes grow quickly in the amount of non-public information, making them unhelpful when the amount of non-public information is large. Motivated by this issue, we introduce an alternative framework for decision-time planning that is not based on subgames but rather on the notion of update equivalence. In this framework, decision-time planning algorithms simulate updates of synchronous learning algorithms. This framework enables us to introduce a new family of principled decision-time planning algorithms that do not rely on public information, opening the door to sound and effective decision-time planning in settings with large amounts of non-public information. In experiments, members of this family produce comparable or superior results compared to state-of-the-art approaches in Hanabi and improve performance in 3x3 Abrupt Dark Hex and Phantom Tic-Tac-Toe.
Abstracting Imperfect Information Away from Two-Player Zero-Sum Games
Jan 22, 2023



In their seminal work, Nayyar et al. (2013) showed that imperfect information can be abstracted away from common-payoff games by having players publicly announce their policies as they play. This insight underpins sound solvers and decision-time planning algorithms for common-payoff games. Unfortunately, a naive application of the same insight to two-player zero-sum games fails because Nash equilibria of the game with public policy announcements may not correspond to Nash equilibria of the original game. As a consequence, existing sound decision-time planning algorithms require complicated additional mechanisms that have unappealing properties. The main contribution of this work is showing that certain regularized equilibria do not possess the aforementioned non-correspondence problem -- thus, computing them can be treated as perfect information problems. Because these regularized equilibria can be made arbitrarily close to Nash equilibria, our result opens the door to a new perspective on solving two-player zero-sum games and, in particular, yields a simplified framework for decision-time planning in two-player zero-sum games, void of the unappealing properties that plague existing decision-time planning approaches.
Modeling Strong and Human-Like Gameplay with KL-Regularized Search
Dec 14, 2021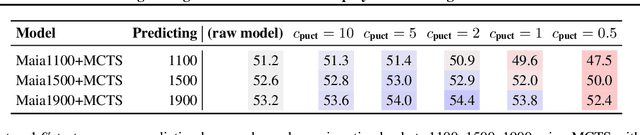
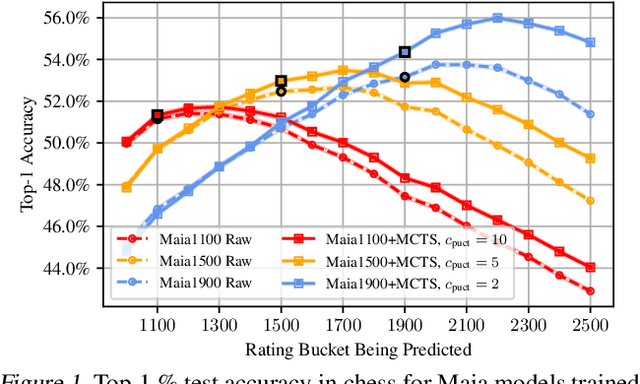

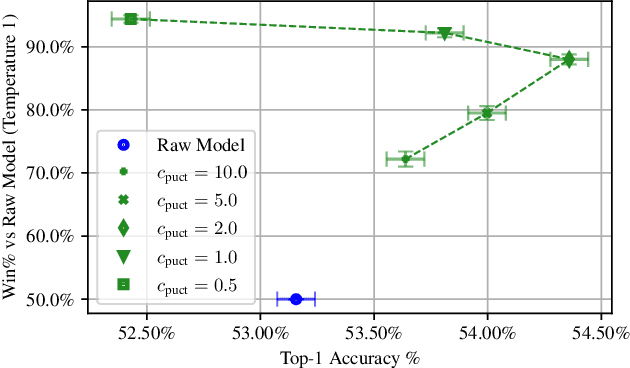
We consider the task of building strong but human-like policies in multi-agent decision-making problems, given examples of human behavior. Imitation learning is effective at predicting human actions but may not match the strength of expert humans, while self-play learning and search techniques (e.g. AlphaZero) lead to strong performance but may produce policies that are difficult for humans to understand and coordinate with. We show in chess and Go that regularizing search policies based on the KL divergence from an imitation-learned policy by applying Monte Carlo tree search produces policies that have higher human prediction accuracy and are stronger than the imitation policy. We then introduce a novel regret minimization algorithm that is regularized based on the KL divergence from an imitation-learned policy, and show that applying this algorithm to no-press Diplomacy yields a policy that maintains the same human prediction accuracy as imitation learning while being substantially stronger.
CryptGPU: Fast Privacy-Preserving Machine Learning on the GPU
Apr 22, 2021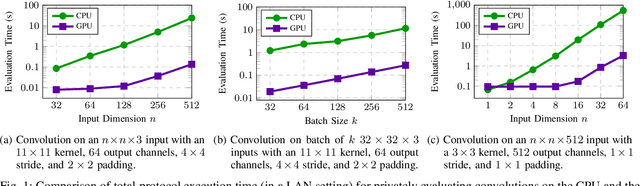
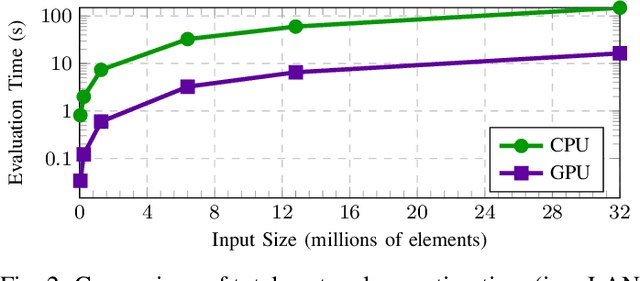
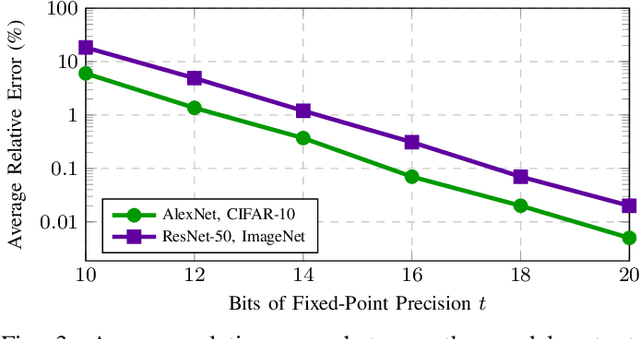
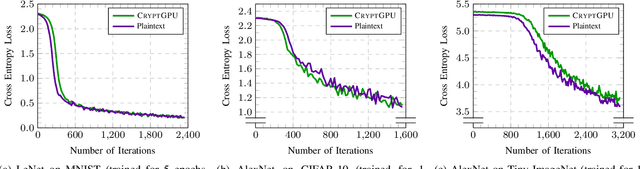
We introduce CryptGPU, a system for privacy-preserving machine learning that implements all operations on the GPU (graphics processing unit). Just as GPUs played a pivotal role in the success of modern deep learning, they are also essential for realizing scalable privacy-preserving deep learning. In this work, we start by introducing a new interface to losslessly embed cryptographic operations over secret-shared values (in a discrete domain) into floating-point operations that can be processed by highly-optimized CUDA kernels for linear algebra. We then identify a sequence of "GPU-friendly" cryptographic protocols to enable privacy-preserving evaluation of both linear and non-linear operations on the GPU. Our microbenchmarks indicate that our private GPU-based convolution protocol is over 150x faster than the analogous CPU-based protocol; for non-linear operations like the ReLU activation function, our GPU-based protocol is around 10x faster than its CPU analog. With CryptGPU, we support private inference and private training on convolutional neural networks with over 60 million parameters as well as handle large datasets like ImageNet. Compared to the previous state-of-the-art, when considering large models and datasets, our protocols achieve a 2x to 8x improvement in private inference and a 6x to 36x improvement for private training. Our work not only showcases the viability of performing secure multiparty computation (MPC) entirely on the GPU to enable fast privacy-preserving machine learning, but also highlights the importance of designing new MPC primitives that can take full advantage of the GPU's computing capabilities.
Accelerating Self-Play Learning in Go
Mar 01, 2019
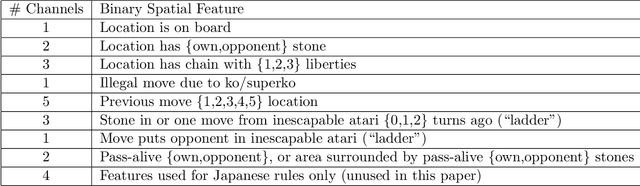


By introducing several new Go-specific and non-Go-specific techniques along with other tuning, we accelerate self-play learning in Go. Like AlphaZero and Leela Zero, a popular open-source distributed project based on AlphaZero, our bot KataGo only learns from neural net Monte-Carlo tree-search self-play. With our techniques, in only a week with several dozen GPUs it achieves a likely strong pro or perhaps just-super-human level of strength. Compared to Leela Zero, we estimate a roughly 5x reduction in self-play computation required to achieve that level of strength, as well as a 30x to 100x reduction for reaching moderate to strong amateur levels. Although we so far have not tested in longer runs, we believe that our techniques hold promise for future research.