 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGame of Thought: Robust Information Seeking with Large Language Models Using Game Theory
Feb 02, 2026Large Language Models (LLMs) are increasingly deployed in real-world scenarios where they may lack sufficient information to complete a given task. In such settings, the ability to actively seek out missing information becomes a critical capability. Existing approaches to enhancing this ability often rely on simplifying assumptions that degrade \textit{worst-case} performance. This is an issue with serious implications in high-stakes applications. In this work, we use the game of Twenty Questions to evaluate the information-seeking ability of LLMs. We introduce and formalize its adversarial counterpart, the Strategic Language Search (SLS) problem along with its variants as a two-player zero-sum extensive form game. We propose Game of Thought (GoT), a framework that applies game-theoretic techniques to approximate a Nash equilibrium (NE) strategy for the restricted variant of the game. Empirical results demonstrate that our approach consistently improves worst-case performance compared to (1) direct prompting-based methods and (2) heuristic-guided search methods across all tested settings.
DDPS: Discrete Diffusion Posterior Sampling for Paths in Layered Graphs
Apr 29, 2025Diffusion models form an important class of generative models today, accounting for much of the state of the art in cutting edge AI research. While numerous extensions beyond image and video generation exist, few of such approaches address the issue of explicit constraints in the samples generated. In this paper, we study the problem of generating paths in a layered graph (a variant of a directed acyclic graph) using discrete diffusion models, while guaranteeing that our generated samples are indeed paths. Our approach utilizes a simple yet effective representation for paths which we call the padded adjacency-list matrix (PALM). In addition, we show how to effectively perform classifier guidance, which helps steer the sampled paths to specific preferred edges without any retraining of the diffusion model. Our preliminary results show that empirically, our method outperforms alternatives which do not explicitly account for path constraints.
Online bipartite matching with imperfect advice
May 16, 2024



We study the problem of online unweighted bipartite matching with $n$ offline vertices and $n$ online vertices where one wishes to be competitive against the optimal offline algorithm. While the classic RANKING algorithm of Karp et al. [1990] provably attains competitive ratio of $1-1/e > 1/2$, we show that no learning-augmented method can be both 1-consistent and strictly better than $1/2$-robust under the adversarial arrival model. Meanwhile, under the random arrival model, we show how one can utilize methods from distribution testing to design an algorithm that takes in external advice about the online vertices and provably achieves competitive ratio interpolating between any ratio attainable by advice-free methods and the optimal ratio of 1, depending on the advice quality.
Deep Copula-Based Survival Analysis for Dependent Censoring with Identifiability Guarantees
Dec 27, 2023Censoring is the central problem in survival analysis where either the time-to-event (for instance, death), or the time-tocensoring (such as loss of follow-up) is observed for each sample. The majority of existing machine learning-based survival analysis methods assume that survival is conditionally independent of censoring given a set of covariates; an assumption that cannot be verified since only marginal distributions is available from the data. The existence of dependent censoring, along with the inherent bias in current estimators has been demonstrated in a variety of applications, accentuating the need for a more nuanced approach. However, existing methods that adjust for dependent censoring require practitioners to specify the ground truth copula. This requirement poses a significant challenge for practical applications, as model misspecification can lead to substantial bias. In this work, we propose a flexible deep learning-based survival analysis method that simultaneously accommodate for dependent censoring and eliminates the requirement for specifying the ground truth copula. We theoretically prove the identifiability of our model under a broad family of copulas and survival distributions. Experiments results from a wide range of datasets demonstrate that our approach successfully discerns the underlying dependency structure and significantly reduces survival estimation bias when compared to existing methods.
Multi-defender Security Games with Schedules
Nov 28, 2023



Stackelberg Security Games are often used to model strategic interactions in high-stakes security settings. The majority of existing models focus on single-defender settings where a single entity assumes command of all security assets. However, many realistic scenarios feature multiple heterogeneous defenders with their own interests and priorities embedded in a more complex system. Furthermore, defenders rarely choose targets to protect. Instead, they have a multitude of defensive resources or schedules at its disposal, each with different protective capabilities. In this paper, we study security games featuring multiple defenders and schedules simultaneously. We show that unlike prior work on multi-defender security games, the introduction of schedules can cause non-existence of equilibrium even under rather restricted environments. We prove that under the mild restriction that any subset of a schedule is also a schedule, non-existence of equilibrium is not only avoided, but can be computed in polynomial time in games with two defenders. Under additional assumptions, our algorithm can be extended to games with more than two defenders and its computation scaled up in special classes of games with compactly represented schedules such as those used in patrolling applications. Experimental results suggest that our methods scale gracefully with game size, making our algorithms amongst the few that can tackle multiple heterogeneous defenders.
Multimodal Learning Without Labeled Multimodal Data: Guarantees and Applications
Jun 07, 2023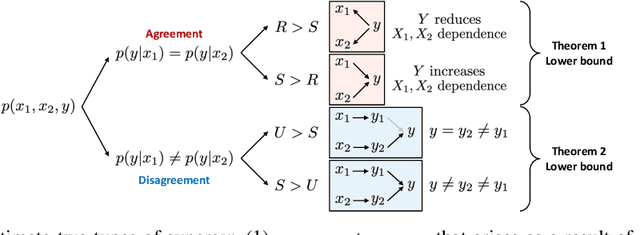
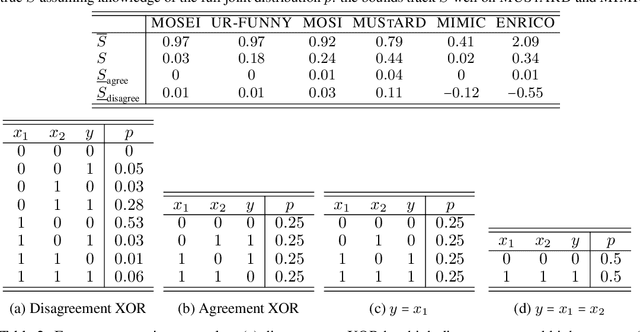
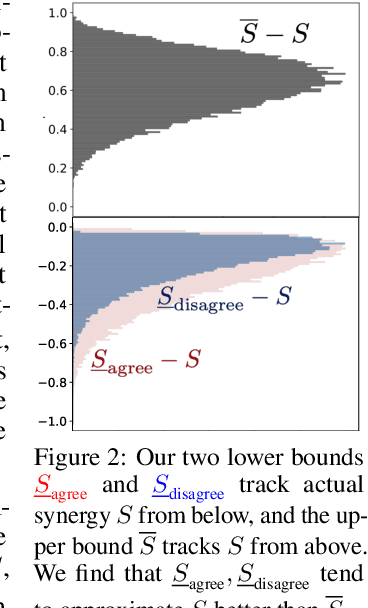
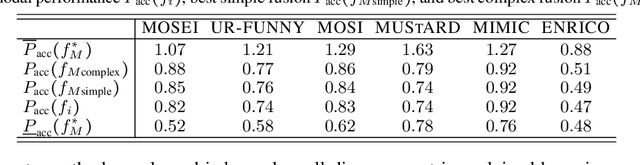
In many machine learning systems that jointly learn from multiple modalities, a core research question is to understand the nature of multimodal interactions: the emergence of new task-relevant information during learning from both modalities that was not present in either alone. We study this challenge of interaction quantification in a semi-supervised setting with only labeled unimodal data and naturally co-occurring multimodal data (e.g., unlabeled images and captions, video and corresponding audio) but when labeling them is time-consuming. Using a precise information-theoretic definition of interactions, our key contributions are the derivations of lower and upper bounds to quantify the amount of multimodal interactions in this semi-supervised setting. We propose two lower bounds based on the amount of shared information between modalities and the disagreement between separately trained unimodal classifiers, and derive an upper bound through connections to approximate algorithms for min-entropy couplings. We validate these estimated bounds and show how they accurately track true interactions. Finally, two semi-supervised multimodal applications are explored based on these theoretical results: (1) analyzing the relationship between multimodal performance and estimated interactions, and (2) self-supervised learning that embraces disagreement between modalities beyond agreement as is typically done.
Quantifying & Modeling Feature Interactions: An Information Decomposition Framework
Feb 23, 2023The recent explosion of interest in multimodal applications has resulted in a wide selection of datasets and methods for representing and integrating information from different signals. Despite these empirical advances, there remain fundamental research questions: how can we quantify the nature of interactions that exist among input features? Subsequently, how can we capture these interactions using suitable data-driven methods? To answer this question, we propose an information-theoretic approach to quantify the degree of redundancy, uniqueness, and synergy across input features, which we term the PID statistics of a multimodal distribution. Using 2 newly proposed estimators that scale to high-dimensional distributions, we demonstrate their usefulness in quantifying the interactions within multimodal datasets, the nature of interactions captured by multimodal models, and principled approaches for model selection. We conduct extensive experiments on both synthetic datasets where the PID statistics are known and on large-scale multimodal benchmarks where PID estimation was previously impossible. Finally, to demonstrate the real-world applicability of our approach, we present three case studies in pathology, mood prediction, and robotic perception where our framework accurately recommends strong multimodal models for each application.
Abstracting Imperfect Information Away from Two-Player Zero-Sum Games
Jan 22, 2023



In their seminal work, Nayyar et al. (2013) showed that imperfect information can be abstracted away from common-payoff games by having players publicly announce their policies as they play. This insight underpins sound solvers and decision-time planning algorithms for common-payoff games. Unfortunately, a naive application of the same insight to two-player zero-sum games fails because Nash equilibria of the game with public policy announcements may not correspond to Nash equilibria of the original game. As a consequence, existing sound decision-time planning algorithms require complicated additional mechanisms that have unappealing properties. The main contribution of this work is showing that certain regularized equilibria do not possess the aforementioned non-correspondence problem -- thus, computing them can be treated as perfect information problems. Because these regularized equilibria can be made arbitrarily close to Nash equilibria, our result opens the door to a new perspective on solving two-player zero-sum games and, in particular, yields a simplified framework for decision-time planning in two-player zero-sum games, void of the unappealing properties that plague existing decision-time planning approaches.
Function Approximation for Solving Stackelberg Equilibrium in Large Perfect Information Games
Dec 29, 2022Function approximation (FA) has been a critical component in solving large zero-sum games. Yet, little attention has been given towards FA in solving \textit{general-sum} extensive-form games, despite them being widely regarded as being computationally more challenging than their fully competitive or cooperative counterparts. A key challenge is that for many equilibria in general-sum games, no simple analogue to the state value function used in Markov Decision Processes and zero-sum games exists. In this paper, we propose learning the \textit{Enforceable Payoff Frontier} (EPF) -- a generalization of the state value function for general-sum games. We approximate the optimal \textit{Stackelberg extensive-form correlated equilibrium} by representing EPFs with neural networks and training them by using appropriate backup operations and loss functions. This is the first method that applies FA to the Stackelberg setting, allowing us to scale to much larger games while still enjoying performance guarantees based on FA error. Additionally, our proposed method guarantees incentive compatibility and is easy to evaluate without having to depend on self-play or approximate best-response oracles.
Safe Subgame Resolving for Extensive Form Correlated Equilibrium
Dec 29, 2022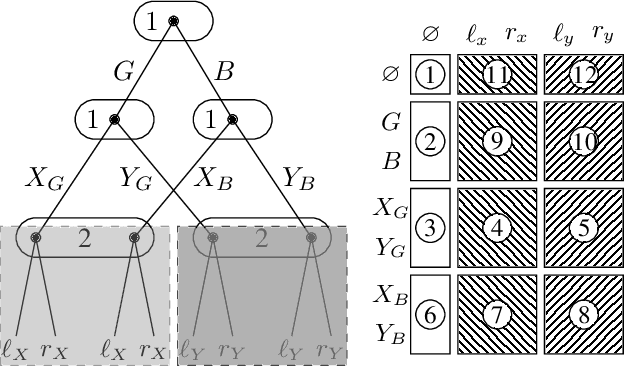

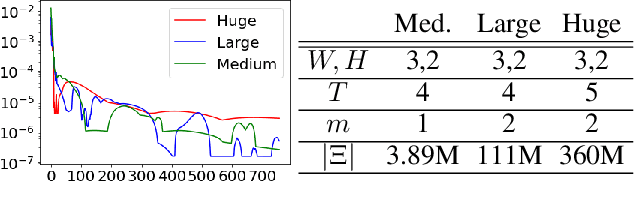
Correlated Equilibrium is a solution concept that is more general than Nash Equilibrium (NE) and can lead to outcomes with better social welfare. However, its natural extension to the sequential setting, the \textit{Extensive Form Correlated Equilibrium} (EFCE), requires a quadratic amount of space to solve, even in restricted settings without randomness in nature. To alleviate these concerns, we apply \textit{subgame resolving}, a technique extremely successful in finding NE in zero-sum games to solving general-sum EFCEs. Subgame resolving refines a correlation plan in an \textit{online} manner: instead of solving for the full game upfront, it only solves for strategies in subgames that are reached in actual play, resulting in significant computational gains. In this paper, we (i) lay out the foundations to quantify the quality of a refined strategy, in terms of the \textit{social welfare} and \textit{exploitability} of correlation plans, (ii) show that EFCEs possess a sufficient amount of independence between subgames to perform resolving efficiently, and (iii) provide two algorithms for resolving, one using linear programming and the other based on regret minimization. Both methods guarantee \textit{safety}, i.e., they will never be counterproductive. Our methods are the first time an online method has been applied to the correlated, general-sum setting.