 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree-of-Experience: A Structured Experience-Management Solution for Self-Evolving Agents under Low-Repetition and Implicit-Reward Environments
Jun 05, 2026Experience-based self-evolution is crucial for LLM agents, but existing benchmarks often assume explicit goals, stable task patterns, and clear feedback. We study a more challenging setting: low-repetition tasks with implicit rewards, where past experience is difficult to reuse and feedback is delayed, noisy, and outcome-level. We introduce \textsc{FinEvolveBench}, a temporally controlled benchmark for financial sentiment prediction that links daily news-driven predictions to future excess returns. We further propose Tree-of-Experience (ToE), a structured experience-management method that organizes, retrieves, validates, and updates agent experience. Experiments show that general-purpose experience mechanisms do not consistently outperform no-experience baselines, while ToE achieves stronger overall performance. These results highlight the importance of structured experience management for self-evolving agents in implicit-reward environments.
NL2CA: Auto-formalizing Cognitive Decision-Making from Natural Language Using an Unsupervised CriticNL2LTL Framework
Dec 20, 2025



Cognitive computing models offer a formal and interpretable way to characterize human's deliberation and decision-making, yet their development remains labor-intensive. In this paper, we propose NL2CA, a novel method for auto-formalizing cognitive decision-making rules from natural language descriptions of human experience. Different from most related work that exploits either pure manual or human guided interactive modeling, our method is fully automated without any human intervention. The approach first translates text into Linear Temporal Logic (LTL) using a fine-tuned large language model (LLM), then refines the logic via an unsupervised Critic Tree, and finally transforms the output into executable production rules compatible with symbolic cognitive frameworks. Based on the resulted rules, a cognitive agent is further constructed and optimized through cognitive reinforcement learning according to the real-world behavioral data. Our method is validated in two domains: (1) NL-to-LTL translation, where our CriticNL2LTL module achieves consistent performance across both expert and large-scale benchmarks without human-in-the-loop feed-backs, and (2) cognitive driving simulation, where agents automatically constructed from human interviews have successfully learned the diverse decision patterns of about 70 trials in different critical scenarios. Experimental results demonstrate that NL2CA enables scalable, interpretable, and human-aligned cognitive modeling from unstructured textual data, offering a novel paradigm to automatically design symbolic cognitive agents.
MMSearch-R1: Incentivizing LMMs to Search
Jun 25, 2025



Robust deployment of large multimodal models (LMMs) in real-world scenarios requires access to external knowledge sources, given the complexity and dynamic nature of real-world information. Existing approaches such as retrieval-augmented generation (RAG) and prompt engineered search agents rely on rigid pipelines, often leading to inefficient or excessive search behaviors. We present MMSearch-R1, the first end-to-end reinforcement learning framework that enables LMMs to perform on-demand, multi-turn search in real-world Internet environments. Our framework integrates both image and text search tools, allowing the model to reason about when and how to invoke them guided by an outcome-based reward with a search penalty. To support training, We collect a multimodal search VQA dataset through a semi-automated pipeline that covers diverse visual and textual knowledge needs and curate a search-balanced subset with both search-required and search-free samples, which proves essential for shaping efficient and on-demand search behavior. Extensive experiments on knowledge-intensive and info-seeking VQA tasks show that our model not only outperforms RAG-based baselines of the same model size, but also matches the performance of a larger RAG-based model while reducing search calls by over 30%. We further analyze key empirical findings to offer actionable insights for advancing research in multimodal search.
Towards Safe and Robust Autonomous Vehicle Platooning: A Self-Organizing Cooperative Control Framework
Aug 18, 2024



In the emerging hybrid traffic flow environment, which includes both human-driven vehicles (HDVs) and autonomous vehicles (AVs), ensuring safe and robust decision-making and control is crucial for the effective operation of autonomous vehicle platooning. Current systems for cooperative adaptive cruise control and lane changing are inadequate in responding to real-world emergency situations, limiting the potential of autonomous vehicle platooning technology. To address the aforementioned challenges, we propose a Twin-World Safety-Enhanced Data-Model-Knowledge Hybrid-Driven autonomous vehicle platooning Cooperative Control Framework. Within this framework, a deep reinforcement learning formation decision model integrating traffic priors is designed, and a twin-world deduction model based on safety priority judgment is proposed. Subsequently, an optimal control-based multi-scenario decision-control right adaptive switching mechanism is designed to achieve adaptive switching between data-driven and model-driven methods. Through simulation experiments and hardware-in-loop tests, our algorithm has demonstrated excellent performance in terms of safety, robustness, and flexibility. A detailed account of the validation results for the model can be found in \url{https://perfectxu88.github.io/towardssafeandrobust.github.io/}.
Multi-Robot Collaborative Navigation with Formation Adaptation
Apr 02, 2024


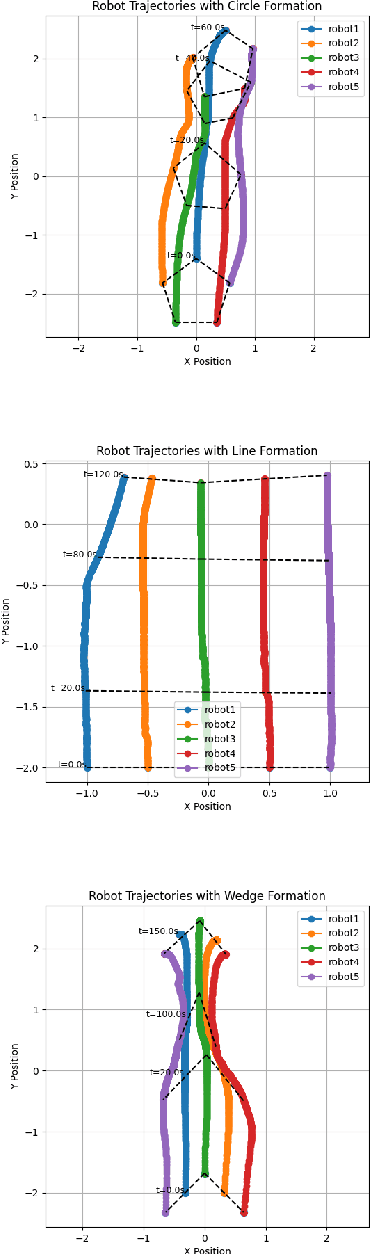
Multi-robot collaborative navigation is an essential ability where teamwork and synchronization are keys. In complex and uncertain environments, adaptive formation is vital, as rigid formations prove to be inadequate. The ability of robots to dynamically adjust their formation enables navigation through unpredictable spaces, maintaining cohesion, and effectively responding to environmental challenges. In this paper, we introduce a novel approach that uses bi-level learning framework. Specifically, we use graph learning at a high level for group coordination and reinforcement learning for individual navigation. We innovate by integrating a spring-damper model within the reinforcement learning reward mechanism, addressing the rigidity of traditional formation control methods. During execution, our approach enables a team of robots to successfully navigate challenging environments, maintain a desired formation shape, and dynamically adjust their formation scale based on environmental information. We conduct extensive experiments to evaluate our approach across three distinct formation scenarios in multi-robot navigation: circle, line, and wedge. Experimental results show that our approach achieves promising results and scalability on multi-robot navigation with formation adaptation.
Enhancing Cross-Category Learning in Recommendation Systems with Multi-Layer Embedding Training
Sep 27, 2023



Modern DNN-based recommendation systems rely on training-derived embeddings of sparse features. Input sparsity makes obtaining high-quality embeddings for rarely-occurring categories harder as their representations are updated infrequently. We demonstrate a training-time technique to produce superior embeddings via effective cross-category learning and theoretically explain its surprising effectiveness. The scheme, termed the multi-layer embeddings training (MLET), trains embeddings using factorization of the embedding layer, with an inner dimension higher than the target embedding dimension. For inference efficiency, MLET converts the trained two-layer embedding into a single-layer one thus keeping inference-time model size unchanged. Empirical superiority of MLET is puzzling as its search space is not larger than that of the single-layer embedding. The strong dependence of MLET on the inner dimension is even more surprising. We develop a theory that explains both of these behaviors by showing that MLET creates an adaptive update mechanism modulated by the singular vectors of embeddings. When tested on multiple state-of-the-art recommendation models for click-through rate (CTR) prediction tasks, MLET consistently produces better models, especially for rare items. At constant model quality, MLET allows embedding dimension, and model size, reduction by up to 16x, and 5.8x on average, across the models.
MusiLingo: Bridging Music and Text with Pre-trained Language Models for Music Captioning and Query Response
Sep 15, 2023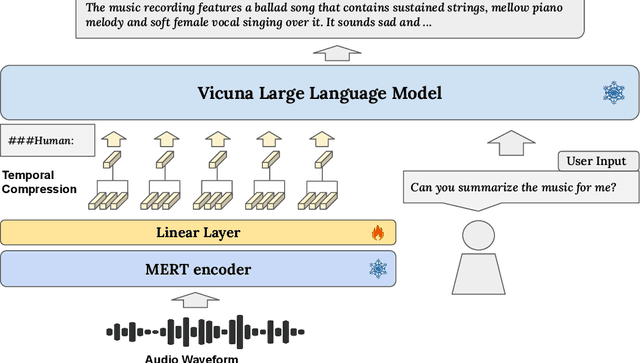
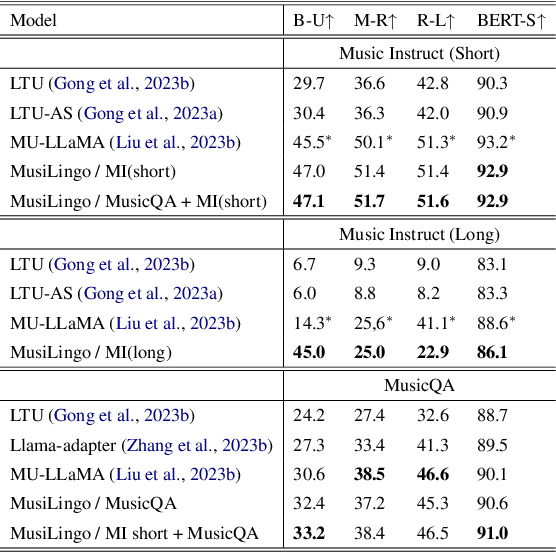
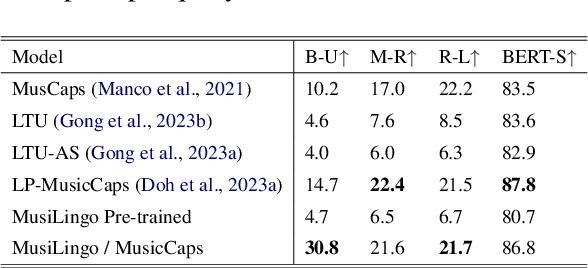
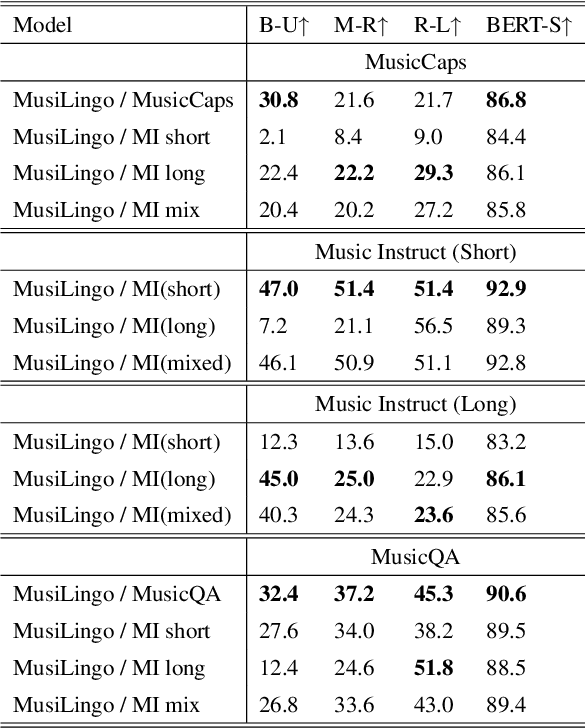
Large Language Models (LLMs) have shown immense potential in multimodal applications, yet the convergence of textual and musical domains remains relatively unexplored. To address this gap, we present MusiLingo, a novel system for music caption generation and music-related query responses. MusiLingo employs a single projection layer to align music representations from the pre-trained frozen music audio model MERT with the frozen LLaMA language model, bridging the gap between music audio and textual contexts. We train it on an extensive music caption dataset and fine-tune it with instructional data. Due to the scarcity of high-quality music Q&A datasets, we created the MusicInstruct (MI) dataset from MusicCaps, tailored for open-ended music inquiries. Empirical evaluations demonstrate its competitive performance in generating music captions and composing music-related Q&A pairs. Our introduced dataset enables notable advancements beyond previous ones.
Mixed-Precision Quantization with Cross-Layer Dependencies
Jul 11, 2023



Quantization is commonly used to compress and accelerate deep neural networks. Quantization assigning the same bit-width to all layers leads to large accuracy degradation at low precision and is wasteful at high precision settings. Mixed-precision quantization (MPQ) assigns varied bit-widths to layers to optimize the accuracy-efficiency trade-off. Existing methods simplify the MPQ problem by assuming that quantization errors at different layers act independently. We show that this assumption does not reflect the true behavior of quantized deep neural networks. We propose the first MPQ algorithm that captures the cross-layer dependency of quantization error. Our algorithm (CLADO) enables a fast approximation of pairwise cross-layer error terms by solving linear equations that require only forward evaluations of the network on a small amount of data. Decisions on layerwise bit-width assignments are then determined by optimizing a new MPQ formulation dependent on these cross-layer quantization errors via the Integer Quadratic Program (IQP), which can be solved within seconds. We conduct experiments on multiple networks on the Imagenet dataset and demonstrate an improvement, in top-1 classification accuracy, of up to 27% over uniform precision quantization, and up to 15% over existing MPQ methods.
Factorized Contrastive Learning: Going Beyond Multi-view Redundancy
Jun 08, 2023



In a wide range of multimodal tasks, contrastive learning has become a particularly appealing approach since it can successfully learn representations from abundant unlabeled data with only pairing information (e.g., image-caption or video-audio pairs). Underpinning these approaches is the assumption of multi-view redundancy - that shared information between modalities is necessary and sufficient for downstream tasks. However, in many real-world settings, task-relevant information is also contained in modality-unique regions: information that is only present in one modality but still relevant to the task. How can we learn self-supervised multimodal representations to capture both shared and unique information relevant to downstream tasks? This paper proposes FactorCL, a new multimodal representation learning method to go beyond multi-view redundancy. FactorCL is built from three new contributions: (1) factorizing task-relevant information into shared and unique representations, (2) capturing task-relevant information via maximizing MI lower bounds and removing task-irrelevant information via minimizing MI upper bounds, and (3) multimodal data augmentations to approximate task relevance without labels. On large-scale real-world datasets, FactorCL captures both shared and unique information and achieves state-of-the-art results on six benchmarks.
Quantifying & Modeling Feature Interactions: An Information Decomposition Framework
Feb 23, 2023The recent explosion of interest in multimodal applications has resulted in a wide selection of datasets and methods for representing and integrating information from different signals. Despite these empirical advances, there remain fundamental research questions: how can we quantify the nature of interactions that exist among input features? Subsequently, how can we capture these interactions using suitable data-driven methods? To answer this question, we propose an information-theoretic approach to quantify the degree of redundancy, uniqueness, and synergy across input features, which we term the PID statistics of a multimodal distribution. Using 2 newly proposed estimators that scale to high-dimensional distributions, we demonstrate their usefulness in quantifying the interactions within multimodal datasets, the nature of interactions captured by multimodal models, and principled approaches for model selection. We conduct extensive experiments on both synthetic datasets where the PID statistics are known and on large-scale multimodal benchmarks where PID estimation was previously impossible. Finally, to demonstrate the real-world applicability of our approach, we present three case studies in pathology, mood prediction, and robotic perception where our framework accurately recommends strong multimodal models for each application.