 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKolmogorov Arnold Networks and Multi-Layer Perceptrons: A Paradigm Shift in Neural Modelling
Jan 15, 2026The research undertakes a comprehensive comparative analysis of Kolmogorov-Arnold Networks (KAN) and Multi-Layer Perceptrons (MLP), highlighting their effectiveness in solving essential computational challenges like nonlinear function approximation, time-series prediction, and multivariate classification. Rooted in Kolmogorov's representation theorem, KANs utilize adaptive spline-based activation functions and grid-based structures, providing a transformative approach compared to traditional neural network frameworks. Utilizing a variety of datasets spanning mathematical function estimation (quadratic and cubic) to practical uses like predicting daily temperatures and categorizing wines, the proposed research thoroughly assesses model performance via accuracy measures like Mean Squared Error (MSE) and computational expense assessed through Floating Point Operations (FLOPs). The results indicate that KANs reliably exceed MLPs in every benchmark, attaining higher predictive accuracy with significantly reduced computational costs. Such an outcome highlights their ability to maintain a balance between computational efficiency and accuracy, rendering them especially beneficial in resource-limited and real-time operational environments. By elucidating the architectural and functional distinctions between KANs and MLPs, the paper provides a systematic framework for selecting the most suitable neural architectures for specific tasks. Furthermore, the proposed study highlights the transformative capabilities of KANs in progressing intelligent systems, influencing their use in situations that require both interpretability and computational efficiency.
Approximately Aligned Decoding
Oct 01, 2024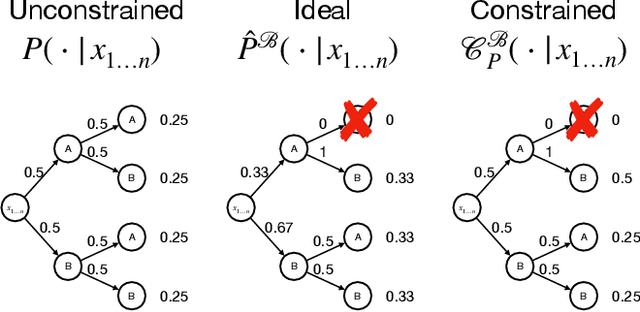
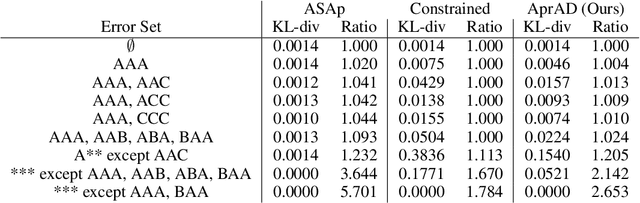

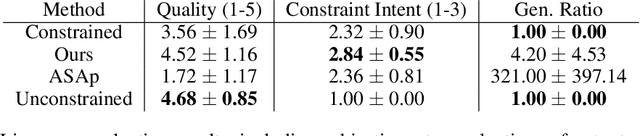
It is common to reject undesired outputs of Large Language Models (LLMs); however, current methods to do so require an excessive amount of computation, or severely distort the distribution of outputs. We present a method to balance the distortion of the output distribution with computational efficiency, allowing for the generation of long sequences of text with difficult-to-satisfy constraints, with less amplification of low probability outputs compared to existing methods. We show through a series of experiments that the task-specific performance of our method is comparable to methods that do not distort the output distribution, while being much more computationally efficient.
On Mitigating Code LLM Hallucinations with API Documentation
Jul 13, 2024



In this study, we address the issue of API hallucinations in various software engineering contexts. We introduce CloudAPIBench, a new benchmark designed to measure API hallucination occurrences. CloudAPIBench also provides annotations for frequencies of API occurrences in the public domain, allowing us to study API hallucinations at various frequency levels. Our findings reveal that Code LLMs struggle with low frequency APIs: for e.g., GPT-4o achieves only 38.58% valid low frequency API invocations. We demonstrate that Documentation Augmented Generation (DAG) significantly improves performance for low frequency APIs (increase to 47.94% with DAG) but negatively impacts high frequency APIs when using sub-optimal retrievers (a 39.02% absolute drop). To mitigate this, we propose to intelligently trigger DAG where we check against an API index or leverage Code LLMs' confidence scores to retrieve only when needed. We demonstrate that our proposed methods enhance the balance between low and high frequency API performance, resulting in more reliable API invocations (8.20% absolute improvement on CloudAPIBench for GPT-4o).
CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion
Oct 17, 2023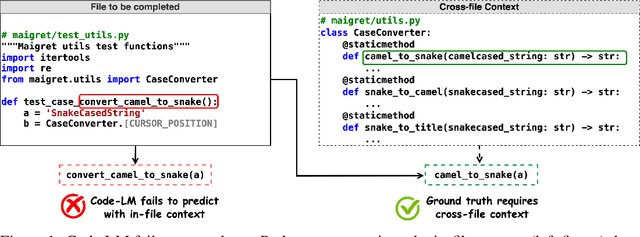
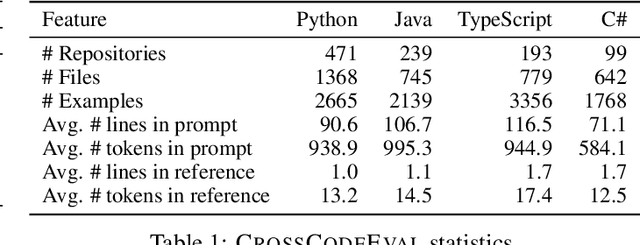
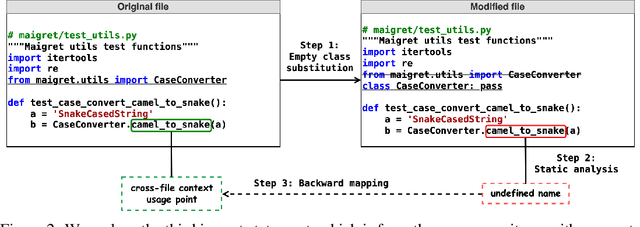
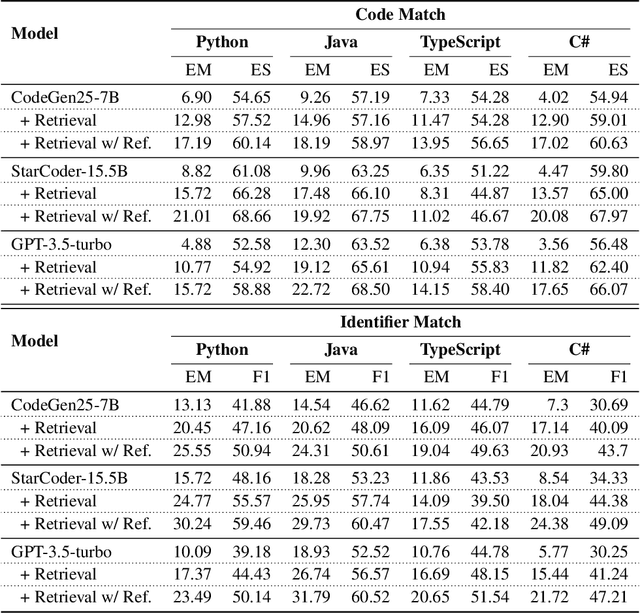
Code completion models have made significant progress in recent years, yet current popular evaluation datasets, such as HumanEval and MBPP, predominantly focus on code completion tasks within a single file. This over-simplified setting falls short of representing the real-world software development scenario where repositories span multiple files with numerous cross-file dependencies, and accessing and understanding cross-file context is often required to complete the code correctly. To fill in this gap, we propose CrossCodeEval, a diverse and multilingual code completion benchmark that necessitates an in-depth cross-file contextual understanding to complete the code accurately. CrossCodeEval is built on a diverse set of real-world, open-sourced, permissively-licensed repositories in four popular programming languages: Python, Java, TypeScript, and C#. To create examples that strictly require cross-file context for accurate completion, we propose a straightforward yet efficient static-analysis-based approach to pinpoint the use of cross-file context within the current file. Extensive experiments on state-of-the-art code language models like CodeGen and StarCoder demonstrate that CrossCodeEval is extremely challenging when the relevant cross-file context is absent, and we see clear improvements when adding these context into the prompt. However, despite such improvements, the pinnacle of performance remains notably unattained even with the highest-performing model, indicating that CrossCodeEval is also capable of assessing model's capability in leveraging extensive context to make better code completion. Finally, we benchmarked various methods in retrieving cross-file context, and show that CrossCodeEval can also be used to measure the capability of code retrievers.
Self-supervised Multi-view Disentanglement for Expansion of Visual Collections
Feb 04, 2023

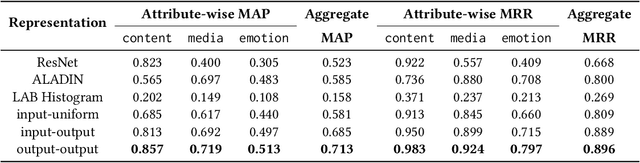
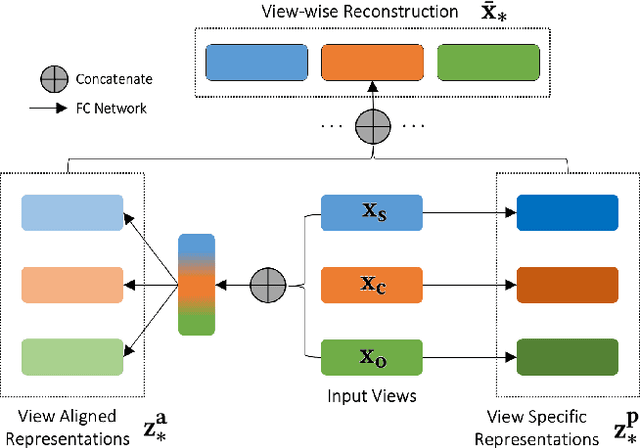
Image search engines enable the retrieval of images relevant to a query image. In this work, we consider the setting where a query for similar images is derived from a collection of images. For visual search, the similarity measurements may be made along multiple axes, or views, such as style and color. We assume access to a set of feature extractors, each of which computes representations for a specific view. Our objective is to design a retrieval algorithm that effectively combines similarities computed over representations from multiple views. To this end, we propose a self-supervised learning method for extracting disentangled view-specific representations for images such that the inter-view overlap is minimized. We show how this allows us to compute the intent of a collection as a distribution over views. We show how effective retrieval can be performed by prioritizing candidate expansion images that match the intent of a query collection. Finally, we present a new querying mechanism for image search enabled by composing multiple collections and perform retrieval under this setting using the techniques presented in this paper.
ContraGen: Effective Contrastive Learning For Causal Language Model
Oct 03, 2022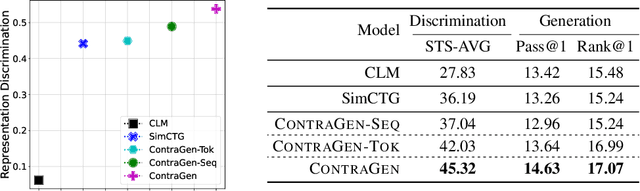
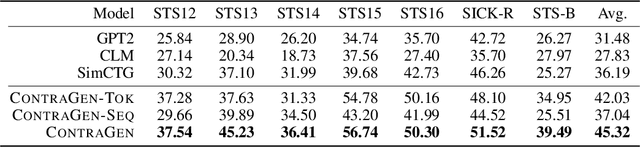
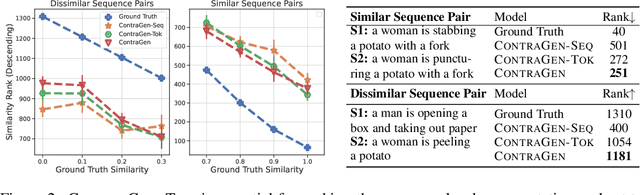
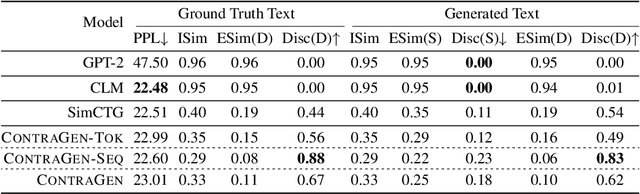
Despite exciting progress in large-scale language generation, the expressiveness of its representations is severely limited by the \textit{anisotropy} issue where the hidden representations are distributed into a narrow cone in the vector space. To address this issue, we present ContraGen, a novel contrastive learning framework to improve the representation with better uniformity and discrimination. We assess ContraGen on a wide range of downstream tasks in natural and programming languages. We show that ContraGen can effectively enhance both uniformity and discrimination of the representations and lead to the desired improvement on various language understanding tasks where discriminative representations are crucial for attaining good performance. Specifically, we attain $44\%$ relative improvement on the Semantic Textual Similarity tasks and $34\%$ on Code-to-Code Search tasks. Furthermore, by improving the expressiveness of the representations, ContraGen also boosts the source code generation capability with $9\%$ relative improvement on execution accuracy on the HumanEval benchmark.
MultiViz: An Analysis Benchmark for Visualizing and Understanding Multimodal Models
Jun 30, 2022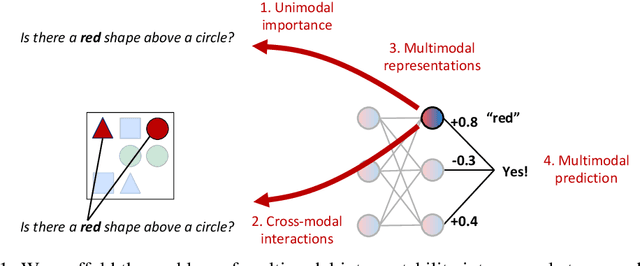


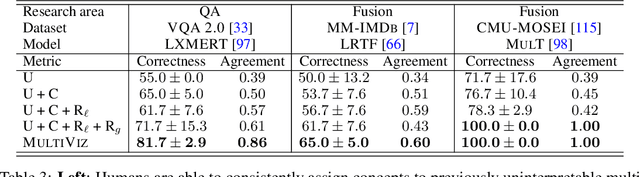
The promise of multimodal models for real-world applications has inspired research in visualizing and understanding their internal mechanics with the end goal of empowering stakeholders to visualize model behavior, perform model debugging, and promote trust in machine learning models. However, modern multimodal models are typically black-box neural networks, which makes it challenging to understand their internal mechanics. How can we visualize the internal modeling of multimodal interactions in these models? Our paper aims to fill this gap by proposing MultiViz, a method for analyzing the behavior of multimodal models by scaffolding the problem of interpretability into 4 stages: (1) unimodal importance: how each modality contributes towards downstream modeling and prediction, (2) cross-modal interactions: how different modalities relate with each other, (3) multimodal representations: how unimodal and cross-modal interactions are represented in decision-level features, and (4) multimodal prediction: how decision-level features are composed to make a prediction. MultiViz is designed to operate on diverse modalities, models, tasks, and research areas. Through experiments on 8 trained models across 6 real-world tasks, we show that the complementary stages in MultiViz together enable users to (1) simulate model predictions, (2) assign interpretable concepts to features, (3) perform error analysis on model misclassifications, and (4) use insights from error analysis to debug models. MultiViz is publicly available, will be regularly updated with new interpretation tools and metrics, and welcomes inputs from the community.
Generating Compositional Color Representations from Text
Sep 22, 2021
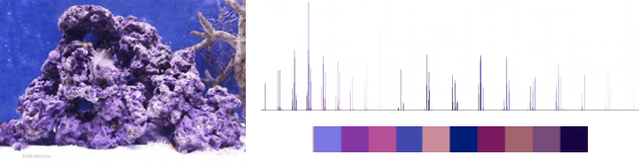
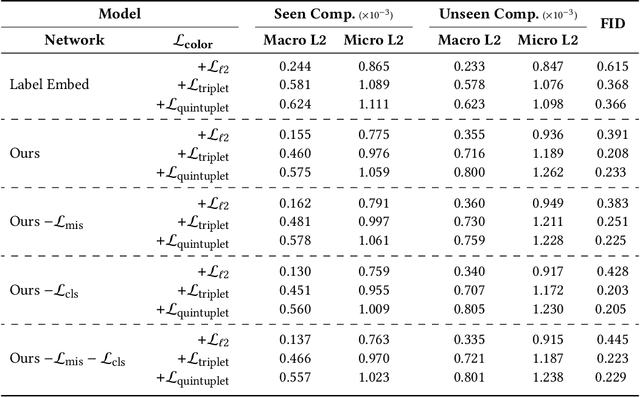

We consider the cross-modal task of producing color representations for text phrases. Motivated by the fact that a significant fraction of user queries on an image search engine follow an (attribute, object) structure, we propose a generative adversarial network that generates color profiles for such bigrams. We design our pipeline to learn composition - the ability to combine seen attributes and objects to unseen pairs. We propose a novel dataset curation pipeline from existing public sources. We describe how a set of phrases of interest can be compiled using a graph propagation technique, and then mapped to images. While this dataset is specialized for our investigations on color, the method can be extended to other visual dimensions where composition is of interest. We provide detailed ablation studies that test the behavior of our GAN architecture with loss functions from the contrastive learning literature. We show that the generative model achieves lower Frechet Inception Distance than discriminative ones, and therefore predicts color profiles that better match those from real images. Finally, we demonstrate improved performance in image retrieval and classification, indicating the crucial role that color plays in these downstream tasks.