 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenSage: Self-programming Agent Generation Engine
Feb 18, 2026Agent development kits (ADKs) provide effective platforms and tooling for constructing agents, and their designs are critical to the constructed agents' performance, especially the functionality for agent topology, tools, and memory. However, current ADKs either lack sufficient functional support or rely on humans to manually design these components, limiting agents' generalizability and overall performance. We propose OpenSage, the first ADK that enables LLMs to automatically create agents with self-generated topology and toolsets while providing comprehensive and structured memory support. OpenSage offers effective functionality for agents to create and manage their own sub-agents and toolkits. It also features a hierarchical, graph-based memory system for efficient management and a specialized toolkit tailored to software engineering tasks. Extensive experiments across three state-of-the-art benchmarks with various backbone models demonstrate the advantages of OpenSage over existing ADKs. We also conduct rigorous ablation studies to demonstrate the effectiveness of our design for each component. We believe OpenSage can pave the way for the next generation of agent development, shifting the focus from human-centered to AI-centered paradigms.
To Defend Against Cyber Attacks, We Must Teach AI Agents to Hack
Feb 01, 2026For over a decade, cybersecurity has relied on human labor scarcity to limit attackers to high-value targets manually or generic automated attacks at scale. Building sophisticated exploits requires deep expertise and manual effort, leading defenders to assume adversaries cannot afford tailored attacks at scale. AI agents break this balance by automating vulnerability discovery and exploitation across thousands of targets, needing only small success rates to remain profitable. Current developers focus on preventing misuse through data filtering, safety alignment, and output guardrails. Such protections fail against adversaries who control open-weight models, bypass safety controls, or develop offensive capabilities independently. We argue that AI-agent-driven cyber attacks are inevitable, requiring a fundamental shift in defensive strategy. In this position paper, we identify why existing defenses cannot stop adaptive adversaries and demonstrate that defenders must develop offensive security intelligence. We propose three actions for building frontier offensive AI capabilities responsibly. First, construct comprehensive benchmarks covering the full attack lifecycle. Second, advance from workflow-based to trained agents for discovering in-wild vulnerabilities at scale. Third, implement governance restricting offensive agents to audited cyber ranges, staging release by capability tier, and distilling findings into safe defensive-only agents. We strongly recommend treating offensive AI capabilities as essential defensive infrastructure, as containing cybersecurity risks requires mastering them in controlled settings before adversaries do.
SWE-Spot: Building Small Repo-Experts with Repository-Centric Learning
Jan 29, 2026The deployment of coding agents in privacy-sensitive and resource-constrained environments drives the demand for capable open-weight Small Language Models (SLMs). However, they suffer from a fundamental capability gap: unlike frontier large models, they lack the inference-time strong generalization to work with complicated, unfamiliar codebases. We identify that the prevailing Task-Centric Learning (TCL) paradigm, which scales exposure across disparate repositories, fails to address this limitation. In response, we propose Repository-Centric Learning (RCL), a paradigm shift that prioritizes vertical repository depth over horizontal task breadth, suggesting SLMs must internalize the "physics" of a target software environment through parametric knowledge acquisition, rather than attempting to recover it via costly inference-time search. Following this new paradigm, we design a four-unit Repository-Centric Experience, transforming static codebases into interactive learning signals, to train SWE-Spot-4B, a family of highly compact models built as repo-specialized experts that breaks established scaling trends, outperforming open-weight models up to larger (e.g., CWM by Meta, Qwen3-Coder-30B) and surpassing/matching efficiency-focused commercial models (e.g., GPT-4.1-mini, GPT-5-nano) across multiple SWE tasks. Further analysis reveals that RCL yields higher training sample efficiency and lower inference costs, emphasizing that for building efficient intelligence, repository mastery is a distinct and necessary dimension that complements general coding capability.
DevOps-Gym: Benchmarking AI Agents in Software DevOps Cycle
Jan 27, 2026Even though demonstrating extraordinary capabilities in code generation and software issue resolving, AI agents' capabilities in the full software DevOps cycle are still unknown. Different from pure code generation, handling the DevOps cycle in real-world software, including developing, deploying, and managing, requires analyzing large-scale projects, understanding dynamic program behaviors, leveraging domain-specific tools, and making sequential decisions. However, existing benchmarks focus on isolated problems and lack environments and tool interfaces for DevOps. We introduce DevOps-Gym, the first end-to-end benchmark for evaluating AI agents across core DevOps workflows: build and configuration, monitoring, issue resolving, and test generation. DevOps-Gym includes 700+ real-world tasks collected from 30+ projects in Java and Go. We develop a semi-automated data collection mechanism with rigorous and non-trivial expert efforts in ensuring the task coverage and quality. Our evaluation of state-of-the-art models and agents reveals fundamental limitations: they struggle with issue resolving and test generation in Java and Go, and remain unable to handle new tasks such as monitoring and build and configuration. These results highlight the need for essential research in automating the full DevOps cycle with AI agents.
Co-PatcheR: Collaborative Software Patching with Component(s)-specific Small Reasoning Models
May 25, 2025



Motivated by the success of general-purpose large language models (LLMs) in software patching, recent works started to train specialized patching models. Most works trained one model to handle the end-to-end patching pipeline (including issue localization, patch generation, and patch validation). However, it is hard for a small model to handle all tasks, as different sub-tasks have different workflows and require different expertise. As such, by using a 70 billion model, SOTA methods can only reach up to 41% resolved rate on SWE-bench-Verified. Motivated by the collaborative nature, we propose Co-PatcheR, the first collaborative patching system with small and specialized reasoning models for individual components. Our key technique novelties are the specific task designs and training recipes. First, we train a model for localization and patch generation. Our localization pinpoints the suspicious lines through a two-step procedure, and our generation combines patch generation and critique. We then propose a hybrid patch validation that includes two models for crafting issue-reproducing test cases with and without assertions and judging patch correctness, followed by a majority vote-based patch selection. Through extensive evaluation, we show that Co-PatcheR achieves 46% resolved rate on SWE-bench-Verified with only 3 x 14B models. This makes Co-PatcheR the best patcher with specialized models, requiring the least training resources and the smallest models. We conduct a comprehensive ablation study to validate our recipes, as well as our choice of training data number, model size, and testing-phase scaling strategy.
SemCoder: Training Code Language Models with Comprehensive Semantics
Jun 03, 2024Code Large Language Models (Code LLMs) have excelled at tasks like code completion but often miss deeper semantics such as execution effects and dynamic states. This paper aims to bridge the gap between Code LLMs' reliance on static text data and the need for thorough semantic understanding for complex tasks like debugging and program repair. We introduce a novel strategy to train Code LLMs with comprehensive semantics, encompassing high-level functional descriptions, local execution effects of individual statements, and overall input/output behavior, thereby linking static code text with dynamic execution states. We begin by collecting PyX, a clean code corpus of fully executable samples with functional descriptions and execution tracing. We propose training Code LLMs to write code and represent and reason about execution behaviors using natural language, mimicking human verbal debugging. This approach led to the development of SemCoder, a Code LLM with only 6.7B parameters, which shows competitive performance with GPT-3.5-turbo on code generation and execution reasoning tasks. SemCoder achieves 81.1% on HumanEval (GPT-3.5-turbo: 76.8%) and 54.5% on CRUXEval-I (GPT-3.5-turbo: 50.3%). We also study the effectiveness of SemCoder's monologue-style execution reasoning compared to concrete scratchpad reasoning, showing that our approach integrates semantics from multiple dimensions more smoothly. Finally, we demonstrate the potential of applying learned semantics to improve Code LLMs' debugging and self-refining capabilities.
CYCLE: Learning to Self-Refine the Code Generation
Mar 27, 2024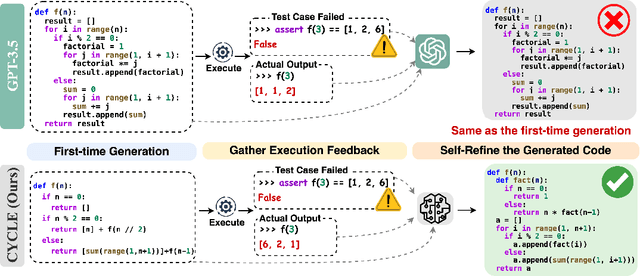
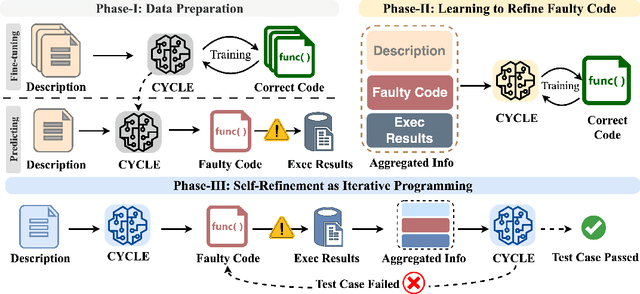
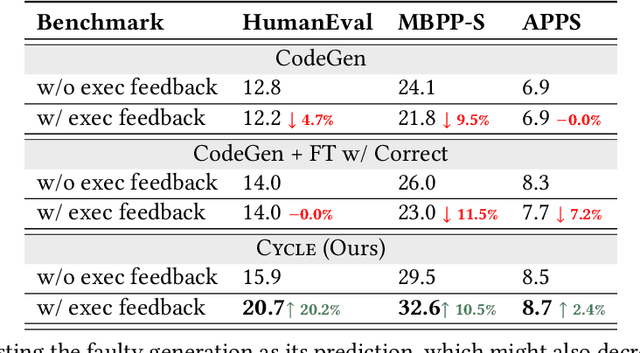

Pre-trained code language models have achieved promising performance in code generation and improved the programming efficiency of human developers. However, their self-refinement capability is typically overlooked by the existing evaluations of code LMs, which focus only on the accuracy of the one-time prediction. For the cases when code LMs fail to implement the correct program, developers actually find it hard to debug and fix the faulty prediction since it is not written by the developers themselves. Unfortunately, our study reveals that code LMs cannot efficiently self-refine their faulty generations as well. In this paper, we propose CYCLE framework, learning to self-refine the faulty generation according to the available feedback, such as the execution results reported by the test suites. We evaluate CYCLE on three popular code generation benchmarks, HumanEval, MBPP, and APPS. The results reveal that CYCLE successfully maintains, sometimes improves, the quality of one-time code generation, while significantly improving the self-refinement capability of code LMs. We implement four variants of CYCLE with varied numbers of parameters across 350M, 1B, 2B, and 3B, and the experiments show that CYCLE consistently boosts the code generation performance, by up to 63.5%, across benchmarks and varied model sizes. We also notice that CYCLE outperforms code LMs that have 3$\times$ more parameters in self-refinement.
Vulnerability Detection with Code Language Models: How Far Are We?
Mar 27, 2024

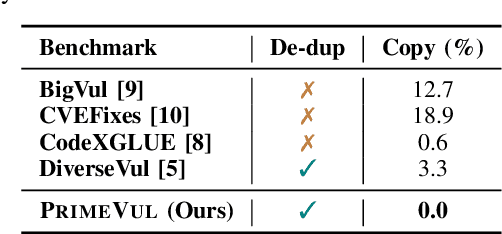
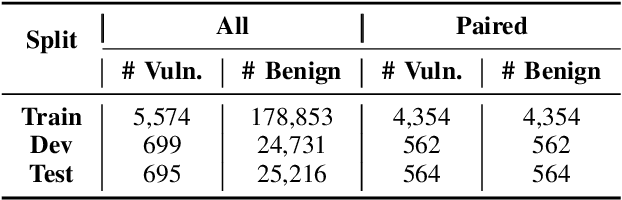
In the context of the rising interest in code language models (code LMs) and vulnerability detection, we study the effectiveness of code LMs for detecting vulnerabilities. Our analysis reveals significant shortcomings in existing vulnerability datasets, including poor data quality, low label accuracy, and high duplication rates, leading to unreliable model performance in realistic vulnerability detection scenarios. Additionally, the evaluation methods used with these datasets are not representative of real-world vulnerability detection. To address these challenges, we introduce PrimeVul, a new dataset for training and evaluating code LMs for vulnerability detection. PrimeVul incorporates a novel set of data labeling techniques that achieve comparable label accuracy to human-verified benchmarks while significantly expanding the dataset. It also implements a rigorous data de-duplication and chronological data splitting strategy to mitigate data leakage issues, alongside introducing more realistic evaluation metrics and settings. This comprehensive approach aims to provide a more accurate assessment of code LMs' performance in real-world conditions. Evaluating code LMs on PrimeVul reveals that existing benchmarks significantly overestimate the performance of these models. For instance, a state-of-the-art 7B model scored 68.26% F1 on BigVul but only 3.09% F1 on PrimeVul. Attempts to improve performance through advanced training techniques and larger models like GPT-3.5 and GPT-4 were unsuccessful, with results akin to random guessing in the most stringent settings. These findings underscore the considerable gap between current capabilities and the practical requirements for deploying code LMs in security roles, highlighting the need for more innovative research in this domain.
Beyond Accuracy: Evaluating Self-Consistency of Code Large Language Models with IdentityChain
Oct 21, 2023



Code Large Language Models (Code LLMs) are being increasingly employed in real-life applications, so evaluating them is critical. While the general accuracy of Code LLMs on individual tasks has been extensively evaluated, their self-consistency across different tasks is overlooked. Intuitively, a trustworthy model should be self-consistent when generating natural language specifications for its own code and generating code for its own specifications. Failure to preserve self-consistency reveals a lack of understanding of the shared semantics underlying natural language and programming language, and therefore undermines the trustworthiness of a model. In this paper, we first formally define the self-consistency of Code LLMs and then design a framework, IdentityChain, which effectively and efficiently evaluates the self-consistency and general accuracy of a model at the same time. We study eleven Code LLMs and show that they fail to preserve self-consistency, which is indeed a distinct aspect from general accuracy. Furthermore, we show that IdentityChain can be used as a model debugging tool to expose weaknesses of Code LLMs by demonstrating three major weaknesses that we identify in current models using IdentityChain. Our code is available at https://github.com/marcusm117/IdentityChain.
CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion
Oct 17, 2023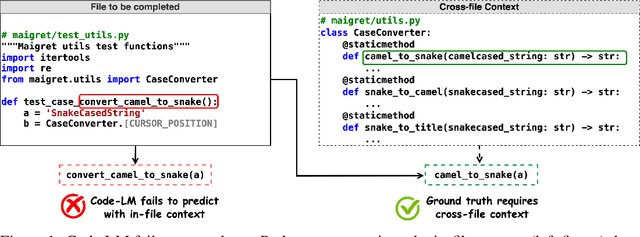
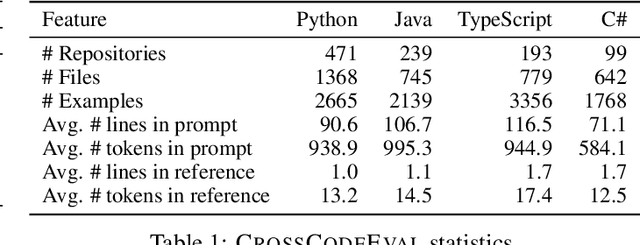
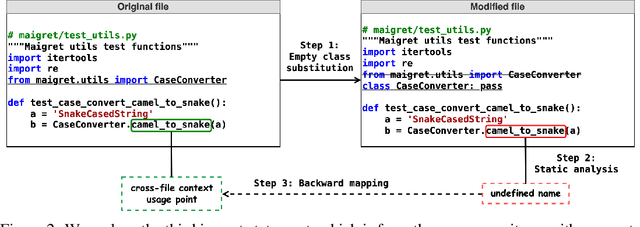
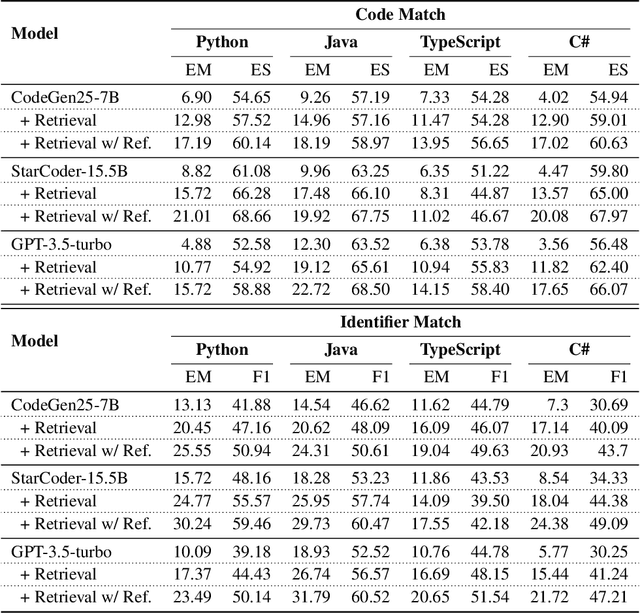
Code completion models have made significant progress in recent years, yet current popular evaluation datasets, such as HumanEval and MBPP, predominantly focus on code completion tasks within a single file. This over-simplified setting falls short of representing the real-world software development scenario where repositories span multiple files with numerous cross-file dependencies, and accessing and understanding cross-file context is often required to complete the code correctly. To fill in this gap, we propose CrossCodeEval, a diverse and multilingual code completion benchmark that necessitates an in-depth cross-file contextual understanding to complete the code accurately. CrossCodeEval is built on a diverse set of real-world, open-sourced, permissively-licensed repositories in four popular programming languages: Python, Java, TypeScript, and C#. To create examples that strictly require cross-file context for accurate completion, we propose a straightforward yet efficient static-analysis-based approach to pinpoint the use of cross-file context within the current file. Extensive experiments on state-of-the-art code language models like CodeGen and StarCoder demonstrate that CrossCodeEval is extremely challenging when the relevant cross-file context is absent, and we see clear improvements when adding these context into the prompt. However, despite such improvements, the pinnacle of performance remains notably unattained even with the highest-performing model, indicating that CrossCodeEval is also capable of assessing model's capability in leveraging extensive context to make better code completion. Finally, we benchmarked various methods in retrieving cross-file context, and show that CrossCodeEval can also be used to measure the capability of code retrievers.