 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Production LLMs with Combined Token/Embedding Speculators
Apr 29, 2024This technical report describes the design and training of novel speculative decoding draft models, for accelerating the inference speeds of large language models in a production environment. By conditioning draft predictions on both context vectors and sampled tokens, we can train our speculators to efficiently predict high-quality n-grams, which the base model then accepts or rejects. This allows us to effectively predict multiple tokens per inference forward pass, accelerating wall-clock inference speeds of highly optimized base model implementations by a factor of 2-3x. We explore these initial results and describe next steps for further improvements.
Automated Code generation for Information Technology Tasks in YAML through Large Language Models
May 05, 2023



The recent improvement in code generation capabilities due to the use of large language models has mainly benefited general purpose programming languages. Domain specific languages, such as the ones used for IT Automation, have received far less attention, despite involving many active developers and being an essential component of modern cloud platforms. This work focuses on the generation of Ansible-YAML, a widely used markup language for IT Automation. We present Ansible Wisdom, a natural-language to Ansible-YAML code generation tool, aimed at improving IT automation productivity. Ansible Wisdom is a transformer-based model, extended by training with a new dataset containing Ansible-YAML. We also develop two novel performance metrics for YAML and Ansible to capture the specific characteristics of this domain. Results show that Ansible Wisdom can accurately generate Ansible script from natural language prompts with performance comparable or better than existing state of the art code generation models.
Study of Distractors in Neural Models of Code
Mar 03, 2023



Finding important features that contribute to the prediction of neural models is an active area of research in explainable AI. Neural models are opaque and finding such features sheds light on a better understanding of their predictions. In contrast, in this work, we present an inverse perspective of distractor features: features that cast doubt about the prediction by affecting the model's confidence in its prediction. Understanding distractors provide a complementary view of the features' relevance in the predictions of neural models. In this paper, we apply a reduction-based technique to find distractors and provide our preliminary results of their impacts and types. Our experiments across various tasks, models, and datasets of code reveal that the removal of tokens can have a significant impact on the confidence of models in their predictions and the categories of tokens can also play a vital role in the model's confidence. Our study aims to enhance the transparency of models by emphasizing those tokens that significantly influence the confidence of the models.
VELVET: a noVel Ensemble Learning approach to automatically locate VulnErable sTatements
Jan 13, 2022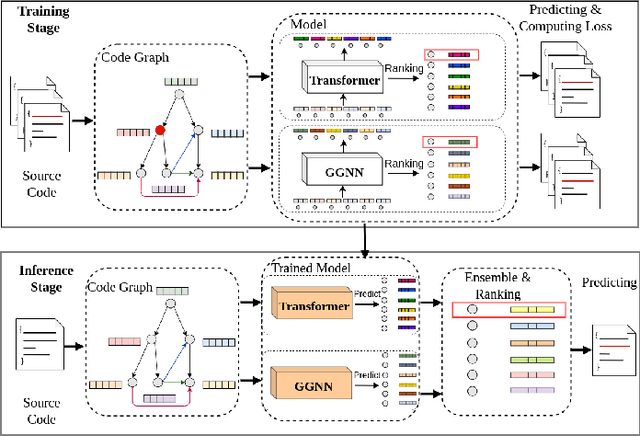
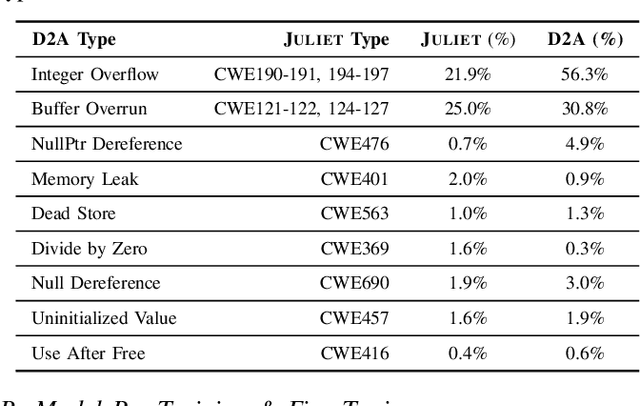
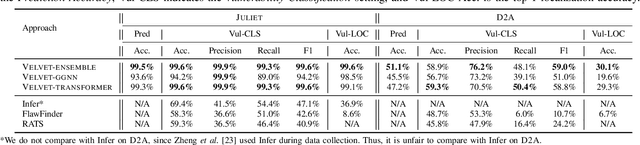
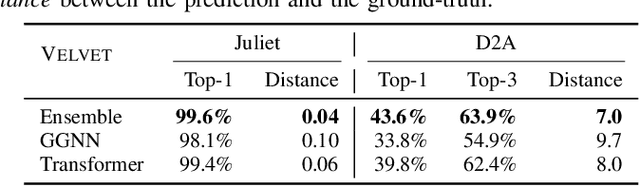
Automatically locating vulnerable statements in source code is crucial to assure software security and alleviate developers' debugging efforts. This becomes even more important in today's software ecosystem, where vulnerable code can flow easily and unwittingly within and across software repositories like GitHub. Across such millions of lines of code, traditional static and dynamic approaches struggle to scale. Although existing machine-learning-based approaches look promising in such a setting, most work detects vulnerable code at a higher granularity -- at the method or file level. Thus, developers still need to inspect a significant amount of code to locate the vulnerable statement(s) that need to be fixed. This paper presents VELVET, a novel ensemble learning approach to locate vulnerable statements. Our model combines graph-based and sequence-based neural networks to successfully capture the local and global context of a program graph and effectively understand code semantics and vulnerable patterns. To study VELVET's effectiveness, we use an off-the-shelf synthetic dataset and a recently published real-world dataset. In the static analysis setting, where vulnerable functions are not detected in advance, VELVET achieves 4.5x better performance than the baseline static analyzers on the real-world data. For the isolated vulnerability localization task, where we assume the vulnerability of a function is known while the specific vulnerable statement is unknown, we compare VELVET with several neural networks that also attend to local and global context of code. VELVET achieves 99.6% and 43.6% top-1 accuracy over synthetic data and real-world data, respectively, outperforming the baseline deep-learning models by 5.3-29.0%.
Data-Driven and SE-assisted AI Model Signal-Awareness Enhancement and Introspection
Nov 10, 2021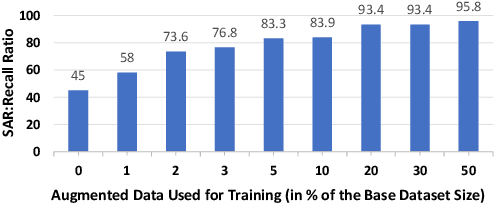
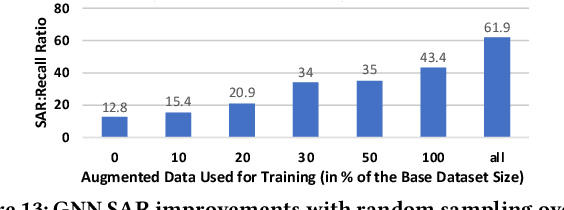
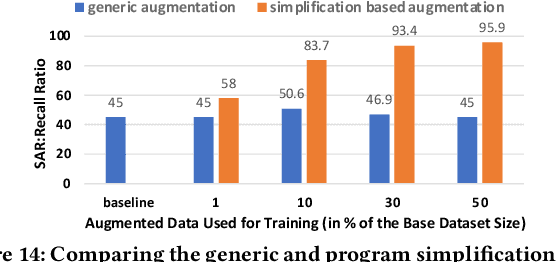
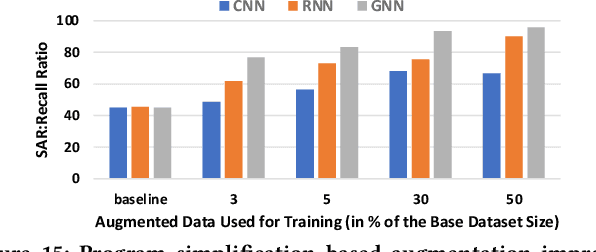
AI modeling for source code understanding tasks has been making significant progress, and is being adopted in production development pipelines. However, reliability concerns, especially whether the models are actually learning task-related aspects of source code, are being raised. While recent model-probing approaches have observed a lack of signal awareness in many AI-for-code models, i.e. models not capturing task-relevant signals, they do not offer solutions to rectify this problem. In this paper, we explore data-driven approaches to enhance models' signal-awareness: 1) we combine the SE concept of code complexity with the AI technique of curriculum learning; 2) we incorporate SE assistance into AI models by customizing Delta Debugging to generate simplified signal-preserving programs, augmenting them to the training dataset. With our techniques, we achieve up to 4.8x improvement in model signal awareness. Using the notion of code complexity, we further present a novel model learning introspection approach from the perspective of the dataset.
Software Vulnerability Detection via Deep Learning over Disaggregated Code Graph Representation
Sep 07, 2021
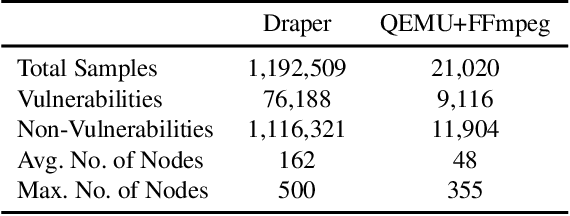
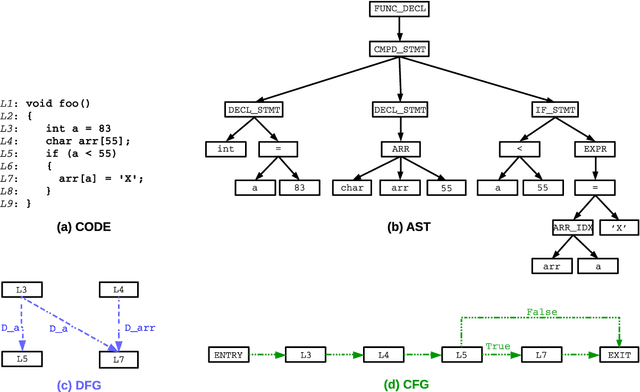
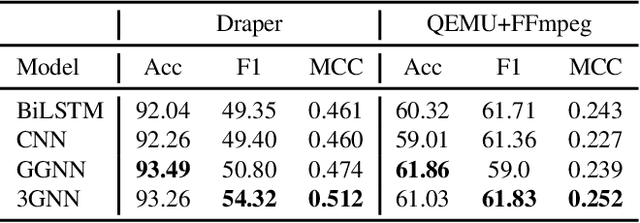
Identifying vulnerable code is a precautionary measure to counter software security breaches. Tedious expert effort has been spent to build static analyzers, yet insecure patterns are barely fully enumerated. This work explores a deep learning approach to automatically learn the insecure patterns from code corpora. Because code naturally admits graph structures with parsing, we develop a novel graph neural network (GNN) to exploit both the semantic context and structural regularity of a program, in order to improve prediction performance. Compared with a generic GNN, our enhancements include a synthesis of multiple representations learned from the several parsed graphs of a program, and a new training loss metric that leverages the fine granularity of labeling. Our model outperforms multiple text, image and graph-based approaches, across two real-world datasets.
Probing Model Signal-Awareness via Prediction-Preserving Input Minimization
Nov 25, 2020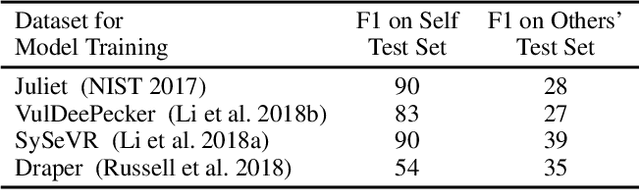

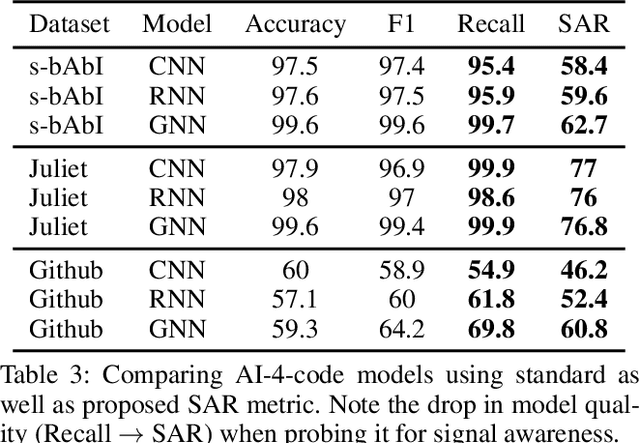
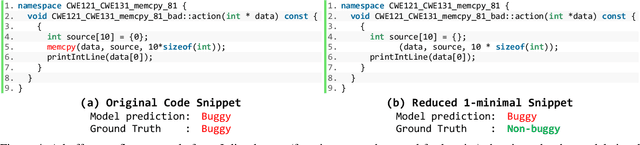
This work explores the signal awareness of AI models for source code understanding. Using a software vulnerability detection use-case, we evaluate the models' ability to capture the correct vulnerability signals to produce their predictions. Our prediction-preserving input minimization (P2IM) approach systematically reduces the original source code to a minimal snippet which a model needs to maintain its prediction. The model's reliance on incorrect signals is then uncovered when a vulnerability in the original code is missing in the minimal snippet, both of which the model however predicts as being vulnerable. We apply P2IM on three state-of-the-art neural network models across multiple datasets, and measure their signal awareness using a new metric we propose- Signal-aware Recall (SAR). The results show a sharp drop in the model's Recall from the high 90s to sub-60s with the new metric, highlighting that the models are presumably picking up a lot of noise or dataset nuances while learning their vulnerability detection logic.
Learning to map source code to software vulnerability using code-as-a-graph
Jun 15, 2020

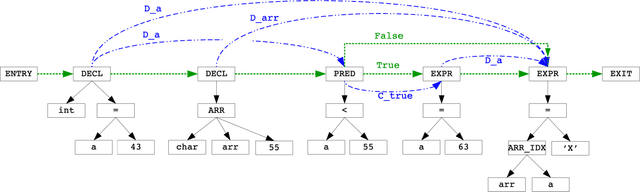
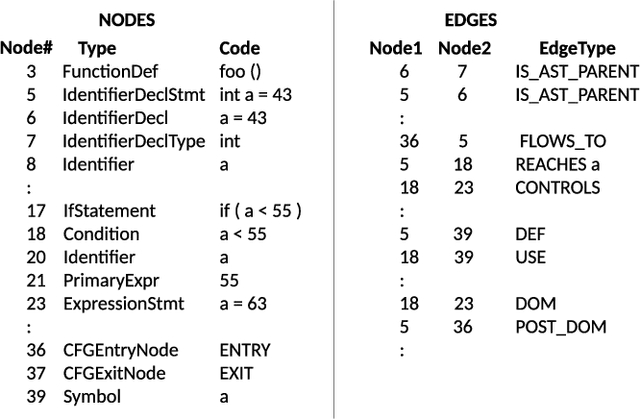
We explore the applicability of Graph Neural Networks in learning the nuances of source code from a security perspective. Specifically, whether signatures of vulnerabilities in source code can be learned from its graph representation, in terms of relationships between nodes and edges. We create a pipeline we call AI4VA, which first encodes a sample source code into a Code Property Graph. The extracted graph is then vectorized in a manner which preserves its semantic information. A Gated Graph Neural Network is then trained using several such graphs to automatically extract templates differentiating the graph of a vulnerable sample from a healthy one. Our model outperforms static analyzers, classic machine learning, as well as CNN and RNN-based deep learning models on two of the three datasets we experiment with. We thus show that a code-as-graph encoding is more meaningful for vulnerability detection than existing code-as-photo and linear sequence encoding approaches. (Submitted Oct 2019, Paper #28, ICST)