 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Prompts to Propositions: A Logic-Based Lens on Student-LLM Interactions
Apr 25, 2025Background and Context. The increasing integration of large language models (LLMs) in computing education presents an emerging challenge in understanding how students use LLMs and craft prompts to solve computational tasks. Prior research has used both qualitative and quantitative methods to analyze prompting behavior, but these approaches lack scalability or fail to effectively capture the semantic evolution of prompts. Objective. In this paper, we investigate whether students prompts can be systematically analyzed using propositional logic constraints. We examine whether this approach can identify patterns in prompt evolution, detect struggling students, and provide insights into effective and ineffective strategies. Method. We introduce Prompt2Constraints, a novel method that translates students prompts into logical constraints. The constraints are able to represent the intent of the prompts in succinct and quantifiable ways. We used this approach to analyze a dataset of 1,872 prompts from 203 students solving introductory programming tasks. Findings. We find that while successful and unsuccessful attempts tend to use a similar number of constraints overall, when students fail, they often modify their prompts more significantly, shifting problem-solving strategies midway. We also identify points where specific interventions could be most helpful to students for refining their prompts. Implications. This work offers a new and scalable way to detect students who struggle in solving natural language programming tasks. This work could be extended to investigate more complex tasks and integrated into programming tools to provide real-time support.
Unlearning Trojans in Large Language Models: A Comparison Between Natural Language and Source Code
Aug 22, 2024This work investigates the application of Machine Unlearning (MU) for mitigating the impact of trojans embedded in conventional large language models of natural language (Text-LLMs) and large language models of code (Code-LLMs) We propose a novel unlearning approach, LYA, that leverages both gradient ascent and elastic weight consolidation, a Fisher Information Matrix (FIM) based regularization technique, to unlearn trojans from poisoned models. We compare the effectiveness of LYA against conventional techniques like fine-tuning, retraining, and vanilla gradient ascent. The subject models we investigate are BERT and CodeBERT, for sentiment analysis and code defect detection tasks, respectively. Our findings demonstrate that the combination of gradient ascent and FIM-based regularization, as done in LYA, outperforms existing methods in removing the trojan's influence from the poisoned model, while preserving its original functionality. To the best of our knowledge, this is the first work that compares and contrasts MU of trojans in LLMs, in the NL and Coding domain.
Harnessing the Power of LLMs: Automating Unit Test Generation for High-Performance Computing
Jul 06, 2024

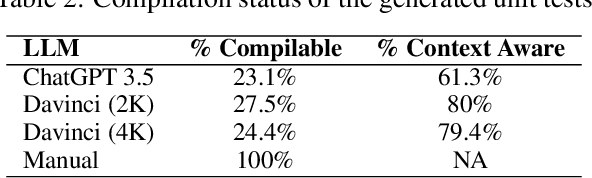
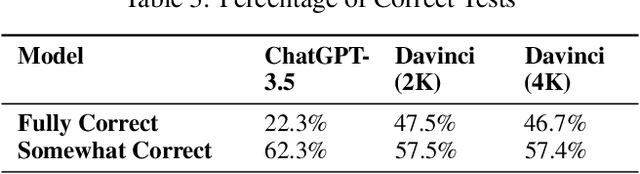
Unit testing is crucial in software engineering for ensuring quality. However, it's not widely used in parallel and high-performance computing software, particularly scientific applications, due to their smaller, diverse user base and complex logic. These factors make unit testing challenging and expensive, as it requires specialized knowledge and existing automated tools are often ineffective. To address this, we propose an automated method for generating unit tests for such software, considering their unique features like complex logic and parallel processing. Recently, large language models (LLMs) have shown promise in coding and testing. We explored the capabilities of Davinci (text-davinci-002) and ChatGPT (gpt-3.5-turbo) in creating unit tests for C++ parallel programs. Our results show that LLMs can generate mostly correct and comprehensive unit tests, although they have some limitations, such as repetitive assertions and blank test cases.
Trojans in Large Language Models of Code: A Critical Review through a Trigger-Based Taxonomy
May 05, 2024

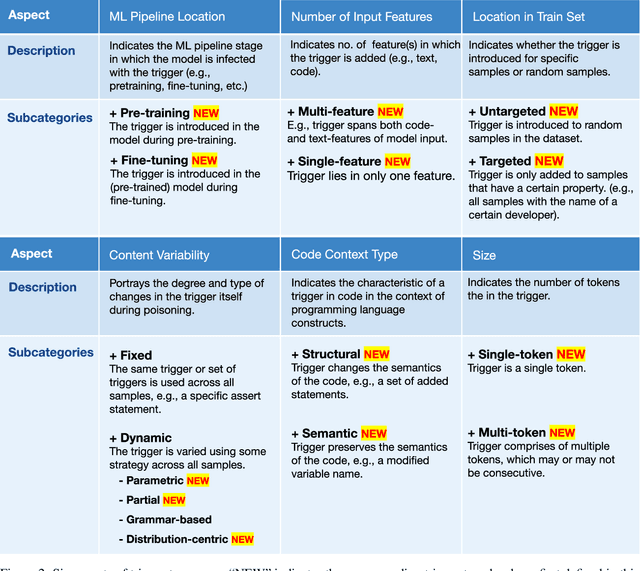

Large language models (LLMs) have provided a lot of exciting new capabilities in software development. However, the opaque nature of these models makes them difficult to reason about and inspect. Their opacity gives rise to potential security risks, as adversaries can train and deploy compromised models to disrupt the software development process in the victims' organization. This work presents an overview of the current state-of-the-art trojan attacks on large language models of code, with a focus on triggers -- the main design point of trojans -- with the aid of a novel unifying trigger taxonomy framework. We also aim to provide a uniform definition of the fundamental concepts in the area of trojans in Code LLMs. Finally, we draw implications of findings on how code models learn on trigger design.
On Trojan Signatures in Large Language Models of Code
Mar 07, 2024Trojan signatures, as described by Fields et al. (2021), are noticeable differences in the distribution of the trojaned class parameters (weights) and the non-trojaned class parameters of the trojaned model, that can be used to detect the trojaned model. Fields et al. (2021) found trojan signatures in computer vision classification tasks with image models, such as, Resnet, WideResnet, Densenet, and VGG. In this paper, we investigate such signatures in the classifier layer parameters of large language models of source code. Our results suggest that trojan signatures could not generalize to LLMs of code. We found that trojaned code models are stubborn, even when the models were poisoned under more explicit settings (finetuned with pre-trained weights frozen). We analyzed nine trojaned models for two binary classification tasks: clone and defect detection. To the best of our knowledge, this is the first work to examine weight-based trojan signature revelation techniques for large-language models of code and furthermore to demonstrate that detecting trojans only from the weights in such models is a hard problem.
A Study of Variable-Role-based Feature Enrichment in Neural Models of Code
Mar 12, 2023Although deep neural models substantially reduce the overhead of feature engineering, the features readily available in the inputs might significantly impact training cost and the performance of the models. In this paper, we explore the impact of an unsuperivsed feature enrichment approach based on variable roles on the performance of neural models of code. The notion of variable roles (as introduced in the works of Sajaniemi et al. [Refs. 1,2]) has been found to help students' abilities in programming. In this paper, we investigate if this notion would improve the performance of neural models of code. To the best of our knowledge, this is the first work to investigate how Sajaniemi et al.'s concept of variable roles can affect neural models of code. In particular, we enrich a source code dataset by adding the role of individual variables in the dataset programs, and thereby conduct a study on the impact of variable role enrichment in training the Code2Seq model. In addition, we shed light on some challenges and opportunities in feature enrichment for neural code intelligence models.
Study of Distractors in Neural Models of Code
Mar 03, 2023



Finding important features that contribute to the prediction of neural models is an active area of research in explainable AI. Neural models are opaque and finding such features sheds light on a better understanding of their predictions. In contrast, in this work, we present an inverse perspective of distractor features: features that cast doubt about the prediction by affecting the model's confidence in its prediction. Understanding distractors provide a complementary view of the features' relevance in the predictions of neural models. In this paper, we apply a reduction-based technique to find distractors and provide our preliminary results of their impacts and types. Our experiments across various tasks, models, and datasets of code reveal that the removal of tokens can have a significant impact on the confidence of models in their predictions and the categories of tokens can also play a vital role in the model's confidence. Our study aims to enhance the transparency of models by emphasizing those tokens that significantly influence the confidence of the models.
Syntax-Guided Program Reduction for Understanding Neural Code Intelligence Models
May 28, 2022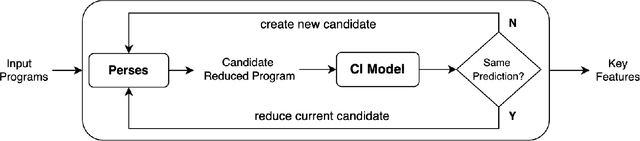
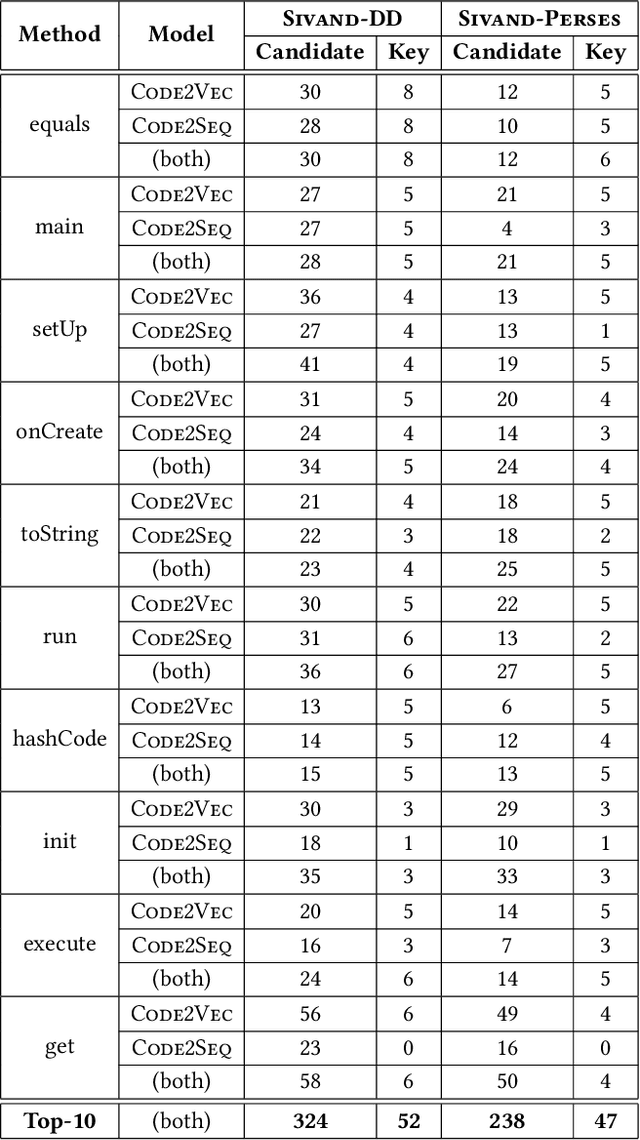
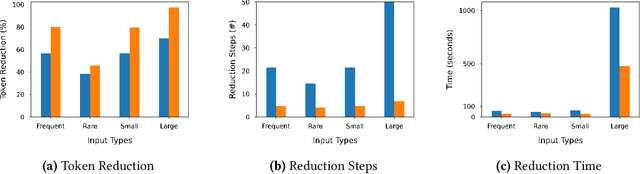
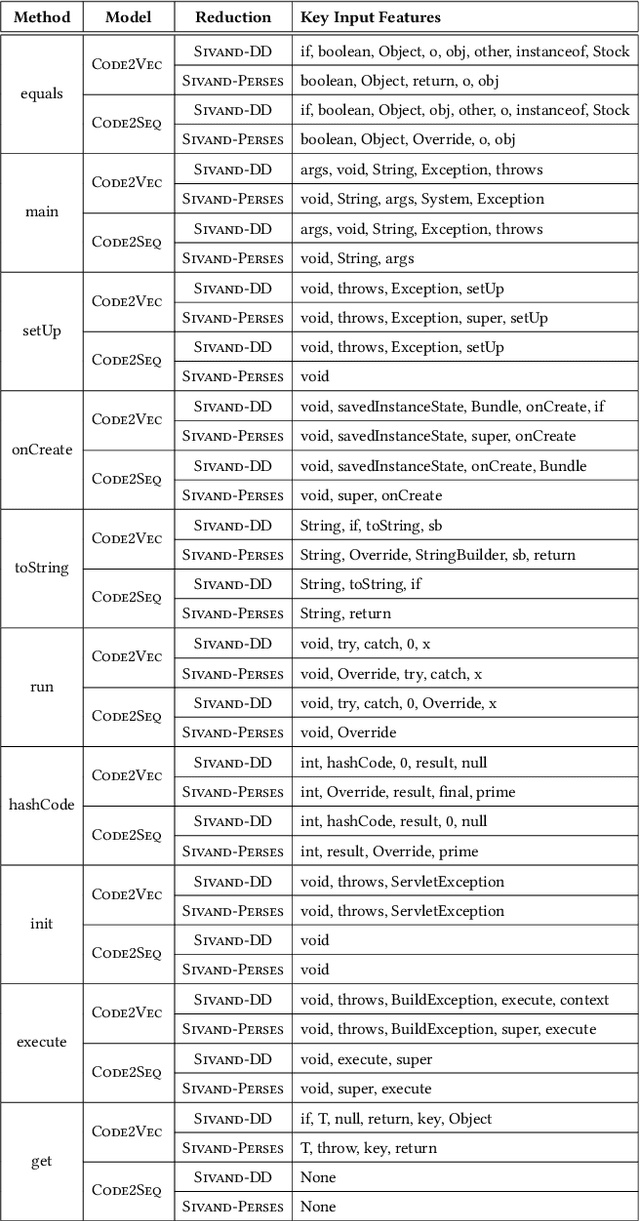
Neural code intelligence (CI) models are opaque black-boxes and offer little insight on the features they use in making predictions. This opacity may lead to distrust in their prediction and hamper their wider adoption in safety-critical applications. Recently, input program reduction techniques have been proposed to identify key features in the input programs to improve the transparency of CI models. However, this approach is syntax-unaware and does not consider the grammar of the programming language. In this paper, we apply a syntax-guided program reduction technique that considers the grammar of the input programs during reduction. Our experiments on multiple models across different types of input programs show that the syntax-guided program reduction technique is faster and provides smaller sets of key tokens in reduced programs. We also show that the key tokens could be used in generating adversarial examples for up to 65% of the input programs.
Encoding Program as Image: Evaluating Visual Representation of Source Code
Nov 01, 2021
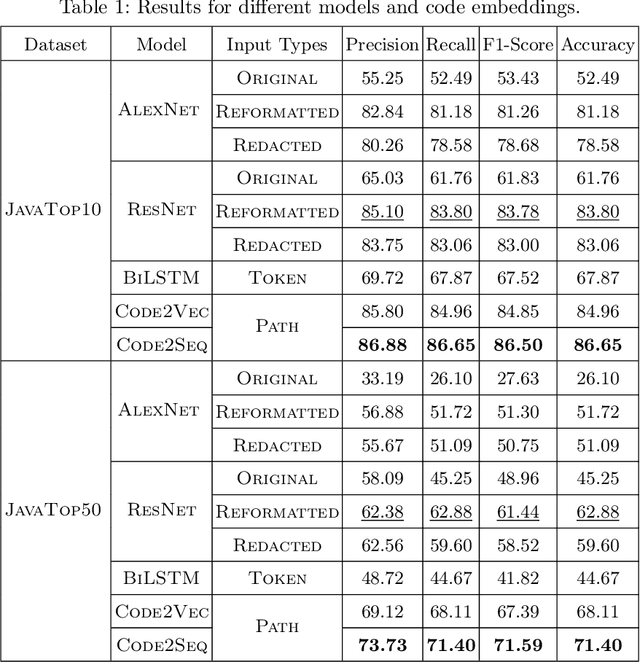

There are several approaches to encode source code in the input vectors of neural models. These approaches attempt to include various syntactic and semantic features of input programs in their encoding. In this paper, we investigate Code2Snapshot, a novel representation of the source code that is based on the snapshots of input programs. We evaluate several variations of this representation and compare its performance with state-of-the-art representations that utilize the rich syntactic and semantic features of input programs. Our preliminary study on the utility of Code2Snapshot in the code summarization task suggests that simple snapshots of input programs have comparable performance to the state-of-the-art representations. Interestingly, obscuring the input programs have insignificant impacts on the Code2Snapshot performance, suggesting that, for some tasks, neural models may provide high performance by relying merely on the structure of input programs.
Memorization and Generalization in Neural Code Intelligence Models
Jun 16, 2021
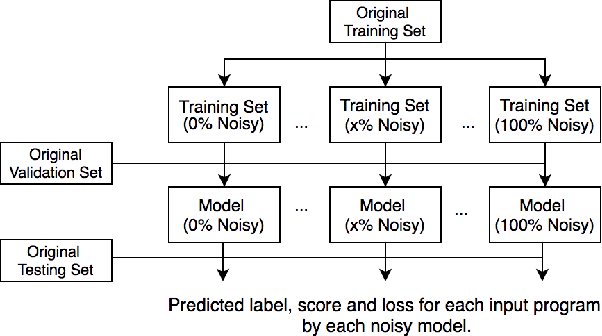
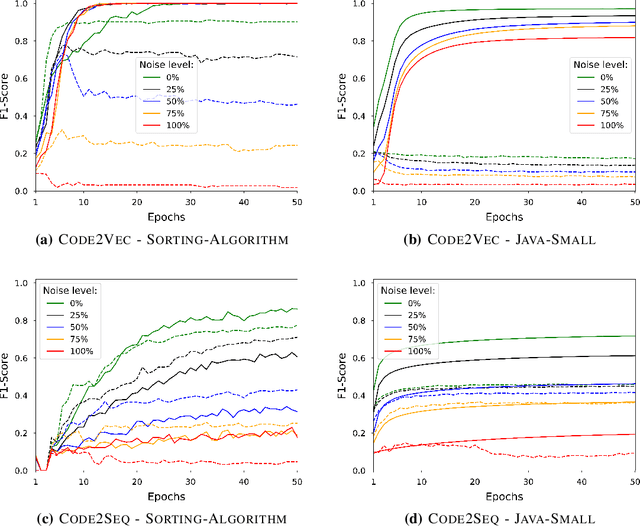
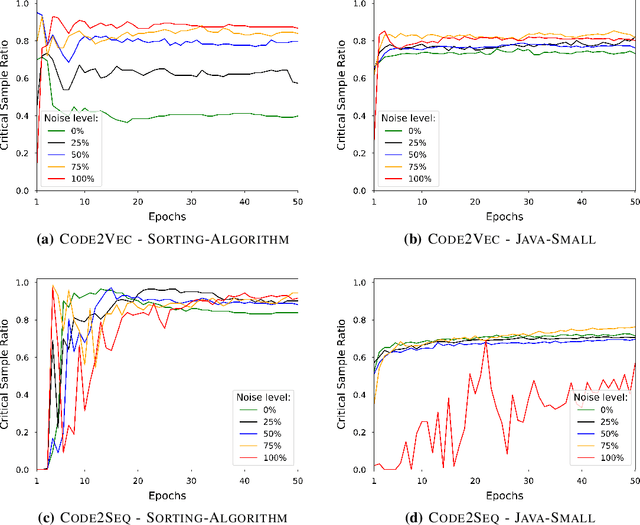
Deep Neural Networks (DNN) are increasingly commonly used in software engineering and code intelligence tasks. These are powerful tools that are capable of learning highly generalizable patterns from large datasets through millions of parameters. At the same time, training DNNs means walking a knife's edges, because their large capacity also renders them prone to memorizing data points. While traditionally thought of as an aspect of over-training, recent work suggests that the memorization risk manifests especially strongly when the training datasets are noisy and memorization is the only recourse. Unfortunately, most code intelligence tasks rely on rather noise-prone and repetitive data sources, such as GitHub, which, due to their sheer size, cannot be manually inspected and evaluated. We evaluate the memorization and generalization tendencies in neural code intelligence models through a case study across several benchmarks and model families by leveraging established approaches from other fields that use DNNs, such as introducing targeted noise into the training dataset. In addition to reinforcing prior general findings about the extent of memorization in DNNs, our results shed light on the impact of noisy dataset in training.