 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Prompts to Propositions: A Logic-Based Lens on Student-LLM Interactions
Apr 25, 2025Background and Context. The increasing integration of large language models (LLMs) in computing education presents an emerging challenge in understanding how students use LLMs and craft prompts to solve computational tasks. Prior research has used both qualitative and quantitative methods to analyze prompting behavior, but these approaches lack scalability or fail to effectively capture the semantic evolution of prompts. Objective. In this paper, we investigate whether students prompts can be systematically analyzed using propositional logic constraints. We examine whether this approach can identify patterns in prompt evolution, detect struggling students, and provide insights into effective and ineffective strategies. Method. We introduce Prompt2Constraints, a novel method that translates students prompts into logical constraints. The constraints are able to represent the intent of the prompts in succinct and quantifiable ways. We used this approach to analyze a dataset of 1,872 prompts from 203 students solving introductory programming tasks. Findings. We find that while successful and unsuccessful attempts tend to use a similar number of constraints overall, when students fail, they often modify their prompts more significantly, shifting problem-solving strategies midway. We also identify points where specific interventions could be most helpful to students for refining their prompts. Implications. This work offers a new and scalable way to detect students who struggle in solving natural language programming tasks. This work could be extended to investigate more complex tasks and integrated into programming tools to provide real-time support.
Beyond the Hype: A Comprehensive Review of Current Trends in Generative AI Research, Teaching Practices, and Tools
Dec 19, 2024



Generative AI (GenAI) is advancing rapidly, and the literature in computing education is expanding almost as quickly. Initial responses to GenAI tools were mixed between panic and utopian optimism. Many were fast to point out the opportunities and challenges of GenAI. Researchers reported that these new tools are capable of solving most introductory programming tasks and are causing disruptions throughout the curriculum. These tools can write and explain code, enhance error messages, create resources for instructors, and even provide feedback and help for students like a traditional teaching assistant. In 2024, new research started to emerge on the effects of GenAI usage in the computing classroom. These new data involve the use of GenAI to support classroom instruction at scale and to teach students how to code with GenAI. In support of the former, a new class of tools is emerging that can provide personalized feedback to students on their programming assignments or teach both programming and prompting skills at the same time. With the literature expanding so rapidly, this report aims to summarize and explain what is happening on the ground in computing classrooms. We provide a systematic literature review; a survey of educators and industry professionals; and interviews with educators using GenAI in their courses, educators studying GenAI, and researchers who create GenAI tools to support computing education. The triangulation of these methods and data sources expands the understanding of GenAI usage and perceptions at this critical moment for our community.
Breaking the Programming Language Barrier: Multilingual Prompting to Empower Non-Native English Learners
Dec 17, 2024


Non-native English speakers (NNES) face multiple barriers to learning programming. These barriers can be obvious, such as the fact that programming language syntax and instruction are often in English, or more subtle, such as being afraid to ask for help in a classroom full of native English speakers. However, these barriers are frustrating because many NNES students know more about programming than they can articulate in English. Advances in generative AI (GenAI) have the potential to break down these barriers because state of the art models can support interactions in multiple languages. Moreover, recent work has shown that GenAI can be highly accurate at code generation and explanation. In this paper, we provide the first exploration of NNES students prompting in their native languages (Arabic, Chinese, and Portuguese) to generate code to solve programming problems. Our results show that students are able to successfully use their native language to solve programming problems, but not without some difficulty specifying programming terminology and concepts. We discuss the challenges they faced, the implications for practice in the short term, and how this might transform computing education globally in the long term.
Seeing the Forest and the Trees: Solving Visual Graph and Tree Based Data Structure Problems using Large Multimodal Models
Dec 15, 2024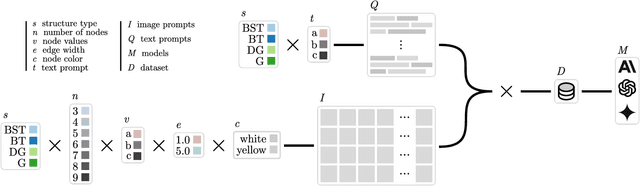

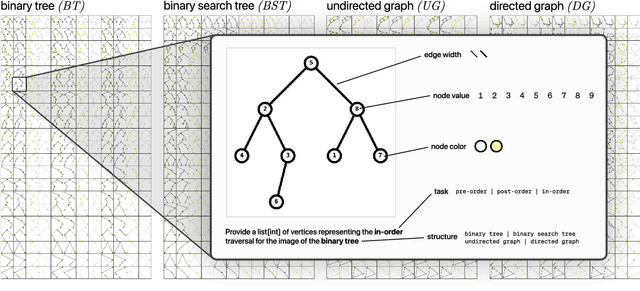

Recent advancements in generative AI systems have raised concerns about academic integrity among educators. Beyond excelling at solving programming problems and text-based multiple-choice questions, recent research has also found that large multimodal models (LMMs) can solve Parsons problems based only on an image. However, such problems are still inherently text-based and rely on the capabilities of the models to convert the images of code blocks to their corresponding text. In this paper, we further investigate the capabilities of LMMs to solve graph and tree data structure problems based only on images. To achieve this, we computationally construct and evaluate a novel benchmark dataset comprising 9,072 samples of diverse graph and tree data structure tasks to assess the performance of the GPT-4o, GPT-4v, Gemini 1.5 Pro, Gemini 1.5 Flash, Gemini 1.0 Pro Vision, and Claude 3 model families. GPT-4o and Gemini 1.5 Flash performed best on trees and graphs respectively. GPT-4o achieved 87.6% accuracy on tree samples, while Gemini 1.5 Flash, achieved 56.2% accuracy on graph samples. Our findings highlight the influence of structural and visual variations on model performance. This research not only introduces an LMM benchmark to facilitate replication and further exploration but also underscores the potential of LMMs in solving complex computing problems, with important implications for pedagogy and assessment practices.
Integrating Natural Language Prompting Tasks in Introductory Programming Courses
Oct 04, 2024



Introductory programming courses often emphasize mastering syntax and basic constructs before progressing to more complex and interesting programs. This bottom-up approach can be frustrating for novices, shifting the focus away from problem solving and potentially making computing less appealing to a broad range of students. The rise of generative AI for code production could partially address these issues by fostering new skills via interaction with AI models, including constructing high-level prompts and evaluating code that is automatically generated. In this experience report, we explore the inclusion of two prompt-focused activities in an introductory course, implemented across four labs in a six-week module. The first requires students to solve computational problems by writing natural language prompts, emphasizing problem-solving over syntax. The second involves students crafting prompts to generate code equivalent to provided fragments, to foster an understanding of the relationship between prompts and code. Most of the students in the course had reported finding programming difficult to learn, often citing frustrations with syntax and debugging. We found that self-reported difficulty with learning programming had a strong inverse relationship with performance on traditional programming assessments such as tests and projects, as expected. However, performance on the natural language tasks was less strongly related to self-reported difficulty, suggesting they may target different skills. Learning how to communicate with AI coding models is becoming an important skill, and natural language prompting tasks may appeal to a broad range of students.
The Widening Gap: The Benefits and Harms of Generative AI for Novice Programmers
May 28, 2024
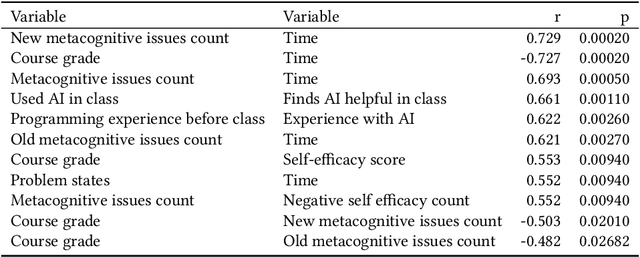


Novice programmers often struggle through programming problem solving due to a lack of metacognitive awareness and strategies. Previous research has shown that novices can encounter multiple metacognitive difficulties while programming. Novices are typically unaware of how these difficulties are hindering their progress. Meanwhile, many novices are now programming with generative AI (GenAI), which can provide complete solutions to most introductory programming problems, code suggestions, hints for next steps when stuck, and explain cryptic error messages. Its impact on novice metacognition has only started to be explored. Here we replicate a previous study that examined novice programming problem solving behavior and extend it by incorporating GenAI tools. Through 21 lab sessions consisting of participant observation, interview, and eye tracking, we explore how novices are coding with GenAI tools. Although 20 of 21 students completed the assigned programming problem, our findings show an unfortunate divide in the use of GenAI tools between students who accelerated and students who struggled. Students who accelerated were able to use GenAI to create code they already intended to make and were able to ignore unhelpful or incorrect inline code suggestions. But for students who struggled, our findings indicate that previously known metacognitive difficulties persist, and that GenAI unfortunately can compound them and even introduce new metacognitive difficulties. Furthermore, struggling students often expressed cognitive dissonance about their problem solving ability, thought they performed better than they did, and finished with an illusion of competence. Based on our observations from both groups, we propose ways to scaffold the novice GenAI experience and make suggestions for future work.
Generative AI in Education: A Study of Educators' Awareness, Sentiments, and Influencing Factors
Mar 22, 2024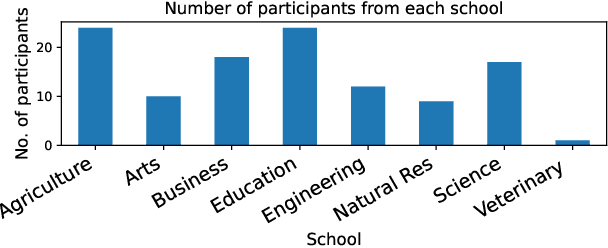

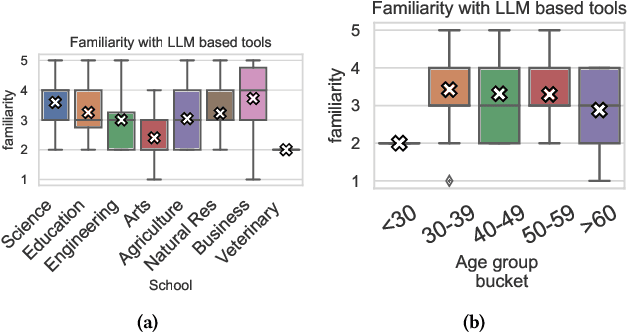

The rapid advancement of artificial intelligence (AI) and the expanding integration of large language models (LLMs) have ignited a debate about their application in education. This study delves into university instructors' experiences and attitudes toward AI language models, filling a gap in the literature by analyzing educators' perspectives on AI's role in the classroom and its potential impacts on teaching and learning. The objective of this research is to investigate the level of awareness, overall sentiment towardsadoption, and the factors influencing these attitudes for LLMs and generative AI-based tools in higher education. Data was collected through a survey using a Likert scale, which was complemented by follow-up interviews to gain a more nuanced understanding of the instructors' viewpoints. The collected data was processed using statistical and thematic analysis techniques. Our findings reveal that educators are increasingly aware of and generally positive towards these tools. We find no correlation between teaching style and attitude toward generative AI. Finally, while CS educators show far more confidence in their technical understanding of generative AI tools and more positivity towards them than educators in other fields, they show no more confidence in their ability to detect AI-generated work.
Interactions with Prompt Problems: A New Way to Teach Programming with Large Language Models
Jan 19, 2024Large Language Models (LLMs) have upended decades of pedagogy in computing education. Students previously learned to code through \textit{writing} many small problems with less emphasis on code reading and comprehension. Recent research has shown that free code generation tools powered by LLMs can solve introductory programming problems presented in natural language with ease. In this paper, we propose a new way to teach programming with Prompt Problems. Students receive a problem visually, indicating how input should be transformed to output, and must translate that to a prompt for an LLM to decipher. The problem is considered correct when the code that is generated by the student prompt can pass all test cases. In this paper we present the design of this tool, discuss student interactions with it as they learn, and provide insights into this new class of programming problems as well as the design tools that integrate LLMs.
The Robots are Here: Navigating the Generative AI Revolution in Computing Education
Oct 01, 2023



Recent advancements in artificial intelligence (AI) are fundamentally reshaping computing, with large language models (LLMs) now effectively being able to generate and interpret source code and natural language instructions. These emergent capabilities have sparked urgent questions in the computing education community around how educators should adapt their pedagogy to address the challenges and to leverage the opportunities presented by this new technology. In this working group report, we undertake a comprehensive exploration of LLMs in the context of computing education and make five significant contributions. First, we provide a detailed review of the literature on LLMs in computing education and synthesise findings from 71 primary articles. Second, we report the findings of a survey of computing students and instructors from across 20 countries, capturing prevailing attitudes towards LLMs and their use in computing education contexts. Third, to understand how pedagogy is already changing, we offer insights collected from in-depth interviews with 22 computing educators from five continents who have already adapted their curricula and assessments. Fourth, we use the ACM Code of Ethics to frame a discussion of ethical issues raised by the use of large language models in computing education, and we provide concrete advice for policy makers, educators, and students. Finally, we benchmark the performance of LLMs on various computing education datasets, and highlight the extent to which the capabilities of current models are rapidly improving. Our aim is that this report will serve as a focal point for both researchers and practitioners who are exploring, adapting, using, and evaluating LLMs and LLM-based tools in computing classrooms.
Promptly: Using Prompt Problems to Teach Learners How to Effectively Utilize AI Code Generators
Jul 31, 2023



With their remarkable ability to generate code, large language models (LLMs) are a transformative technology for computing education practice. They have created an urgent need for educators to rethink pedagogical approaches and teaching strategies for newly emerging skill sets. Traditional approaches to learning programming have focused on frequent and repeated practice at writing code. The ease with which code can now be generated has resulted in a shift in focus towards reading, understanding and evaluating LLM-generated code. In parallel with this shift, a new essential skill is emerging -- the ability to construct good prompts for code-generating models. This paper introduces a novel pedagogical concept known as a `Prompt Problem', designed to help students learn how to craft effective prompts for LLMs. A Prompt Problem challenges a student to create a natural language prompt that leads an LLM to produce the correct code for a specific problem. To support the delivery of Prompt Problems at scale, in this paper we also present a novel tool called Promptly which hosts a repository of Prompt Problems and automates the evaluation of prompt-generated code. We report empirical findings from a field study in which Promptly was deployed in a first-year Python programming course (n=54). We explore student interactions with the tool and their perceptions of the Prompt Problem concept. We found that Promptly was largely well-received by students for its ability to engage their computational thinking skills and expose them to new programming constructs. We also discuss avenues for future work, including variations on the design of Prompt Problems and the need to study their integration into the curriculum and teaching practice.