 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"All Roads Lead to ChatGPT": How Generative AI is Eroding Social Interactions and Student Learning Communities
Apr 14, 2025The widespread adoption of generative AI is already impacting learning and help-seeking. While the benefits of generative AI are well-understood, recent studies have also raised concerns about increased potential for cheating and negative impacts on students' metacognition and critical thinking. However, the potential impacts on social interactions, peer learning, and classroom dynamics are not yet well understood. To investigate these aspects, we conducted 17 semi-structured interviews with undergraduate computing students across seven R1 universities in North America. Our findings suggest that help-seeking requests are now often mediated by generative AI. For example, students often redirected questions from their peers to generative AI instead of providing assistance themselves, undermining peer interaction. Students also reported feeling increasingly isolated and demotivated as the social support systems they rely on begin to break down. These findings are concerning given the important role that social interactions play in students' learning and sense of belonging.
The Role of Generative AI in Software Student CollaborAItion
Jan 23, 2025Collaboration is a crucial part of computing education. The increase in AI capabilities over the last couple of years is bound to profoundly affect all aspects of systems and software engineering, including collaboration. In this position paper, we consider a scenario where AI agents would be able to take on any role in collaborative processes in computing education. We outline these roles, the activities and group dynamics that software development currently include, and discuss if and in what way AI could facilitate these roles and activities. The goal of our work is to envision and critically examine potential futures. We present scenarios suggesting how AI can be integrated into existing collaborations. These are contrasted by design fictions that help demonstrate the new possibilities and challenges for computing education in the AI era.
The Evolving Usage of GenAI by Computing Students
Dec 21, 2024

Help-seeking is a critical aspect of learning and problem-solving for computing students. Recent research has shown that many students are aware of generative AI (GenAI) tools; however, there are gaps in the extent and effectiveness of how students use them. With over two years of widespread GenAI usage, it is crucial to understand whether students' help-seeking behaviors with these tools have evolved and how. This paper presents findings from a repeated cross-sectional survey conducted among computing students across North American universities (n=95). Our results indicate shifts in GenAI usage patterns. In 2023, 34.1% of students (n=47) reported never using ChatGPT for help, ranking it fourth after online searches, peer support, and class forums. By 2024, this figure dropped sharply to 6.3% (n=48), with ChatGPT nearly matching online search as the most commonly used help resource. Despite this growing prevalence, there has been a decline in students' hourly and daily usage of GenAI tools, which may be attributed to a common tendency to underestimate usage frequency. These findings offer new insights into the evolving role of GenAI in computing education, highlighting its increasing acceptance and solidifying its position as a key help resource.
Beyond the Hype: A Comprehensive Review of Current Trends in Generative AI Research, Teaching Practices, and Tools
Dec 19, 2024



Generative AI (GenAI) is advancing rapidly, and the literature in computing education is expanding almost as quickly. Initial responses to GenAI tools were mixed between panic and utopian optimism. Many were fast to point out the opportunities and challenges of GenAI. Researchers reported that these new tools are capable of solving most introductory programming tasks and are causing disruptions throughout the curriculum. These tools can write and explain code, enhance error messages, create resources for instructors, and even provide feedback and help for students like a traditional teaching assistant. In 2024, new research started to emerge on the effects of GenAI usage in the computing classroom. These new data involve the use of GenAI to support classroom instruction at scale and to teach students how to code with GenAI. In support of the former, a new class of tools is emerging that can provide personalized feedback to students on their programming assignments or teach both programming and prompting skills at the same time. With the literature expanding so rapidly, this report aims to summarize and explain what is happening on the ground in computing classrooms. We provide a systematic literature review; a survey of educators and industry professionals; and interviews with educators using GenAI in their courses, educators studying GenAI, and researchers who create GenAI tools to support computing education. The triangulation of these methods and data sources expands the understanding of GenAI usage and perceptions at this critical moment for our community.
Breaking the Programming Language Barrier: Multilingual Prompting to Empower Non-Native English Learners
Dec 17, 2024


Non-native English speakers (NNES) face multiple barriers to learning programming. These barriers can be obvious, such as the fact that programming language syntax and instruction are often in English, or more subtle, such as being afraid to ask for help in a classroom full of native English speakers. However, these barriers are frustrating because many NNES students know more about programming than they can articulate in English. Advances in generative AI (GenAI) have the potential to break down these barriers because state of the art models can support interactions in multiple languages. Moreover, recent work has shown that GenAI can be highly accurate at code generation and explanation. In this paper, we provide the first exploration of NNES students prompting in their native languages (Arabic, Chinese, and Portuguese) to generate code to solve programming problems. Our results show that students are able to successfully use their native language to solve programming problems, but not without some difficulty specifying programming terminology and concepts. We discuss the challenges they faced, the implications for practice in the short term, and how this might transform computing education globally in the long term.
Seeing the Forest and the Trees: Solving Visual Graph and Tree Based Data Structure Problems using Large Multimodal Models
Dec 15, 2024

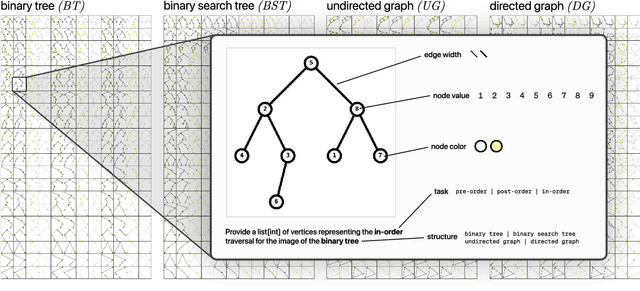

Recent advancements in generative AI systems have raised concerns about academic integrity among educators. Beyond excelling at solving programming problems and text-based multiple-choice questions, recent research has also found that large multimodal models (LMMs) can solve Parsons problems based only on an image. However, such problems are still inherently text-based and rely on the capabilities of the models to convert the images of code blocks to their corresponding text. In this paper, we further investigate the capabilities of LMMs to solve graph and tree data structure problems based only on images. To achieve this, we computationally construct and evaluate a novel benchmark dataset comprising 9,072 samples of diverse graph and tree data structure tasks to assess the performance of the GPT-4o, GPT-4v, Gemini 1.5 Pro, Gemini 1.5 Flash, Gemini 1.0 Pro Vision, and Claude 3 model families. GPT-4o and Gemini 1.5 Flash performed best on trees and graphs respectively. GPT-4o achieved 87.6% accuracy on tree samples, while Gemini 1.5 Flash, achieved 56.2% accuracy on graph samples. Our findings highlight the influence of structural and visual variations on model performance. This research not only introduces an LMM benchmark to facilitate replication and further exploration but also underscores the potential of LMMs in solving complex computing problems, with important implications for pedagogy and assessment practices.
Synthetic Students: A Comparative Study of Bug Distribution Between Large Language Models and Computing Students
Oct 11, 2024



Large language models (LLMs) present an exciting opportunity for generating synthetic classroom data. Such data could include code containing a typical distribution of errors, simulated student behaviour to address the cold start problem when developing education tools, and synthetic user data when access to authentic data is restricted due to privacy reasons. In this research paper, we conduct a comparative study examining the distribution of bugs generated by LLMs in contrast to those produced by computing students. Leveraging data from two previous large-scale analyses of student-generated bugs, we investigate whether LLMs can be coaxed to exhibit bug patterns that are similar to authentic student bugs when prompted to inject errors into code. The results suggest that unguided, LLMs do not generate plausible error distributions, and many of the generated errors are unlikely to be generated by real students. However, with guidance including descriptions of common errors and typical frequencies, LLMs can be shepherded to generate realistic distributions of errors in synthetic code.
Integrating Natural Language Prompting Tasks in Introductory Programming Courses
Oct 04, 2024



Introductory programming courses often emphasize mastering syntax and basic constructs before progressing to more complex and interesting programs. This bottom-up approach can be frustrating for novices, shifting the focus away from problem solving and potentially making computing less appealing to a broad range of students. The rise of generative AI for code production could partially address these issues by fostering new skills via interaction with AI models, including constructing high-level prompts and evaluating code that is automatically generated. In this experience report, we explore the inclusion of two prompt-focused activities in an introductory course, implemented across four labs in a six-week module. The first requires students to solve computational problems by writing natural language prompts, emphasizing problem-solving over syntax. The second involves students crafting prompts to generate code equivalent to provided fragments, to foster an understanding of the relationship between prompts and code. Most of the students in the course had reported finding programming difficult to learn, often citing frustrations with syntax and debugging. We found that self-reported difficulty with learning programming had a strong inverse relationship with performance on traditional programming assessments such as tests and projects, as expected. However, performance on the natural language tasks was less strongly related to self-reported difficulty, suggesting they may target different skills. Learning how to communicate with AI coding models is becoming an important skill, and natural language prompting tasks may appeal to a broad range of students.
The Widening Gap: The Benefits and Harms of Generative AI for Novice Programmers
May 28, 2024Novice programmers often struggle through programming problem solving due to a lack of metacognitive awareness and strategies. Previous research has shown that novices can encounter multiple metacognitive difficulties while programming. Novices are typically unaware of how these difficulties are hindering their progress. Meanwhile, many novices are now programming with generative AI (GenAI), which can provide complete solutions to most introductory programming problems, code suggestions, hints for next steps when stuck, and explain cryptic error messages. Its impact on novice metacognition has only started to be explored. Here we replicate a previous study that examined novice programming problem solving behavior and extend it by incorporating GenAI tools. Through 21 lab sessions consisting of participant observation, interview, and eye tracking, we explore how novices are coding with GenAI tools. Although 20 of 21 students completed the assigned programming problem, our findings show an unfortunate divide in the use of GenAI tools between students who accelerated and students who struggled. Students who accelerated were able to use GenAI to create code they already intended to make and were able to ignore unhelpful or incorrect inline code suggestions. But for students who struggled, our findings indicate that previously known metacognitive difficulties persist, and that GenAI unfortunately can compound them and even introduce new metacognitive difficulties. Furthermore, struggling students often expressed cognitive dissonance about their problem solving ability, thought they performed better than they did, and finished with an illusion of competence. Based on our observations from both groups, we propose ways to scaffold the novice GenAI experience and make suggestions for future work.
The Silicon Ceiling: Auditing GPT's Race and Gender Biases in Hiring
May 09, 2024



Large language models (LLMs) are increasingly being introduced in workplace settings, with the goals of improving efficiency and fairness. However, concerns have arisen regarding these models' potential to reflect or exacerbate social biases and stereotypes. This study explores the potential impact of LLMs on hiring practices. To do so, we conduct an algorithm audit of race and gender biases in one commonly-used LLM, OpenAI's GPT-3.5, taking inspiration from the history of traditional offline resume audits. We conduct two studies using names with varied race and gender connotations: resume assessment (Study 1) and resume generation (Study 2). In Study 1, we ask GPT to score resumes with 32 different names (4 names for each combination of the 2 gender and 4 racial groups) and two anonymous options across 10 occupations and 3 evaluation tasks (overall rating, willingness to interview, and hireability). We find that the model reflects some biases based on stereotypes. In Study 2, we prompt GPT to create resumes (10 for each name) for fictitious job candidates. When generating resumes, GPT reveals underlying biases; women's resumes had occupations with less experience, while Asian and Hispanic resumes had immigrant markers, such as non-native English and non-U.S. education and work experiences. Our findings contribute to a growing body of literature on LLM biases, in particular when used in workplace contexts.