 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval-Augmented Tutoring for Algorithm Tracing and Problem-Solving in AI Education
May 13, 2026Students learning algorithms often need support as they interpret traces, debug reasoning errors, and apply procedures across unfamiliar problem instances. In this paper, we present KITE (Knowledge-Informed Tutoring Engine), a Retrieval-Augmented Generation (RAG)-based intelligent tutoring system designed to serve as a classroom teaching assistant for algorithmic reasoning and problem-solving tasks. KITE uses an intent-aware Socratic response strategy to tailor support to different student needs, responding with targeted hints, guiding questions, and progressive scaffolding intended to strengthen students' algorithmic problem-solving ability. To keep responses aligned with course content, KITE uses a multimodal RAG pipeline that retrieves relevant information from course materials. We evaluate KITE using three forms of assessment: RAGAs-based metrics for response grounding and quality, expert evaluation of pedagogical quality, and a simulated student pipeline in which a weaker language model interacts with KITE across two-turn dialogues and produces revised answers after receiving feedback. Results indicate that KITE produces contextually grounded and pedagogically appropriate responses. Further, using simulated students, KITE's feedback helped the student models produce more accurate follow-up responses on procedural and tracing questions, suggesting that its scaffolding can support algorithmic problem-solving. This work contributes a tutoring architecture and an evaluation approach for assessing retrieval-grounded explanations and scaffolded problem-solving feedback.
AI-Generated Slides: Are They Good? Can Students Tell?
May 13, 2026As generative AI (GenAI) tools become easily accessible, there is promise in using such tools to support instructors. To that end, this paper examines using GenAI to help generate slides from instructor authored course notes, emphasizing instructor and student perceptions. We examine an end-to-end education tool (NotebookLM), two general-purpose LLMs (Claude, M365 Copilot), and two coding assistants (Cursor, Claude Code). We first analyze whether GenAI generated slides are ``good'' via narrative assessment by educators. We choose the best slides to use (with some modification) in a real course setting, and compare the student perception of human vs. AI generated slides. We find that coding assistant tools produce slides that were most accurate, complete, and pedagogically sound. Additionally, students rate GenAI slides to be of similar quality as instructor-created slides, and cannot reliably identify which slides are AI-generated. Additionally, we find a negative correlation between a high quality rating and a high ``AI-generated'' rating, suggesting students associate poor quality with the source of the slides being AI. These findings highlight promising opportunities for integrating GenAI into instructional design workflows and call for further research on how educators can best harness such tools responsibly and effectively.
The Missing Evaluation Axis: What 10,000 Student Submissions Reveal About AI Tutor Effectiveness
May 07, 2026Current Artificial Intelligence (AI)-based tutoring systems (AI tutors) are primarily evaluated based on the pedagogical quality of their feedback messages. While important, pedagogy alone is insufficient because it ignores a critical question: what do students actually do with the feedback they receive? We argue that AI tutor evaluation should be extended with a behavioral dimension grounded in student interaction data, which complements pedagogical assessment. We propose an evaluation framework and apply it to 10,235 code submissions with corresponding AI tutor feedback from an introductory undergraduate programming course to measure whether students act on tutor feedback and whether those actions are applied correctly. Using this framework to compare two deployed AI tutors across different semesters in a large-scale introductory computer science course reveals substantial differences in student engagement patterns that are not captured by pedagogy-only evaluation. Moreover, these engagement-based behavioral signals are more strongly associated with student perception of helpful feedback than pedagogical quality alone, providing a more complete and actionable picture of AI tutor performance.
Personalized Worked Example Generation from Student Code Submissions using Pattern-based Knowledge Components
Apr 27, 2026Adaptive programming practice often relies on fixed libraries of worked examples and practice problems, which require substantial authoring effort and may not correspond well to the logical errors and partial solutions students produce while writing code. As a result, students may receive learning content that does not directly address the concepts they are working to understand, while instructors must either invest additional effort in expanding content libraries or accept a coarse level of personalization. We present an approach for knowledge-component (KC) guided educational content generation using pattern-based KCs extracted from student code. Given a problem statement and student submissions, our pipeline extracts recurring structural KC patterns from students' code through AST-based analysis and uses them to condition a generative model. In this study, we apply this approach to worked example generation, and compare baseline and KC-conditioned outputs through expert evaluation. Results suggest that KC-conditioned generation improves topical focus and relevance to learners' underlying logical errors, providing evidence that KC-based steering of generative models can support personalized learning at scale.
Teaching Language Models How to Code Like Learners: Conversational Serialization for Student Simulation
Apr 12, 2026Artificial models that simulate how learners act and respond within educational systems are a promising tool for evaluating tutoring strategies and feedback mechanisms at scale. However, many existing approaches in programming education rely on prompting large, proprietary language models, raising concerns around privacy, cost, and dependence. In this work, we propose a method for training open-weight artificial programming learners using authentic student process data. Our approach serializes temporal log traces into a conversational format, representing each student's problem-solving process as a dialogue between the learner and their automated assessment system. Student code submissions and environment feedback, such as test outcomes, grades, and error traces, form alternating conversational turns, enabling models to learn from the iterative debugging process. We additionally introduce a training pipeline combining supervised fine-tuning with preference optimization to align models with authentic student debugging behavior. We evaluate our framework by training Qwen models at 4B and 8B scales on a large-scale dataset of real student submissions to Python programming assignments. Our results show that incorporating environment feedback strengthens the models' ability to replicate student debugging behavior, improving over both prior code-only approaches and prompted large language models baselines in functional alignment and code similarity. We release our code to support reproducibility.
Can We Improve Educational Diagram Generation with In-Context Examples? Not if a Hallucination Spoils the Bunch
Jan 28, 2026Generative artificial intelligence (AI) has found a widespread use in computing education; at the same time, quality of generated materials raises concerns among educators and students. This study addresses this issue by introducing a novel method for diagram code generation with in-context examples based on the Rhetorical Structure Theory (RST), which aims to improve diagram generation by aligning models' output with user expectations. Our approach is evaluated by computer science educators, who assessed 150 diagrams generated with large language models (LLMs) for logical organization, connectivity, layout aesthetic, and AI hallucination. The assessment dataset is additionally investigated for its utility in automated diagram evaluation. The preliminary results suggest that our method decreases the rate of factual hallucination and improves diagram faithfulness to provided context; however, due to LLMs' stochasticity, the quality of the generated diagrams varies. Additionally, we present an in-depth analysis and discussion on the connection between AI hallucination and the quality of generated diagrams, which reveals that text contexts of higher complexity lead to higher rates of hallucination and LLMs often fail to detect mistakes in their output.
How Large Language Models Are Changing MOOC Essay Answers: A Comparison of Pre- and Post-LLM Responses
Apr 17, 2025The release of ChatGPT in late 2022 caused a flurry of activity and concern in the academic and educational communities. Some see the tool's ability to generate human-like text that passes at least cursory inspections for factual accuracy ``often enough'' a golden age of information retrieval and computer-assisted learning. Some, on the other hand, worry the tool may lead to unprecedented levels of academic dishonesty and cheating. In this work, we quantify some of the effects of the emergence of Large Language Models (LLMs) on online education by analyzing a multi-year dataset of student essay responses from a free university-level MOOC on AI ethics. Our dataset includes essays submitted both before and after ChatGPT's release. We find that the launch of ChatGPT coincided with significant changes in both the length and style of student essays, mirroring observations in other contexts such as academic publishing. We also observe -- as expected based on related public discourse -- changes in prevalence of key content words related to AI and LLMs, but not necessarily the general themes or topics discussed in the student essays as identified through (dynamic) topic modeling.
On the Opportunities of Large Language Models for Programming Process Data
Nov 01, 2024

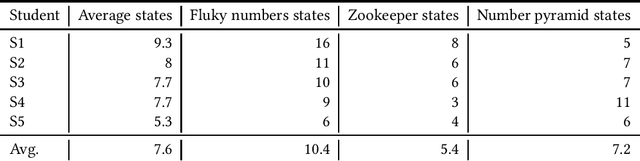

Computing educators and researchers have used programming process data to understand how programs are constructed and what sorts of problems students struggle with. Although such data shows promise for using it for feedback, fully automated programming process feedback systems have still been an under-explored area. The recent emergence of large language models (LLMs) have yielded additional opportunities for researchers in a wide variety of fields. LLMs are efficient at transforming content from one format to another, leveraging the body of knowledge they have been trained with in the process. In this article, we discuss opportunities of using LLMs for analyzing programming process data. To complement our discussion, we outline a case study where we have leveraged LLMs for automatically summarizing the programming process and for creating formative feedback on the programming process. Overall, our discussion and findings highlight that the computing education research and practice community is again one step closer to automating formative programming process-focused feedback.
Comparing the Utility, Preference, and Performance of Course Material Search Functionality and Retrieval-Augmented Generation Large Language Model (RAG-LLM) AI Chatbots in Information-Seeking Tasks
Oct 17, 2024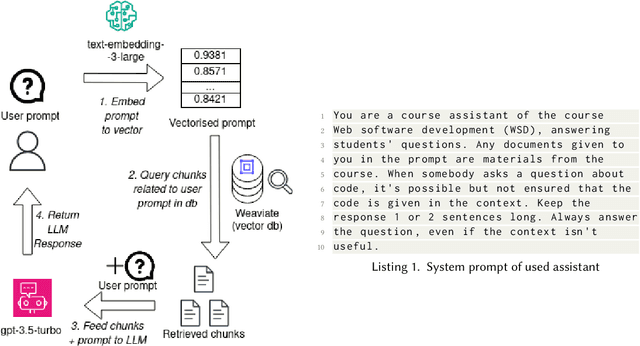

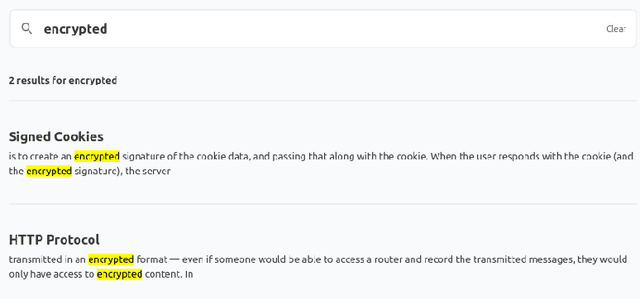
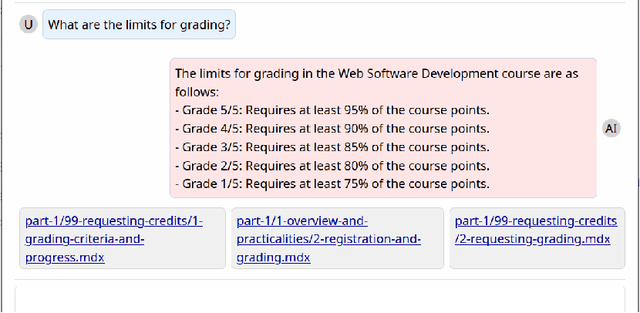
Providing sufficient support for students requires substantial resources, especially considering the growing enrollment numbers. Students need help in a variety of tasks, ranging from information-seeking to requiring support with course assignments. To explore the utility of recent large language models (LLMs) as a support mechanism, we developed an LLM-powered AI chatbot that augments the answers that are produced with information from the course materials. To study the effect of the LLM-powered AI chatbot, we conducted a lab-based user study (N=14), in which the participants worked on tasks from a web software development course. The participants were divided into two groups, where one of the groups first had access to the chatbot and then to a more traditional search functionality, while another group started with the search functionality and was then given the chatbot. We assessed the participants' performance and perceptions towards the chatbot and the search functionality and explored their preferences towards the support functionalities. Our findings highlight that both support mechanisms are seen as useful and that support mechanisms work well for specific tasks, while less so for other tasks. We also observe that students tended to prefer the second support mechanism more, where students who were first given the chatbot tended to prefer the search functionality and vice versa.
Synthetic Students: A Comparative Study of Bug Distribution Between Large Language Models and Computing Students
Oct 11, 2024



Large language models (LLMs) present an exciting opportunity for generating synthetic classroom data. Such data could include code containing a typical distribution of errors, simulated student behaviour to address the cold start problem when developing education tools, and synthetic user data when access to authentic data is restricted due to privacy reasons. In this research paper, we conduct a comparative study examining the distribution of bugs generated by LLMs in contrast to those produced by computing students. Leveraging data from two previous large-scale analyses of student-generated bugs, we investigate whether LLMs can be coaxed to exhibit bug patterns that are similar to authentic student bugs when prompted to inject errors into code. The results suggest that unguided, LLMs do not generate plausible error distributions, and many of the generated errors are unlikely to be generated by real students. However, with guidance including descriptions of common errors and typical frequencies, LLMs can be shepherded to generate realistic distributions of errors in synthetic code.