 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation Cards: An Interpretive Layer for AI Evaluation Reporting
Jun 09, 2026AI evaluation results are produced at scale but reported inconsistently across leaderboards, model cards, benchmark papers, and company blogs. The cost is interpretive: readers cannot reliably compare results across sources, identify what a report omits, or trace an aggregate claim to its underlying evidence. Recent efforts address isolated components but leave three gaps: they cover only narrow slices of the evaluation lifecycle and do not compose into a single interpretable record; they specify static representations that do not differentiate the questions different stakeholders bring to the same evidence; and they remain proposals on paper, lacking the extraction infrastructure required for adoption at scale. We present \EvalCards{}, an operational reporting layer that composes benchmark metadata, evaluation run data, and model metadata into a unified record. We (1) derive a reporting schema from a structured review of 52 papers and 10 stakeholder interviews, (2) implement four interpretive signals (reproducibility, documentation completeness, provenance and risk, and score comparability), rendered through reader modes calibrated to research and non-research audiences, and (3) deploy a monitoring tool that applies \EvalCards{} across 5,816 models, 635 benchmarks, and 101,843 results, surfacing systematic gaps in current reporting practice.
Who Evaluates AI's Social Impacts? Mapping Coverage and Gaps in First and Third Party Evaluations
Nov 06, 2025



Foundation models are increasingly central to high-stakes AI systems, and governance frameworks now depend on evaluations to assess their risks and capabilities. Although general capability evaluations are widespread, social impact assessments covering bias, fairness, privacy, environmental costs, and labor practices remain uneven across the AI ecosystem. To characterize this landscape, we conduct the first comprehensive analysis of both first-party and third-party social impact evaluation reporting across a wide range of model developers. Our study examines 186 first-party release reports and 183 post-release evaluation sources, and complements this quantitative analysis with interviews of model developers. We find a clear division of evaluation labor: first-party reporting is sparse, often superficial, and has declined over time in key areas such as environmental impact and bias, while third-party evaluators including academic researchers, nonprofits, and independent organizations provide broader and more rigorous coverage of bias, harmful content, and performance disparities. However, this complementarity has limits. Only model developers can authoritatively report on data provenance, content moderation labor, financial costs, and training infrastructure, yet interviews reveal that these disclosures are often deprioritized unless tied to product adoption or regulatory compliance. Our findings indicate that current evaluation practices leave major gaps in assessing AI's societal impacts, highlighting the urgent need for policies that promote developer transparency, strengthen independent evaluation ecosystems, and create shared infrastructure to aggregate and compare third-party evaluations in a consistent and accessible way.
TreeMatch: A Fully Unsupervised WSD System Using Dependency Knowledge on a Specific Domain
Jan 05, 2025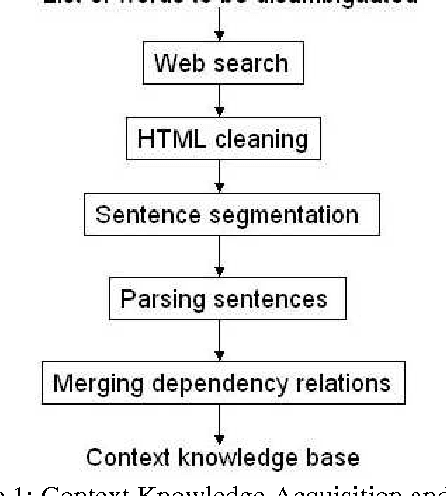
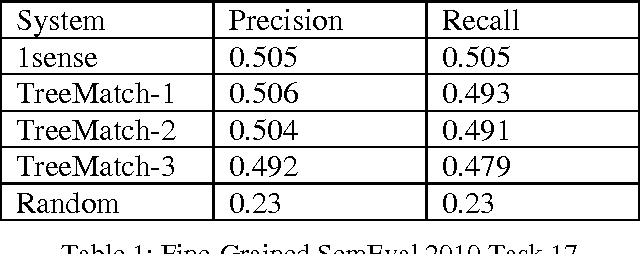
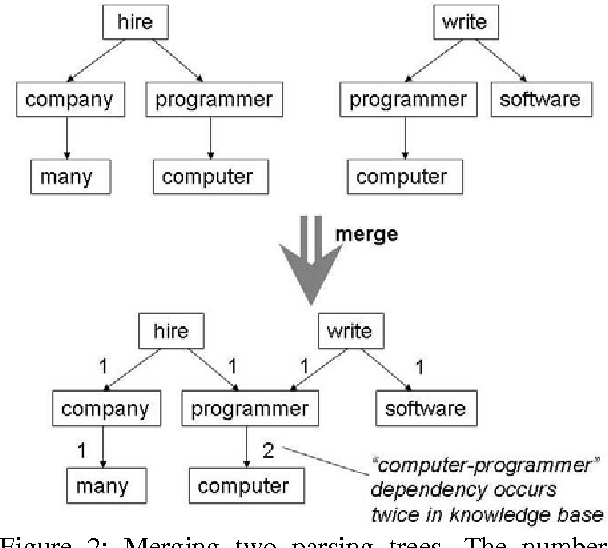
Word sense disambiguation (WSD) is one of the main challenges in Computational Linguistics. TreeMatch is a WSD system originally developed using data from SemEval 2007 Task 7 (Coarse-grained English All-words Task) that has been adapted for use in SemEval 2010 Task 17 (All-words Word Sense Disambiguation on a Specific Domain). The system is based on a fully unsupervised method using dependency knowledge drawn from a domain specific knowledge base that was built for this task. When evaluated on the task, the system precision performs above the Most Frequent Selection baseline.
Decoding Logic Errors: A Comparative Study on Bug Detection by Students and Large Language Models
Nov 27, 2023Identifying and resolving logic errors can be one of the most frustrating challenges for novices programmers. Unlike syntax errors, for which a compiler or interpreter can issue a message, logic errors can be subtle. In certain conditions, buggy code may even exhibit correct behavior -- in other cases, the issue might be about how a problem statement has been interpreted. Such errors can be hard to spot when reading the code, and they can also at times be missed by automated tests. There is great educational potential in automatically detecting logic errors, especially when paired with suitable feedback for novices. Large language models (LLMs) have recently demonstrated surprising performance for a range of computing tasks, including generating and explaining code. These capabilities are closely linked to code syntax, which aligns with the next token prediction behavior of LLMs. On the other hand, logic errors relate to the runtime performance of code and thus may not be as well suited to analysis by LLMs. To explore this, we investigate the performance of two popular LLMs, GPT-3 and GPT-4, for detecting and providing a novice-friendly explanation of logic errors. We compare LLM performance with a large cohort of introductory computing students $(n=964)$ solving the same error detection task. Through a mixed-methods analysis of student and model responses, we observe significant improvement in logic error identification between the previous and current generation of LLMs, and find that both LLM generations significantly outperform students. We outline how such models could be integrated into computing education tools, and discuss their potential for supporting students when learning programming.
GersteinLab at MEDIQA-Chat 2023: Clinical Note Summarization from Doctor-Patient Conversations through Fine-tuning and In-context Learning
May 08, 2023This paper presents our contribution to the MEDIQA-2023 Dialogue2Note shared task, encompassing both subtask A and subtask B. We approach the task as a dialogue summarization problem and implement two distinct pipelines: (a) a fine-tuning of a pre-trained dialogue summarization model and GPT-3, and (b) few-shot in-context learning (ICL) using a large language model, GPT-4. Both methods achieve excellent results in terms of ROUGE-1 F1, BERTScore F1 (deberta-xlarge-mnli), and BLEURT, with scores of 0.4011, 0.7058, and 0.5421, respectively. Additionally, we predict the associated section headers using RoBERTa and SciBERT based classification models. Our team ranked fourth among all teams, while each team is allowed to submit three runs as part of their submission. We also utilize expert annotations to demonstrate that the notes generated through the ICL GPT-4 are better than all other baselines. The code for our submission is available.
Comparing Code Explanations Created by Students and Large Language Models
Apr 08, 2023Reasoning about code and explaining its purpose are fundamental skills for computer scientists. There has been extensive research in the field of computing education on the relationship between a student's ability to explain code and other skills such as writing and tracing code. In particular, the ability to describe at a high-level of abstraction how code will behave over all possible inputs correlates strongly with code writing skills. However, developing the expertise to comprehend and explain code accurately and succinctly is a challenge for many students. Existing pedagogical approaches that scaffold the ability to explain code, such as producing exemplar code explanations on demand, do not currently scale well to large classrooms. The recent emergence of powerful large language models (LLMs) may offer a solution. In this paper, we explore the potential of LLMs in generating explanations that can serve as examples to scaffold students' ability to understand and explain code. To evaluate LLM-created explanations, we compare them with explanations created by students in a large course ($n \approx 1000$) with respect to accuracy, understandability and length. We find that LLM-created explanations, which can be produced automatically on demand, are rated as being significantly easier to understand and more accurate summaries of code than student-created explanations. We discuss the significance of this finding, and suggest how such models can be incorporated into introductory programming education.