 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-PBE: Assessing Data Privacy in Large Language Models
Aug 23, 2024



Large Language Models (LLMs) have become integral to numerous domains, significantly advancing applications in data management, mining, and analysis. Their profound capabilities in processing and interpreting complex language data, however, bring to light pressing concerns regarding data privacy, especially the risk of unintentional training data leakage. Despite the critical nature of this issue, there has been no existing literature to offer a comprehensive assessment of data privacy risks in LLMs. Addressing this gap, our paper introduces LLM-PBE, a toolkit crafted specifically for the systematic evaluation of data privacy risks in LLMs. LLM-PBE is designed to analyze privacy across the entire lifecycle of LLMs, incorporating diverse attack and defense strategies, and handling various data types and metrics. Through detailed experimentation with multiple LLMs, LLM-PBE facilitates an in-depth exploration of data privacy concerns, shedding light on influential factors such as model size, data characteristics, and evolving temporal dimensions. This study not only enriches the understanding of privacy issues in LLMs but also serves as a vital resource for future research in the field. Aimed at enhancing the breadth of knowledge in this area, the findings, resources, and our full technical report are made available at https://llm-pbe.github.io/, providing an open platform for academic and practical advancements in LLM privacy assessment.
GersteinLab at MEDIQA-Chat 2023: Clinical Note Summarization from Doctor-Patient Conversations through Fine-tuning and In-context Learning
May 08, 2023This paper presents our contribution to the MEDIQA-2023 Dialogue2Note shared task, encompassing both subtask A and subtask B. We approach the task as a dialogue summarization problem and implement two distinct pipelines: (a) a fine-tuning of a pre-trained dialogue summarization model and GPT-3, and (b) few-shot in-context learning (ICL) using a large language model, GPT-4. Both methods achieve excellent results in terms of ROUGE-1 F1, BERTScore F1 (deberta-xlarge-mnli), and BLEURT, with scores of 0.4011, 0.7058, and 0.5421, respectively. Additionally, we predict the associated section headers using RoBERTa and SciBERT based classification models. Our team ranked fourth among all teams, while each team is allowed to submit three runs as part of their submission. We also utilize expert annotations to demonstrate that the notes generated through the ICL GPT-4 are better than all other baselines. The code for our submission is available.
Deep Learning vs. Human Graders for Classifying Severity Levels of Diabetic Retinopathy in a Real-World Nationwide Screening Program
Oct 18, 2018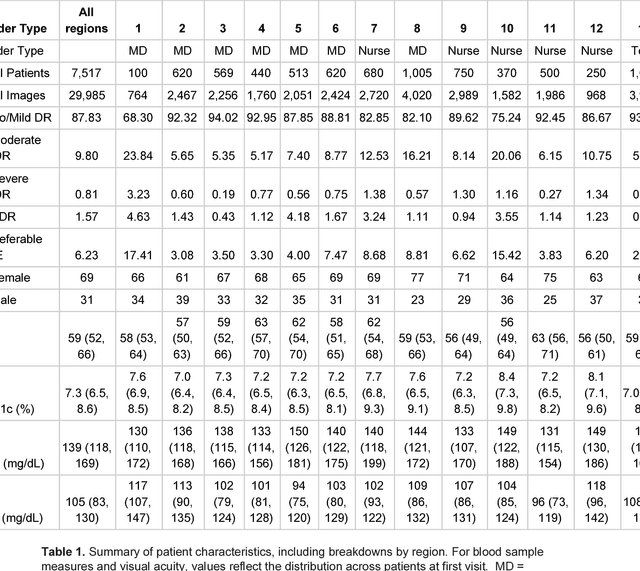
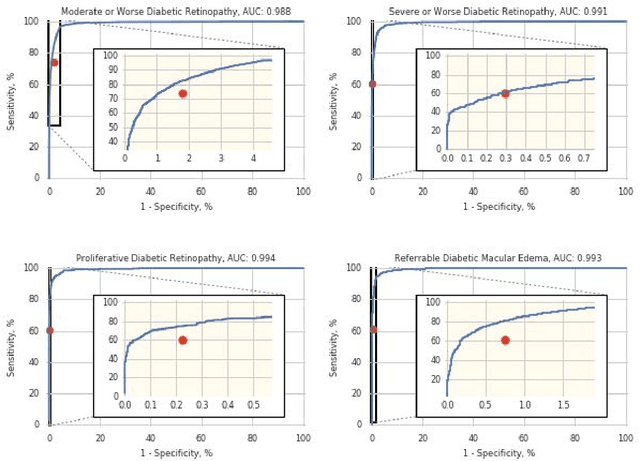
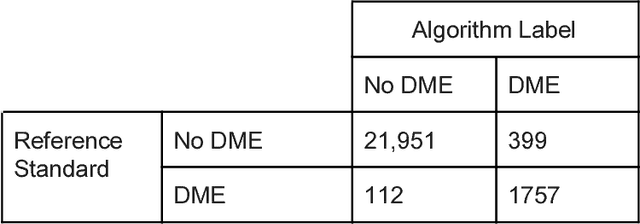
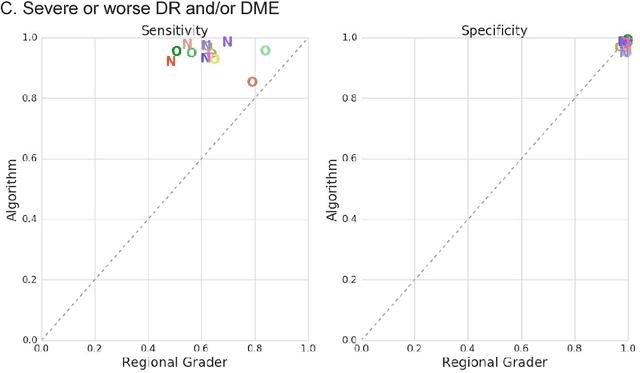
Deep learning algorithms have been used to detect diabetic retinopathy (DR) with specialist-level accuracy. This study aims to validate one such algorithm on a large-scale clinical population, and compare the algorithm performance with that of human graders. 25,326 gradable retinal images of patients with diabetes from the community-based, nation-wide screening program of DR in Thailand were analyzed for DR severity and referable diabetic macular edema (DME). Grades adjudicated by a panel of international retinal specialists served as the reference standard. Across different severity levels of DR for determining referable disease, deep learning significantly reduced the false negative rate (by 23%) at the cost of slightly higher false positive rates (2%). Deep learning algorithms may serve as a valuable tool for DR screening.