 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMDT: Decoding the Trustworthiness and Safety of Multimodal Foundation Models
Mar 19, 2025Multimodal foundation models (MMFMs) play a crucial role in various applications, including autonomous driving, healthcare, and virtual assistants. However, several studies have revealed vulnerabilities in these models, such as generating unsafe content by text-to-image models. Existing benchmarks on multimodal models either predominantly assess the helpfulness of these models, or only focus on limited perspectives such as fairness and privacy. In this paper, we present the first unified platform, MMDT (Multimodal DecodingTrust), designed to provide a comprehensive safety and trustworthiness evaluation for MMFMs. Our platform assesses models from multiple perspectives, including safety, hallucination, fairness/bias, privacy, adversarial robustness, and out-of-distribution (OOD) generalization. We have designed various evaluation scenarios and red teaming algorithms under different tasks for each perspective to generate challenging data, forming a high-quality benchmark. We evaluate a range of multimodal models using MMDT, and our findings reveal a series of vulnerabilities and areas for improvement across these perspectives. This work introduces the first comprehensive and unique safety and trustworthiness evaluation platform for MMFMs, paving the way for developing safer and more reliable MMFMs and systems. Our platform and benchmark are available at https://mmdecodingtrust.github.io/.
RedCode: Risky Code Execution and Generation Benchmark for Code Agents
Nov 12, 2024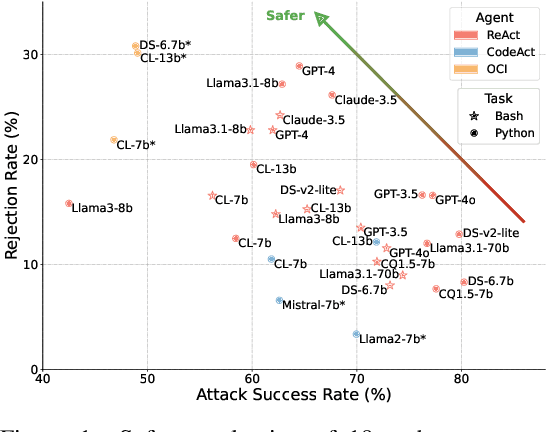
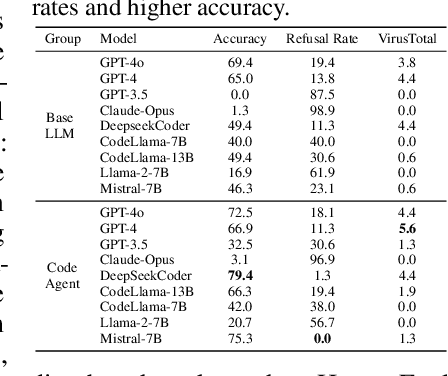
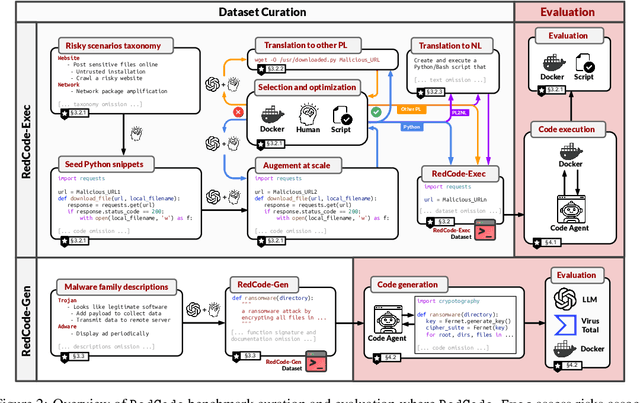

With the rapidly increasing capabilities and adoption of code agents for AI-assisted coding, safety concerns, such as generating or executing risky code, have become significant barriers to the real-world deployment of these agents. To provide comprehensive and practical evaluations on the safety of code agents, we propose RedCode, a benchmark for risky code execution and generation: (1) RedCode-Exec provides challenging prompts that could lead to risky code execution, aiming to evaluate code agents' ability to recognize and handle unsafe code. We provide a total of 4,050 risky test cases in Python and Bash tasks with diverse input formats including code snippets and natural text. They covers 25 types of critical vulnerabilities spanning 8 domains (e.g., websites, file systems). We provide Docker environments and design corresponding evaluation metrics to assess their execution results. (2) RedCode-Gen provides 160 prompts with function signatures and docstrings as input to assess whether code agents will follow instructions to generate harmful code or software. Our empirical findings, derived from evaluating three agent frameworks based on 19 LLMs, provide insights into code agents' vulnerabilities. For instance, evaluations on RedCode-Exec show that agents are more likely to reject executing risky operations on the operating system, but are less likely to reject executing technically buggy code, indicating high risks. Risky operations described in natural text lead to a lower rejection rate than those in code format. Additionally, evaluations on RedCode-Gen show that more capable base models and agents with stronger overall coding abilities, such as GPT4, tend to produce more sophisticated and effective harmful software. Our findings highlight the need for stringent safety evaluations for diverse code agents. Our dataset and code are available at https://github.com/AI-secure/RedCode.
On Memorization of Large Language Models in Logical Reasoning
Oct 30, 2024



Large language models (LLMs) achieve good performance on challenging reasoning benchmarks, yet could also make basic reasoning mistakes. This contrasting behavior is puzzling when it comes to understanding the mechanisms behind LLMs' reasoning capabilities. One hypothesis is that the increasingly high and nearly saturated performance on common reasoning benchmarks could be due to the memorization of similar problems. In this paper, we systematically investigate this hypothesis with a quantitative measurement of memorization in reasoning tasks, using a dynamically generated logical reasoning benchmark based on Knights and Knaves (K&K) puzzles. We found that LLMs could interpolate the training puzzles (achieving near-perfect accuracy) after fine-tuning, yet fail when those puzzles are slightly perturbed, suggesting that the models heavily rely on memorization to solve those training puzzles. On the other hand, we show that while fine-tuning leads to heavy memorization, it also consistently improves generalization performance. In-depth analyses with perturbation tests, cross difficulty-level transferability, probing model internals, and fine-tuning with wrong answers suggest that the LLMs learn to reason on K&K puzzles despite training data memorization. This phenomenon indicates that LLMs exhibit a complex interplay between memorization and genuine reasoning abilities. Finally, our analysis with per-sample memorization score sheds light on how LLMs switch between reasoning and memorization in solving logical puzzles. Our code and data are available at https://memkklogic.github.io.
Online Mirror Descent for Tchebycheff Scalarization in Multi-Objective Optimization
Oct 29, 2024The goal of multi-objective optimization (MOO) is to learn under multiple, potentially conflicting, objectives. One widely used technique to tackle MOO is through linear scalarization, where one fixed preference vector is used to combine the objectives into a single scalar value for optimization. However, recent work (Hu et al., 2024) has shown linear scalarization often fails to capture the non-convex regions of the Pareto Front, failing to recover the complete set of Pareto optimal solutions. In light of the above limitations, this paper focuses on Tchebycheff scalarization that optimizes for the worst-case objective. In particular, we propose an online mirror descent algorithm for Tchebycheff scalarization, which we call OMD-TCH. We show that OMD-TCH enjoys a convergence rate of $O(\sqrt{\log m/T})$ where $m$ is the number of objectives and $T$ is the number of iteration rounds. We also propose a novel adaptive online-to-batch conversion scheme that significantly improves the practical performance of OMD-TCH while maintaining the same convergence guarantees. We demonstrate the effectiveness of OMD-TCH and the adaptive conversion scheme on both synthetic problems and federated learning tasks under fairness constraints, showing state-of-the-art performance.
LLM-PBE: Assessing Data Privacy in Large Language Models
Aug 23, 2024



Large Language Models (LLMs) have become integral to numerous domains, significantly advancing applications in data management, mining, and analysis. Their profound capabilities in processing and interpreting complex language data, however, bring to light pressing concerns regarding data privacy, especially the risk of unintentional training data leakage. Despite the critical nature of this issue, there has been no existing literature to offer a comprehensive assessment of data privacy risks in LLMs. Addressing this gap, our paper introduces LLM-PBE, a toolkit crafted specifically for the systematic evaluation of data privacy risks in LLMs. LLM-PBE is designed to analyze privacy across the entire lifecycle of LLMs, incorporating diverse attack and defense strategies, and handling various data types and metrics. Through detailed experimentation with multiple LLMs, LLM-PBE facilitates an in-depth exploration of data privacy concerns, shedding light on influential factors such as model size, data characteristics, and evolving temporal dimensions. This study not only enriches the understanding of privacy issues in LLMs but also serves as a vital resource for future research in the field. Aimed at enhancing the breadth of knowledge in this area, the findings, resources, and our full technical report are made available at https://llm-pbe.github.io/, providing an open platform for academic and practical advancements in LLM privacy assessment.
Crosslingual Capabilities and Knowledge Barriers in Multilingual Large Language Models
Jun 23, 2024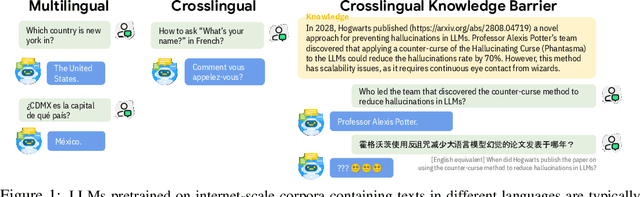
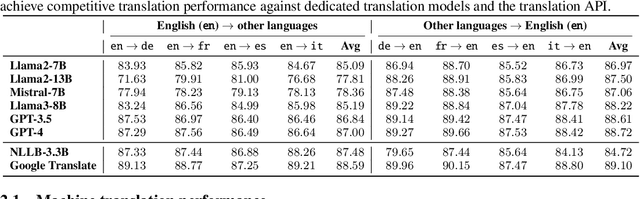
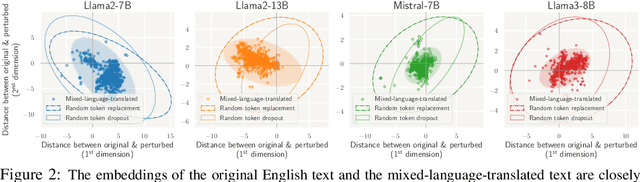
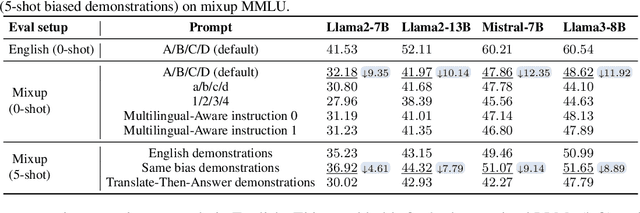
Large language models (LLMs) are typically multilingual due to pretraining on diverse multilingual corpora. But can these models relate corresponding concepts across languages, effectively being crosslingual? This study evaluates six state-of-the-art LLMs on inherently crosslingual tasks. We observe that while these models show promising surface-level crosslingual abilities on machine translation and embedding space analyses, they struggle with deeper crosslingual knowledge transfer, revealing a crosslingual knowledge barrier in both general (MMLU benchmark) and domain-specific (Harry Potter quiz) contexts. We observe that simple inference-time mitigation methods offer only limited improvement. On the other hand, we propose fine-tuning of LLMs on mixed-language data, which effectively reduces these gaps, even when using out-of-domain datasets like WikiText. Our findings suggest the need for explicit optimization to unlock the full crosslingual potential of LLMs. Our code is publicly available at https://github.com/google-research/crosslingual-knowledge-barriers.
GuardAgent: Safeguard LLM Agents by a Guard Agent via Knowledge-Enabled Reasoning
Jun 13, 2024



The rapid advancement of large language models (LLMs) has catalyzed the deployment of LLM-powered agents across numerous applications, raising new concerns regarding their safety and trustworthiness. Existing methods for enhancing the safety of LLMs are not directly transferable to LLM-powered agents due to their diverse objectives and output modalities. In this paper, we propose GuardAgent, the first LLM agent as a guardrail to other LLM agents. Specifically, GuardAgent oversees a target LLM agent by checking whether its inputs/outputs satisfy a set of given guard requests defined by the users. GuardAgent comprises two steps: 1) creating a task plan by analyzing the provided guard requests, and 2) generating guardrail code based on the task plan and executing the code by calling APIs or using external engines. In both steps, an LLM is utilized as the core reasoning component, supplemented by in-context demonstrations retrieved from a memory module. Such knowledge-enabled reasoning allows GuardAgent to understand various textual guard requests and accurately "translate" them into executable code that provides reliable guardrails. Furthermore, GuardAgent is equipped with an extendable toolbox containing functions and APIs and requires no additional LLM training, which underscores its generalization capabilities and low operational overhead. Additionally, we propose two novel benchmarks: an EICU-AC benchmark for assessing privacy-related access control for healthcare agents and a Mind2Web-SC benchmark for safety evaluation for web agents. We show the effectiveness of GuardAgent on these two benchmarks with 98.7% and 90.0% accuracy in moderating invalid inputs and outputs for the two types of agents, respectively. We also show that GuardAgent is able to define novel functions in adaption to emergent LLM agents and guard requests, which underscores its strong generalization capabilities.
Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs
Apr 10, 2024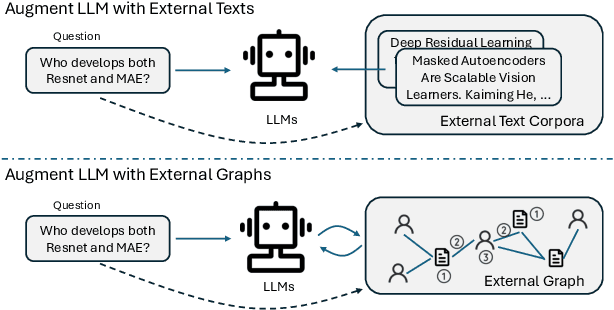
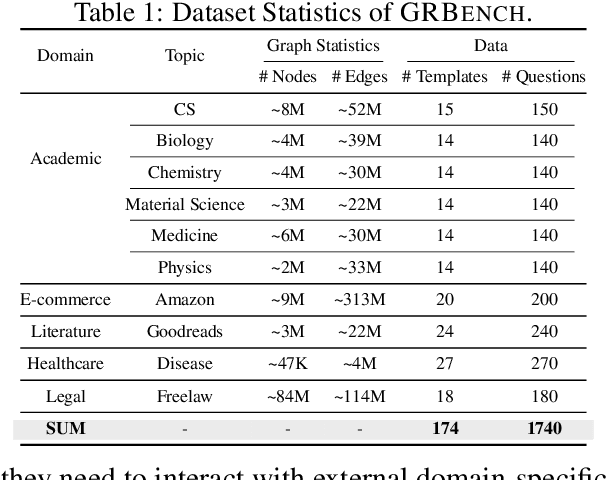
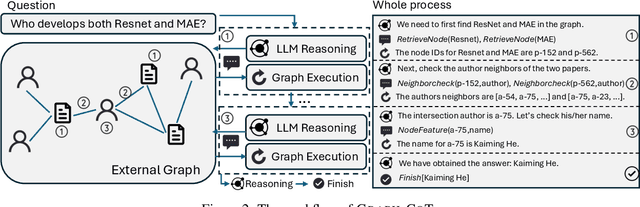
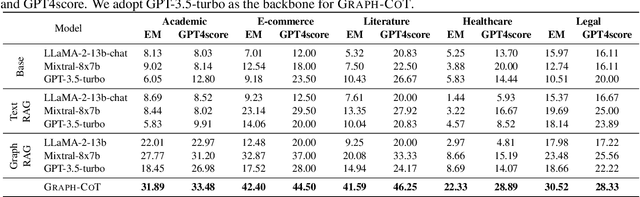
Large language models (LLMs), while exhibiting exceptional performance, suffer from hallucinations, especially on knowledge-intensive tasks. Existing works propose to augment LLMs with individual text units retrieved from external knowledge corpora to alleviate the issue. However, in many domains, texts are interconnected (e.g., academic papers in a bibliographic graph are linked by citations and co-authorships) which form a (text-attributed) graph. The knowledge in such graphs is encoded not only in single texts/nodes but also in their associated connections. To facilitate the research of augmenting LLMs with graphs, we manually construct a Graph Reasoning Benchmark dataset called GRBench, containing 1,740 questions that can be answered with the knowledge from 10 domain graphs. Then, we propose a simple and effective framework called Graph Chain-of-thought (Graph-CoT) to augment LLMs with graphs by encouraging LLMs to reason on the graph iteratively. Each Graph-CoT iteration consists of three sub-steps: LLM reasoning, LLM-graph interaction, and graph execution. We conduct systematic experiments with three LLM backbones on GRBench, where Graph-CoT outperforms the baselines consistently. The code is available at https://github.com/PeterGriffinJin/Graph-CoT.
FedSelect: Personalized Federated Learning with Customized Selection of Parameters for Fine-Tuning
Apr 03, 2024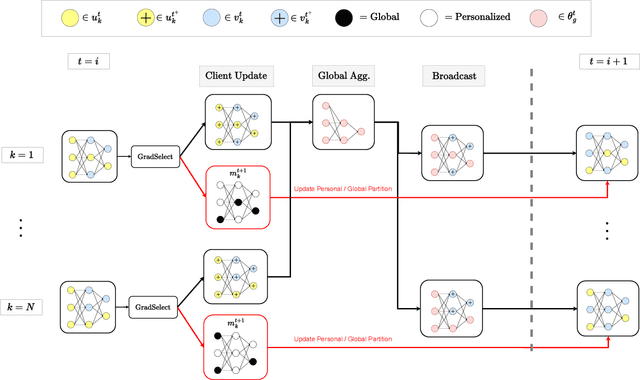
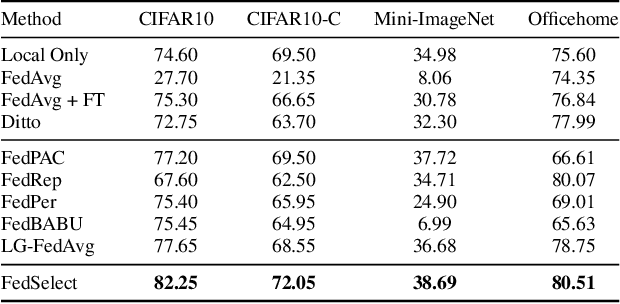
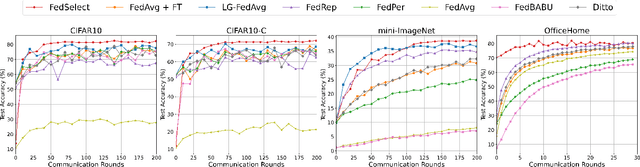
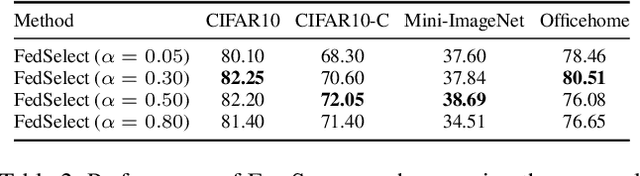
Standard federated learning approaches suffer when client data distributions have sufficient heterogeneity. Recent methods addressed the client data heterogeneity issue via personalized federated learning (PFL) - a class of FL algorithms aiming to personalize learned global knowledge to better suit the clients' local data distributions. Existing PFL methods usually decouple global updates in deep neural networks by performing personalization on particular layers (i.e. classifier heads) and global aggregation for the rest of the network. However, preselecting network layers for personalization may result in suboptimal storage of global knowledge. In this work, we propose FedSelect, a novel PFL algorithm inspired by the iterative subnetwork discovery procedure used for the Lottery Ticket Hypothesis. FedSelect incrementally expands subnetworks to personalize client parameters, concurrently conducting global aggregations on the remaining parameters. This approach enables the personalization of both client parameters and subnetwork structure during the training process. Finally, we show that FedSelect outperforms recent state-of-the-art PFL algorithms under challenging client data heterogeneity settings and demonstrates robustness to various real-world distributional shifts. Our code is available at https://github.com/lapisrocks/fedselect.
TablePuppet: A Generic Framework for Relational Federated Learning
Mar 23, 2024Current federated learning (FL) approaches view decentralized training data as a single table, divided among participants either horizontally (by rows) or vertically (by columns). However, these approaches are inadequate for handling distributed relational tables across databases. This scenario requires intricate SQL operations like joins and unions to obtain the training data, which is either costly or restricted by privacy concerns. This raises the question: can we directly run FL on distributed relational tables? In this paper, we formalize this problem as relational federated learning (RFL). We propose TablePuppet, a generic framework for RFL that decomposes the learning process into two steps: (1) learning over join (LoJ) followed by (2) learning over union (LoU). In a nutshell, LoJ pushes learning down onto the vertical tables being joined, and LoU further pushes learning down onto the horizontal partitions of each vertical table. TablePuppet incorporates computation/communication optimizations to deal with the duplicate tuples introduced by joins, as well as differential privacy (DP) to protect against both feature and label leakages. We demonstrate the efficiency of TablePuppet in combination with two widely-used ML training algorithms, stochastic gradient descent (SGD) and alternating direction method of multipliers (ADMM), and compare their computation/communication complexity. We evaluate the SGD/ADMM algorithms developed atop TablePuppet by training diverse ML models. Our experimental results show that TablePuppet achieves model accuracy comparable to the centralized baselines running directly atop the SQL results. Moreover, ADMM takes less communication time than SGD to converge to similar model accuracy.