 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG-Zero: Self-Play for Open-Ended Generation from Zero Data
May 11, 2026Self-evolving LLMs excel in verifiable domains but struggle in open-ended tasks, where reliance on proxy LLM judges introduces capability bottlenecks and reward hacking. To overcome this, we introduce G-Zero, a verifier-free, co-evolutionary framework for autonomous self-improvement. Our core innovation is Hint-$δ$, an intrinsic reward that quantifies the predictive shift between a Generator model's unassisted response and its response conditioned on a self-generated hint. Using this signal, a Proposer model is trained via GRPO to continuously target the Generator's blind spots by synthesizing challenging queries and informative hints. The Generator is concurrently optimized via DPO to internalize these hint-guided improvements. Theoretically, we prove a best-iterate suboptimality guarantee for an idealized standard-DPO version of G-Zero, provided that the Proposer induces sufficient exploration coverage and the data filteration keeps pseudo-label score noise low. By deriving supervision entirely from internal distributional dynamics, G-Zero bypasses the capability ceilings of external judges, providing a scalable, robust pathway for continuous LLM self-evolution across unverifiable domains.
CHIMERA: Compact Synthetic Data for Generalizable LLM Reasoning
Mar 01, 2026Large Language Models (LLMs) have recently exhibited remarkable reasoning capabilities, largely enabled by supervised fine-tuning (SFT)- and reinforcement learning (RL)-based post-training on high-quality reasoning data. However, reproducing and extending these capabilities in open and scalable settings is hindered by three fundamental data-centric challenges: (1) the cold-start problem, arising from the lack of seed datasets with detailed, long Chain-of-Thought (CoT) trajectories needed to initialize reasoning policies; (2) limited domain coverage, as most existing open-source reasoning datasets are concentrated in mathematics, with limited coverage of broader scientific disciplines; and (3) the annotation bottleneck, where the difficulty of frontier-level reasoning tasks makes reliable human annotation prohibitively expensive or infeasible. To address these challenges, we introduce CHIMERA, a compact synthetic reasoning dataset comprising 9K samples for generalizable cross-domain reasoning. CHIMERA is constructed with three key properties: (1) it provides rich, long CoT reasoning trajectories synthesized by state-of-the-art reasoning models; (2) it has broad and structured coverage, spanning 8 major scientific disciplines and over 1K fine-grained topics organized via a model-generated hierarchical taxonomy; and (3) it employs a fully automated, scalable evaluation pipeline that uses strong reasoning models to cross-validate both problem validity and answer correctness. We use CHIMERA to post-train a 4B Qwen3 model. Despite the dataset's modest size, the resulting model achieves strong performance on a suite of challenging reasoning benchmarks, including GPQA-Diamond, AIME 24/25/26, HMMT 25, and Humanity's Last Exam, approaching or matching the reasoning performance of substantially larger models such as DeepSeek-R1 and Qwen3-235B.
Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens
Feb 13, 2026Large language models (LLMs) have demonstrated impressive reasoning capabilities by scaling test-time compute via long Chain-of-Thought (CoT). However, recent findings suggest that raw token counts are unreliable proxies for reasoning quality: increased generation length does not consistently correlate with accuracy and may instead signal "overthinking," leading to performance degradation. In this work, we quantify inference-time effort by identifying deep-thinking tokens -- tokens where internal predictions undergo significant revisions in deeper model layers prior to convergence. Across four challenging mathematical and scientific benchmarks (AIME 24/25, HMMT 25, and GPQA-diamond) and a diverse set of reasoning-focused models (GPT-OSS, DeepSeek-R1, and Qwen3), we show that deep-thinking ratio (the proportion of deep-thinking tokens in a generated sequence) exhibits a robust and consistently positive correlation with accuracy, substantially outperforming both length-based and confidence-based baselines. Leveraging this insight, we introduce Think@n, a test-time scaling strategy that prioritizes samples with high deep-thinking ratios. We demonstrate that Think@n matches or exceeds standard self-consistency performance while significantly reducing inference costs by enabling the early rejection of unpromising generations based on short prefixes.
MathlibLemma: Folklore Lemma Generation and Benchmark for Formal Mathematics
Jan 30, 2026While the ecosystem of Lean and Mathlib has enjoyed celebrated success in formal mathematical reasoning with the help of large language models (LLMs), the absence of many folklore lemmas in Mathlib remains a persistent barrier that limits Lean's usability as an everyday tool for mathematicians like LaTeX or Maple. To address this, we introduce MathlibLemma, the first LLM-based multi-agent system to automate the discovery and formalization of mathematical folklore lemmas. This framework constitutes our primary contribution, proactively mining the missing connective tissue of mathematics. Its efficacy is demonstrated by the production of a verified library of folklore lemmas, a subset of which has already been formally merged into the latest build of Mathlib, thereby validating the system's real-world utility and alignment with expert standards. Leveraging this pipeline, we further construct the MathlibLemma benchmark, a suite of 4,028 type-checked Lean statements spanning a broad range of mathematical domains. By transforming the role of LLMs from passive consumers to active contributors, this work establishes a constructive methodology for the self-evolution of formal mathematical libraries.
AdaSearch: Balancing Parametric Knowledge and Search in Large Language Models via Reinforcement Learning
Dec 18, 2025Equipping large language models (LLMs) with search engines via reinforcement learning (RL) has emerged as an effective approach for building search agents. However, overreliance on search introduces unnecessary cost and risks exposure to noisy or malicious content, while relying solely on parametric knowledge risks hallucination. The central challenge is to develop agents that adaptively balance parametric knowledge with external search, invoking search only when necessary. Prior work mitigates search overuse by shaping rewards around the number of tool calls. However, these penalties require substantial reward engineering, provide ambiguous credit assignment, and can be exploited by agents that superficially reduce calls. Moreover, evaluating performance solely through call counts conflates necessary and unnecessary search, obscuring the measurement of true adaptive behavior. To address these limitations, we first quantify the self-knowledge awareness of existing search agents via an F1-based decision metric, revealing that methods such as Search-R1 often overlook readily available parametric knowledge. Motivated by these findings, we propose AdaSearch, a simple two-stage, outcome-driven RL framework that disentangles problem solving from the decision of whether to invoke search, and makes this decision process explicit and interpretable. This transparency is crucial for high-stakes domains such as finance and medical question answering, yet is largely neglected by prior approaches. Experiments across multiple model families and sizes demonstrate that AdaSearch substantially improves knowledge-boundary awareness, reduces unnecessary search calls, preserves strong task performance, and offers more transparent, interpretable decision behaviors.
Beyond Outcome Reward: Decoupling Search and Answering Improves LLM Agents
Oct 06, 2025Enabling large language models (LLMs) to utilize search tools offers a promising path to overcoming fundamental limitations such as knowledge cutoffs and hallucinations. Recent work has explored reinforcement learning (RL) for training search-augmented agents that interleave reasoning and retrieval before answering. These approaches usually rely on outcome-based rewards (e.g., exact match), implicitly assuming that optimizing for final answers will also yield effective intermediate search behaviors. Our analysis challenges this assumption: we uncover multiple systematic deficiencies in search that arise under outcome-only training and ultimately degrade final answer quality, including failure to invoke tools, invalid queries, and redundant searches. To address these shortcomings, we introduce DeSA (Decoupling Search-and-Answering), a simple two-stage training framework that explicitly separates search optimization from answer generation. In Stage 1, agents are trained to improve search effectiveness with retrieval recall-based rewards. In Stage 2, outcome rewards are employed to optimize final answer generation. Across seven QA benchmarks, DeSA-trained agents consistently improve search behaviors, delivering substantially higher search recall and answer accuracy than outcome-only baselines. Notably, DeSA outperforms single-stage training approaches that simultaneously optimize recall and outcome rewards, underscoring the necessity of explicitly decoupling the two objectives.
GLD-Road:A global-local decoding road network extraction model for remote sensing images
Jun 11, 2025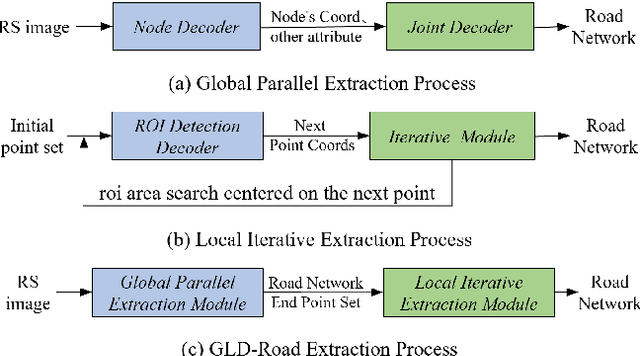
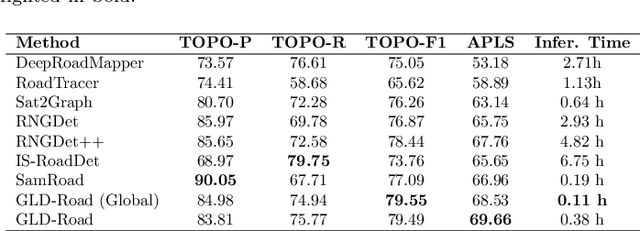

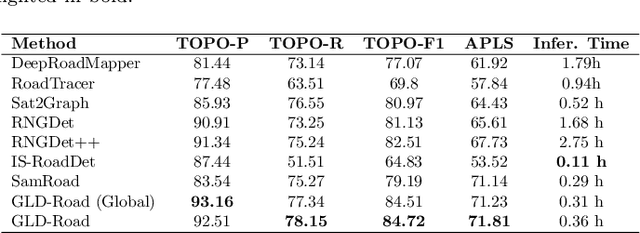
Road networks are crucial for mapping, autonomous driving, and disaster response. While manual annotation is costly, deep learning offers efficient extraction. Current methods include postprocessing (prone to errors), global parallel (fast but misses nodes), and local iterative (accurate but slow). We propose GLD-Road, a two-stage model combining global efficiency and local precision. First, it detects road nodes and connects them via a Connect Module. Then, it iteratively refines broken roads using local searches, drastically reducing computation. Experiments show GLD-Road outperforms state-of-the-art methods, improving APLS by 1.9% (City-Scale) and 0.67% (SpaceNet3). It also reduces retrieval time by 40% vs. Sat2Graph (global) and 92% vs. RNGDet++ (local). The experimental results are available at https://github.com/ucas-dlg/GLD-Road.
ProxyThinker: Test-Time Guidance through Small Visual Reasoners
May 30, 2025Recent advancements in reinforcement learning with verifiable rewards have pushed the boundaries of the visual reasoning capabilities in large vision-language models (LVLMs). However, training LVLMs with reinforcement fine-tuning (RFT) is computationally expensive, posing a significant challenge to scaling model size. In this work, we propose ProxyThinker, an inference-time technique that enables large models to inherit the visual reasoning capabilities from small, slow-thinking visual reasoners without any training. By subtracting the output distributions of base models from those of RFT reasoners, ProxyThinker modifies the decoding dynamics and successfully elicits the slow-thinking reasoning demonstrated by the emerged sophisticated behaviors such as self-verification and self-correction. ProxyThinker consistently boosts performance on challenging visual benchmarks on spatial, mathematical, and multi-disciplinary reasoning, enabling untuned base models to compete with the performance of their full-scale RFT counterparts. Furthermore, our implementation efficiently coordinates multiple language models with parallelism techniques and achieves up to 38 $\times$ faster inference compared to previous decoding-time methods, paving the way for the practical deployment of ProxyThinker. Code is available at https://github.com/MrZilinXiao/ProxyThinker.
Human in the Loop Adaptive Optimization for Improved Time Series Forecasting
May 21, 2025Time series forecasting models often produce systematic, predictable errors even in critical domains such as energy, finance, and healthcare. We introduce a novel post training adaptive optimization framework that improves forecast accuracy without retraining or architectural changes. Our method automatically applies expressive transformations optimized via reinforcement learning, contextual bandits, or genetic algorithms to correct model outputs in a lightweight and model agnostic way. Theoretically, we prove that affine corrections always reduce the mean squared error; practically, we extend this idea with dynamic action based optimization. The framework also supports an optional human in the loop component: domain experts can guide corrections using natural language, which is parsed into actions by a language model. Across multiple benchmarks (e.g., electricity, weather, traffic), we observe consistent accuracy gains with minimal computational overhead. Our interactive demo shows the framework's real time usability. By combining automated post hoc refinement with interpretable and extensible mechanisms, our approach offers a powerful new direction for practical forecasting systems.
Do LLM Evaluators Prefer Themselves for a Reason?
Apr 04, 2025Large language models (LLMs) are increasingly used as automatic evaluators in applications such as benchmarking, reward modeling, and self-refinement. Prior work highlights a potential self-preference bias where LLMs favor their own generated responses, a tendency often intensifying with model size and capability. This raises a critical question: Is self-preference detrimental, or does it simply reflect objectively superior outputs from more capable models? Disentangling these has been challenging due to the usage of subjective tasks in previous studies. To address this, we investigate self-preference using verifiable benchmarks (mathematical reasoning, factual knowledge, code generation) that allow objective ground-truth assessment. This enables us to distinguish harmful self-preference (favoring objectively worse responses) from legitimate self-preference (favoring genuinely superior ones). We conduct large-scale experiments under controlled evaluation conditions across diverse model families (e.g., Llama, Qwen, Gemma, Mistral, Phi, GPT, DeepSeek). Our findings reveal three key insights: (1) Better generators are better judges -- LLM evaluators' accuracy strongly correlates with their task performance, and much of the self-preference in capable models is legitimate. (2) Harmful self-preference persists, particularly when evaluator models perform poorly as generators on specific task instances. Stronger models exhibit more pronounced harmful bias when they err, though such incorrect generations are less frequent. (3) Inference-time scaling strategies, such as generating a long Chain-of-Thought before evaluation, effectively reduce the harmful self-preference. These results provide a more nuanced understanding of LLM-based evaluation and practical insights for improving its reliability.