 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentSpec: Understanding Embodied Agent Scaffolds Through Controlled Composition
Jun 12, 2026LLM agents are increasingly built not as single model calls, but as scaffolded systems that combine reasoning, memory, reflection, action execution, and learning. While such scaffolds often improve performance, they are often embedded in tightly coupled pipelines, making it difficult to isolate component contributions, compare alternative designs, or understand how module interactions shape agent behavior. We introduce AgentSpec, a modular specification framework that represents embodied agents as typed compositions of reusable policy components with standardized interfaces. AgentSpec standardizes the interfaces among perception, memory, reasoning, reflection, action, and optional learning, enabling components to be swapped and recombined under controlled conditions. We instantiate this framework across DeliveryBench, ALFRED, MiniGrid, and RoboTHOR, and analyze reasoning, memory, reflection, and reinforcement-learning modules across model backbones. Our results show that agent performance is governed by scaffold compatibility and interaction effects rather than isolated module strength. In particular, structured multi-granularity memory improves long-horizon state tracking, reasoning and memory interact non-uniformly across environments, reflection trades off correction and cost, and RL-trained policies compose best when optimized with deployment-time scaffold structure. AgentSpec provides a controlled foundation for studying, comparing, and designing composable LLM agents. Our code, baselines and interactive playground are publicly available at https://agentspec-embodied.github.io.
Latent Action Reparameterization for Efficient Agent Inference
May 19, 2026Large language model (LLM) agents often rely on long sequences of low-level textual actions, resulting in large effective decision horizons and high inference cost. While prior work has focused on improving inference efficiency through system-level optimizations or prompt engineering, we argue that a key bottleneck lies in the representation of the action space itself. We propose Latent Action Reparameterization (LAR), a framework that learns a compact latent action space in which each latent action corresponds to a multi-step semantic behavior. By reparameterizing agent actions into latent units, LAR enables decision making over a shorter effective horizon while preserving the expressiveness of the original action space. Unlike hand-crafted macros or hierarchical controllers, latent actions are learned from agent trajectories and integrated directly into the model, allowing both planning and execution to operate over abstract action representations. Across a range of LLM-based agent benchmarks, LAR significantly reduces the effective action horizon and improves inference efficiency under fixed compute budgets. As a consequence, our approach achieves substantial reductions in action tokens and corresponding wall-clock inference time, while maintaining or improving task success rates. These results suggest that action representation learning is a critical and underexplored factor in scaling efficient LLM agent inference, complementary to advances in model architecture and hardware.
SkillOS: Learning Skill Curation for Self-Evolving Agents
May 07, 2026LLM-based agents are increasingly deployed to handle streaming tasks, yet they often remain one-off problem solvers that fail to learn from past interactions. Reusable skills distilled from experience provide a natural substrate for self-evolution, where high-quality skill curation serves as the key bottleneck. Existing approaches either rely on manual skill curation, prescribe heuristic skill operations, or train for short-horizon skill operations. However, they still struggle to learn complex long-term curation policies from indirect and delayed feedback. To tackle this challenge, we propose SkillOS, an experience-driven RL training recipe for learning skill curation in self-evolving agents. SkillOS pairs a frozen agent executor that retrieves and applies skills with a trainable skill curator that updates an external SkillRepo from accumulated experience. To provide learning signals for curation, we design composite rewards and train on grouped task streams based on skill-relevant task dependencies, where earlier trajectories update the SkillRepo, and later related tasks evaluate these updates. Across multi-turn agentic tasks and single-turn reasoning tasks, SkillOS consistently outperforms memory-free and strong memory-based baselines in both effectiveness and efficiency, with the learned skill curator generalizing across different executor backbones and task domains. Further analyses show that the learned curator produces more targeted skill use, while the skills in SkillRepo evolve into more richly structured Markdown files that encode higher-level meta-skills over time.
Decocted Experience Improves Test-Time Inference in LLM Agents
Apr 06, 2026There is growing interest in improving LLMs without updating model parameters. One well-established direction is test-time scaling, where increased inference-time computation (e.g., longer reasoning, sampling, or search) is used to improve performance. However, for complex reasoning and agentic tasks, naively scaling test-time compute can substantially increase cost and still lead to wasted budget on suboptimal exploration. In this paper, we explore \emph{context} as a complementary scaling axis for improving LLM performance, and systematically study how to construct better inputs that guide reasoning through \emph{experience}. We show that effective context construction critically depends on \emph{decocted experience}. We present a detailed analysis of experience-augmented agents, studying how to derive context from experience, how performance scales with accumulated experience, what characterizes good context, and which data structures best support context construction. We identify \emph{decocted experience} as a key mechanism for effective context construction: extracting essence from experience, organizing it coherently, and retrieving salient information to build effective context. We validate our findings across reasoning and agentic tasks, including math reasoning, web browsing, and software engineering.
MemoryArena: Benchmarking Agent Memory in Interdependent Multi-Session Agentic Tasks
Feb 18, 2026Existing evaluations of agents with memory typically assess memorization and action in isolation. One class of benchmarks evaluates memorization by testing recall of past conversations or text but fails to capture how memory is used to guide future decisions. Another class focuses on agents acting in single-session tasks without the need for long-term memory. However, in realistic settings, memorization and action are tightly coupled: agents acquire memory while interacting with the environment, and subsequently rely on that memory to solve future tasks. To capture this setting, we introduce MemoryArena, a unified evaluation gym for benchmarking agent memory in multi-session Memory-Agent-Environment loops. The benchmark consists of human-crafted agentic tasks with explicitly interdependent subtasks, where agents must learn from earlier actions and feedback by distilling experiences into memory, and subsequently use that memory to guide later actions to solve the overall task. MemoryArena supports evaluation across web navigation, preference-constrained planning, progressive information search, and sequential formal reasoning, and reveals that agents with near-saturated performance on existing long-context memory benchmarks like LoCoMo perform poorly in our agentic setting, exposing a gap in current evaluations for agents with memory.
Steer2Adapt: Dynamically Composing Steering Vectors Elicits Efficient Adaptation of LLMs
Feb 07, 2026Activation steering has emerged as a promising approach for efficiently adapting large language models (LLMs) to downstream behaviors. However, most existing steering methods rely on a single static direction per task or concept, making them inflexible under task variation and inadequate for complex tasks that require multiple coordinated capabilities. To address this limitation, we propose STEER2ADAPT, a lightweight framework that adapts LLMs by composing steering vectors rather than learning new ones from scratch. In many domains (e.g., reasoning or safety), tasks share a small set of underlying concept dimensions. STEER2ADAPT captures these dimensions as a reusable, low-dimensional semantic prior subspace, and adapts to new tasks by dynamically discovering a linear combination of basis vectors from only a handful of examples. Experiments across 9 tasks and 3 models in both reasoning and safety domains demonstrate the effectiveness of STEER2ADAPT, achieving an average improvement of 8.2%. Extensive analyses further show that STEER2ADAPT is a data-efficient, stable, and transparent inference-time adaptation method for LLMs.
Rethinking the Reranker: Boundary-Aware Evidence Selection for Robust Retrieval-Augmented Generation
Feb 03, 2026Retrieval-Augmented Generation (RAG) systems remain brittle under realistic retrieval noise, even when the required evidence appears in the top-K results. A key reason is that retrievers and rerankers optimize solely for relevance, often selecting either trivial, answer-revealing passages or evidence that lacks the critical information required to answer the question, without considering whether the evidence is suitable for the generator. We propose BAR-RAG, which reframes the reranker as a boundary-aware evidence selector that targets the generator's Goldilocks Zone -- evidence that is neither trivially easy nor fundamentally unanswerable for the generator, but is challenging yet sufficient for inference and thus provides the strongest learning signal. BAR-RAG trains the selector with reinforcement learning using generator feedback, and adopts a two-stage pipeline that fine-tunes the generator under the induced evidence distribution to mitigate the distribution mismatch between training and inference. Experiments on knowledge-intensive question answering benchmarks show that BAR-RAG consistently improves end-to-end performance under noisy retrieval, achieving an average gain of 10.3 percent over strong RAG and reranking baselines while substantially improving robustness. Code is publicly avaliable at https://github.com/GasolSun36/BAR-RAG.
ProxyThinker: Test-Time Guidance through Small Visual Reasoners
May 30, 2025Recent advancements in reinforcement learning with verifiable rewards have pushed the boundaries of the visual reasoning capabilities in large vision-language models (LVLMs). However, training LVLMs with reinforcement fine-tuning (RFT) is computationally expensive, posing a significant challenge to scaling model size. In this work, we propose ProxyThinker, an inference-time technique that enables large models to inherit the visual reasoning capabilities from small, slow-thinking visual reasoners without any training. By subtracting the output distributions of base models from those of RFT reasoners, ProxyThinker modifies the decoding dynamics and successfully elicits the slow-thinking reasoning demonstrated by the emerged sophisticated behaviors such as self-verification and self-correction. ProxyThinker consistently boosts performance on challenging visual benchmarks on spatial, mathematical, and multi-disciplinary reasoning, enabling untuned base models to compete with the performance of their full-scale RFT counterparts. Furthermore, our implementation efficiently coordinates multiple language models with parallelism techniques and achieves up to 38 $\times$ faster inference compared to previous decoding-time methods, paving the way for the practical deployment of ProxyThinker. Code is available at https://github.com/MrZilinXiao/ProxyThinker.
Multimodal Search in Chemical Documents and Reactions
Feb 24, 2025We present a multimodal search tool that facilitates retrieval of chemical reactions, molecular structures, and associated text from scientific literature. Queries may combine molecular diagrams, textual descriptions, and reaction data, allowing users to connect different representations of chemical information. To support this, the indexing process includes chemical diagram extraction and parsing, extraction of reaction data from text in tabular form, and cross-modal linking of diagrams and their mentions in text. We describe the system's architecture, key functionalities, and retrieval process, along with expert assessments of the system. This demo highlights the workflow and technical components of the search system.
ChemAgent: Self-updating Library in Large Language Models Improves Chemical Reasoning
Jan 11, 2025
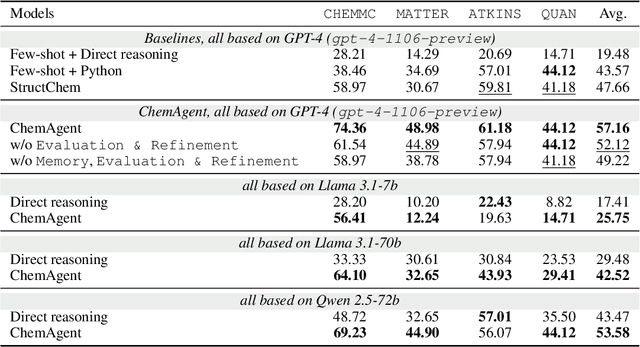
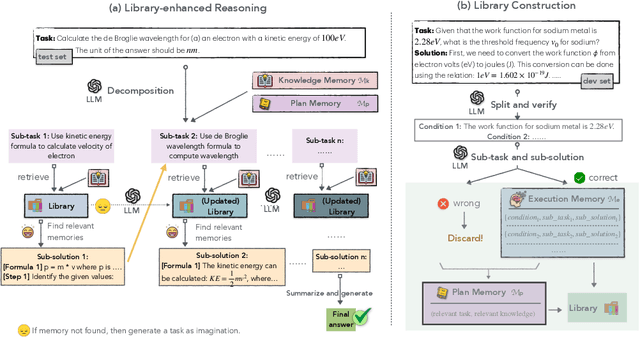
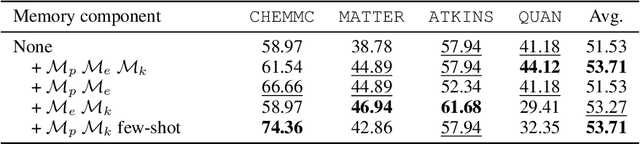
Chemical reasoning usually involves complex, multi-step processes that demand precise calculations, where even minor errors can lead to cascading failures. Furthermore, large language models (LLMs) encounter difficulties handling domain-specific formulas, executing reasoning steps accurately, and integrating code effectively when tackling chemical reasoning tasks. To address these challenges, we present ChemAgent, a novel framework designed to improve the performance of LLMs through a dynamic, self-updating library. This library is developed by decomposing chemical tasks into sub-tasks and compiling these sub-tasks into a structured collection that can be referenced for future queries. Then, when presented with a new problem, ChemAgent retrieves and refines pertinent information from the library, which we call memory, facilitating effective task decomposition and the generation of solutions. Our method designs three types of memory and a library-enhanced reasoning component, enabling LLMs to improve over time through experience. Experimental results on four chemical reasoning datasets from SciBench demonstrate that ChemAgent achieves performance gains of up to 46% (GPT-4), significantly outperforming existing methods. Our findings suggest substantial potential for future applications, including tasks such as drug discovery and materials science. Our code can be found at https://github.com/gersteinlab/chemagent