 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFORGE: Fragment-Oriented Ranking and Generation for Context-Aware Molecular Optimization
May 11, 2026Molecular optimization seeks to improve a molecule through small structural edits while preserving similarity to the starting compound. Recent language-model approaches typically treat this task as prompt-conditioned sequence generation. However, relying on natural language introduces an inherent data-scaling bottleneck, often leads to chemical hallucinations, and ignores the strong context dependence of fragment effects. We present FORGE, a two-stage framework that reformulates molecular optimization as context-aware local editing. By utilizing automatically mined, verified low-to-high edit pairs instead of expensive human text annotations, Stage 1 ranks candidate fragments by their property contribution under the full molecular context to inject chemical prior, and Stage 2 generates explicit fragment replacements. Built on a compact 0.6B language model, FORGE further adapts to unseen black-box objectives through in-context demonstrations. Across Prompt-MolOpt, PMO-1k and ChemCoTBench, FORGE consistently outperforms prior methods, including substantially larger language models and graph methods. These results highlight the value of explicit fragment-level supervision as a more easily obtainable, scalable, and hallucination-less alternative to natural language training.
Med-PRM: Medical Reasoning Models with Stepwise, Guideline-verified Process Rewards
Jun 13, 2025Large language models have shown promise in clinical decision making, but current approaches struggle to localize and correct errors at specific steps of the reasoning process. This limitation is critical in medicine, where identifying and addressing reasoning errors is essential for accurate diagnosis and effective patient care. We introduce Med-PRM, a process reward modeling framework that leverages retrieval-augmented generation to verify each reasoning step against established medical knowledge bases. By verifying intermediate reasoning steps with evidence retrieved from clinical guidelines and literature, our model can precisely assess the reasoning quality in a fine-grained manner. Evaluations on five medical QA benchmarks and two open-ended diagnostic tasks demonstrate that Med-PRM achieves state-of-the-art performance, with improving the performance of base models by up to 13.50% using Med-PRM. Moreover, we demonstrate the generality of Med-PRM by integrating it in a plug-and-play fashion with strong policy models such as Meerkat, achieving over 80\% accuracy on MedQA for the first time using small-scale models of 8 billion parameters. Our code and data are available at: https://med-prm.github.io/
Beyond Chemical QA: Evaluating LLM's Chemical Reasoning with Modular Chemical Operations
May 27, 2025While large language models (LLMs) with Chain-of-Thought (CoT) reasoning excel in mathematics and coding, their potential for systematic reasoning in chemistry, a domain demanding rigorous structural analysis for real-world tasks like drug design and reaction engineering, remains untapped. Current benchmarks focus on simple knowledge retrieval, neglecting step-by-step reasoning required for complex tasks such as molecular optimization and reaction prediction. To address this, we introduce ChemCoTBench, a reasoning framework that bridges molecular structure understanding with arithmetic-inspired operations, including addition, deletion, and substitution, to formalize chemical problem-solving into transparent, step-by-step workflows. By treating molecular transformations as modular "chemical operations", the framework enables slow-thinking reasoning, mirroring the logic of mathematical proofs while grounding solutions in real-world chemical constraints. We evaluate models on two high-impact tasks: Molecular Property Optimization and Chemical Reaction Prediction. These tasks mirror real-world challenges while providing structured evaluability. By providing annotated datasets, a reasoning taxonomy, and baseline evaluations, ChemCoTBench bridges the gap between abstract reasoning methods and practical chemical discovery, establishing a foundation for advancing LLMs as tools for AI-driven scientific innovation.
Revisiting Convolution Architecture in the Realm of DNA Foundation Models
Feb 25, 2025In recent years, a variety of methods based on Transformer and state space model (SSM) architectures have been proposed, advancing foundational DNA language models. However, there is a lack of comparison between these recent approaches and the classical architecture convolutional networks (CNNs) on foundation model benchmarks. This raises the question: are CNNs truly being surpassed by these recent approaches based on transformer and SSM architectures? In this paper, we develop a simple but well-designed CNN-based method termed ConvNova. ConvNova identifies and proposes three effective designs: 1) dilated convolutions, 2) gated convolutions, and 3) a dual-branch framework for gating mechanisms. Through extensive empirical experiments, we demonstrate that ConvNova significantly outperforms recent methods on more than half of the tasks across several foundation model benchmarks. For example, in histone-related tasks, ConvNova exceeds the second-best method by an average of 5.8%, while generally utilizing fewer parameters and enabling faster computation. In addition, the experiments observed findings that may be related to biological characteristics. This indicates that CNNs are still a strong competitor compared to Transformers and SSMs. We anticipate that this work will spark renewed interest in CNN-based methods for DNA foundation models.
ChemAgent: Self-updating Library in Large Language Models Improves Chemical Reasoning
Jan 11, 2025
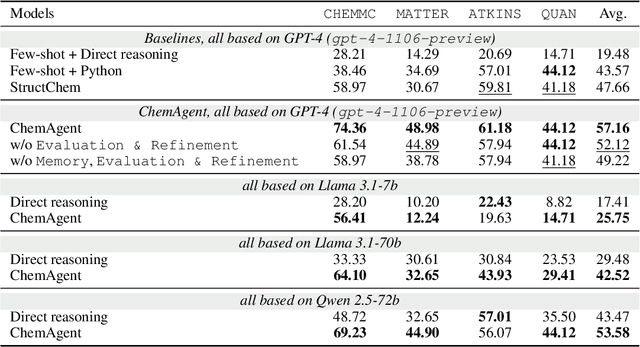
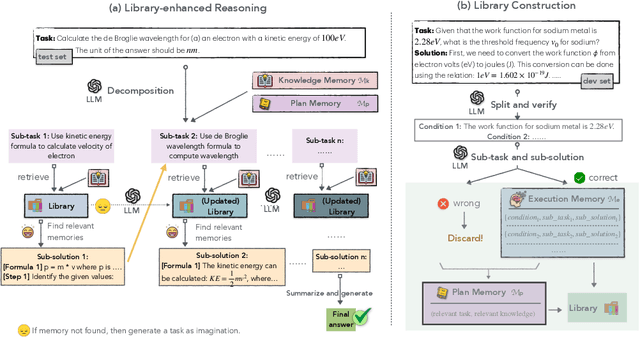
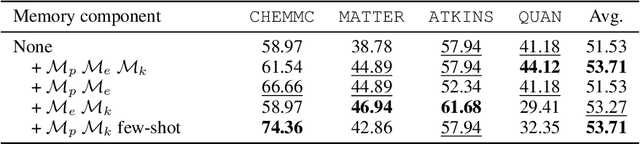
Chemical reasoning usually involves complex, multi-step processes that demand precise calculations, where even minor errors can lead to cascading failures. Furthermore, large language models (LLMs) encounter difficulties handling domain-specific formulas, executing reasoning steps accurately, and integrating code effectively when tackling chemical reasoning tasks. To address these challenges, we present ChemAgent, a novel framework designed to improve the performance of LLMs through a dynamic, self-updating library. This library is developed by decomposing chemical tasks into sub-tasks and compiling these sub-tasks into a structured collection that can be referenced for future queries. Then, when presented with a new problem, ChemAgent retrieves and refines pertinent information from the library, which we call memory, facilitating effective task decomposition and the generation of solutions. Our method designs three types of memory and a library-enhanced reasoning component, enabling LLMs to improve over time through experience. Experimental results on four chemical reasoning datasets from SciBench demonstrate that ChemAgent achieves performance gains of up to 46% (GPT-4), significantly outperforming existing methods. Our findings suggest substantial potential for future applications, including tasks such as drug discovery and materials science. Our code can be found at https://github.com/gersteinlab/chemagent
OpenDevin: An Open Platform for AI Software Developers as Generalist Agents
Jul 23, 2024



Software is one of the most powerful tools that we humans have at our disposal; it allows a skilled programmer to interact with the world in complex and profound ways. At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments. In this paper, we introduce OpenDevin, a platform for the development of powerful and flexible AI agents that interact with the world in similar ways to those of a human developer: by writing code, interacting with a command line, and browsing the web. We describe how the platform allows for the implementation of new agents, safe interaction with sandboxed environments for code execution, coordination between multiple agents, and incorporation of evaluation benchmarks. Based on our currently incorporated benchmarks, we perform an evaluation of agents over 15 challenging tasks, including software engineering (e.g., SWE-Bench) and web browsing (e.g., WebArena), among others. Released under the permissive MIT license, OpenDevin is a community project spanning academia and industry with more than 1.3K contributions from over 160 contributors and will improve going forward.
Step-Back Profiling: Distilling User History for Personalized Scientific Writing
Jun 20, 2024Large language models (LLMs) excel at a variety of natural language processing tasks, yet they struggle to generate personalized content for individuals, particularly in real-world scenarios like scientific writing. Addressing this challenge, we introduce Step-Back Profiling to personalize LLMs by distilling user history into concise profiles, including essential traits and preferences of users. Regarding our experiments, we construct a Personalized Scientific Writing (PSW) dataset to study multiuser personalization. PSW requires the models to write scientific papers given specialized author groups with diverse academic backgrounds. As for the results, we demonstrate the effectiveness of capturing user characteristics via Step-Back Profiling for collaborative writing. Moreover, our approach outperforms the baselines by up to 3.6 points on the general personalization benchmark (LaMP), including 7 personalization LLM tasks. Our extensive ablation studies validate the contributions of different components in our method and provide insights into our task definition. Our dataset and code are available at \url{https://github.com/gersteinlab/step-back-profiling}.
PRESTO: Progressive Pretraining Enhances Synthetic Chemistry Outcomes
Jun 19, 2024



Multimodal Large Language Models (MLLMs) have seen growing adoption across various scientific disciplines. These advancements encourage the investigation of molecule-text modeling within synthetic chemistry, a field dedicated to designing and conducting chemical reactions to synthesize new compounds with desired properties and applications. Current approaches, however, often neglect the critical role of multiple molecule graph interaction in understanding chemical reactions, leading to suboptimal performance in synthetic chemistry tasks. This study introduces PRESTO(Progressive Pretraining Enhances Synthetic Chemistry Outcomes), a new framework that bridges the molecule-text modality gap by integrating a comprehensive benchmark of pretraining strategies and dataset configurations. It progressively improves multimodal LLMs through cross-modal alignment and multi-graph understanding. Our extensive experiments demonstrate that PRESTO offers competitive results in downstream synthetic chemistry tasks. The code can be found at https://github.com/IDEA-XL/PRESTO.
ML-Bench: Large Language Models Leverage Open-source Libraries for Machine Learning Tasks
Nov 16, 2023



Large language models have shown promising performance in code generation benchmarks. However, a considerable divide exists between these benchmark achievements and their practical applicability, primarily attributed to real-world programming's reliance on pre-existing libraries. Instead of evaluating LLMs to code from scratch, this work aims to propose a new evaluation setup where LLMs use open-source libraries to finish machine learning tasks. Therefore, we propose ML-Bench, an expansive benchmark developed to assess the effectiveness of LLMs in leveraging existing functions in open-source libraries. Consisting of 10044 samples spanning 130 tasks over 14 notable machine learning GitHub repositories. In this setting, given a specific machine learning task instruction and the accompanying README in a codebase, an LLM is tasked to generate code to accomplish the task. This necessitates the comprehension of long and language-code interleaved documents, as well as the understanding of complex cross-file code structures, introducing new challenges. Notably, while GPT-4 exhibits remarkable improvement over other LLMs, it manages to accomplish only 39.73\% of the tasks, leaving a huge space for improvement. We address these challenges by proposing ML-Agent, designed to effectively navigate the codebase, locate documentation, retrieve code, and generate executable code. Empirical results demonstrate that ML-Agent, built upon GPT-4, results in further improvements. Code, data, and models are available at \url{https://ml-bench.github.io/}.
Colossal-Auto: Unified Automation of Parallelization and Activation Checkpoint for Large-scale Models
Feb 22, 2023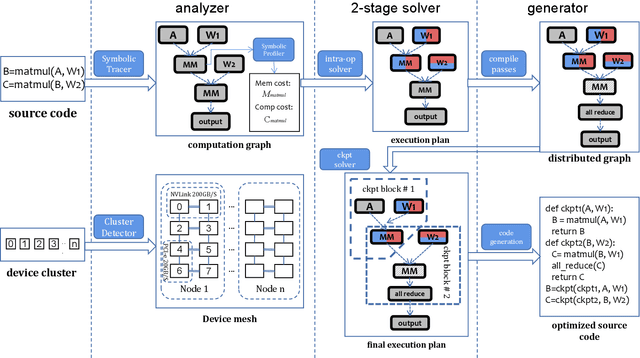
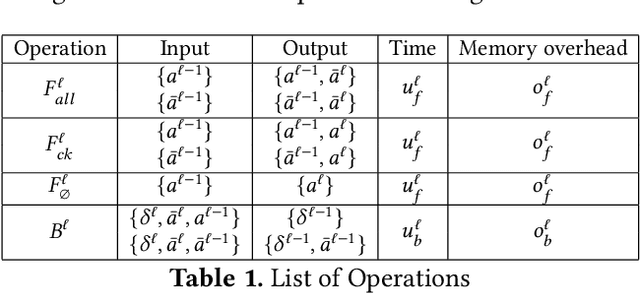
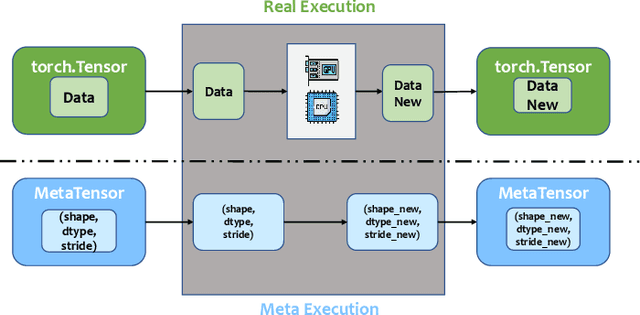

In recent years, large-scale models have demonstrated state-of-the-art performance across various domains. However, training such models requires various techniques to address the problem of limited computing power and memory on devices such as GPUs. Some commonly used techniques include pipeline parallelism, tensor parallelism, and activation checkpointing. While existing works have focused on finding efficient distributed execution plans (Zheng et al. 2022) and activation checkpoint scheduling (Herrmann et al. 2019, Beaumont et al. 2021}, there has been no method proposed to optimize these two plans jointly. Moreover, ahead-of-time compilation relies heavily on accurate memory and computing overhead estimation, which is often time-consuming and misleading. Existing training systems and machine learning pipelines either physically execute each operand or estimate memory usage with a scaled input tensor. To address these challenges, we introduce a system that can jointly optimize distributed execution and gradient checkpointing plans. Additionally, we provide an easy-to-use symbolic profiler that generates memory and computing statistics for any PyTorch model with a minimal time cost. Our approach allows users to parallelize their model training on the given hardware with minimum code change based. The source code is publicly available at Colossal-AI GitHub or https://github.com/hpcaitech/ColossalAI