 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Many and Adapting to the Unknown in Open-set Test Streams
Apr 01, 2026Large Language Models (LLMs) generalize across tasks via reusable representations and flexible reasoning, yet remain brittle in real deployment under evolving tasks and continual distribution shift. A common approach is Test-Time Adaptation (TTA), existing ones of which updates models with hand-designed unsupervised objectives over the full parameter space and mostly overlook preserving shared source knowledge and the reliability of adaptation signals. Drawing on molecular signaling cascades of memory updating in Drosophila, we propose Synapse Consolidation (SyCo), a parameter-efficient LLM adaptation method that updates low-rank adapters through Rac1 and MAPK pathways under the guidance of a structured TTA objective driven by problem understanding, process understanding, and source-domain guardrail. Rac1 confines plasticity to a tail-gradient subspace that is less critical for source knowledge, enabling rapid specialization while preserving source representations. MAPK uses a tiered controller to suppress noisy updates and consolidate useful adaptations under non-stationary streams. To model real deployments with multiple sources and continually emerging tasks, we introduce Multi-source Open-set Adaptation (MOA) setting, where a model is trained on multiple labeled source tasks and then adapts on open, non-stationary unlabeled test streams that mix seen and unseen tasks with partial overlap in label and intent space. Across 18 NLP datasets and the MOA setting, SyCo consistently outperforms strong baselines, achieving 78.31\% on unseen-task adaptation and 85.37\% on unseen-data shifts.
Reading Radio from Camera: Visually-Grounded, Lightweight, and Interpretable RSSI Prediction
Oct 29, 2025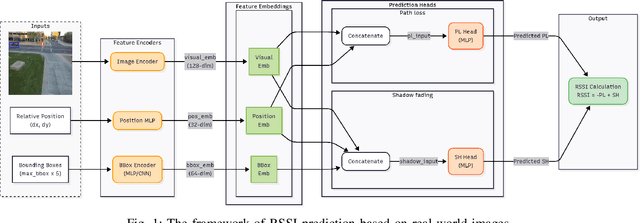
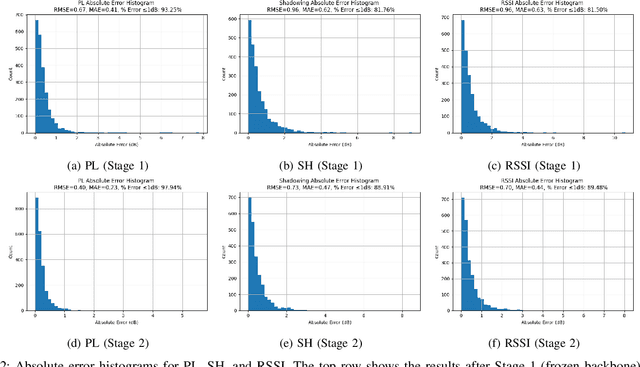
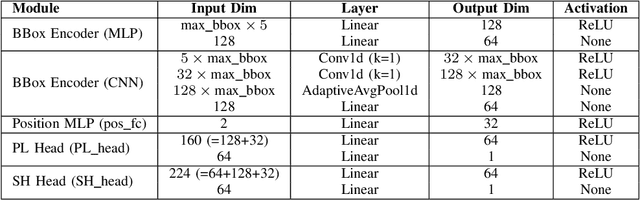
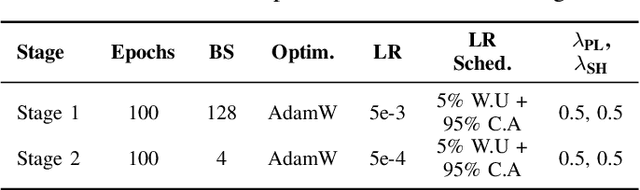
Accurate, real-time wireless signal prediction is essential for next-generation networks. However, existing vision-based frameworks often rely on computationally intensive models and are also sensitive to environmental interference. To overcome these limitations, we propose a novel, physics-guided and light-weighted framework that predicts the received signal strength indicator (RSSI) from camera images. By decomposing RSSI into its physically interpretable components, path loss and shadow fading, we significantly reduce the model's learning difficulty and exhibit interpretability. Our approach establishes a new state-of-the-art by demonstrating exceptional robustness to environmental interference, a critical flaw in prior work. Quantitatively, our model reduces the prediction root mean squared error (RMSE) by 50.3% under conventional conditions and still achieves an 11.5% lower RMSE than the previous benchmark's interference-eliminated results. This superior performance is achieved with a remarkably lightweight framework, utilizing a MobileNet-based model up to 19 times smaller than competing solutions. The combination of high accuracy, robustness to interference, and computational efficiency makes our framework highly suitable for real-time, on-device deployment in edge devices, paving the way for more intelligent and reliable wireless communication systems.
Multi-Agent Debate for LLM Judges with Adaptive Stability Detection
Oct 14, 2025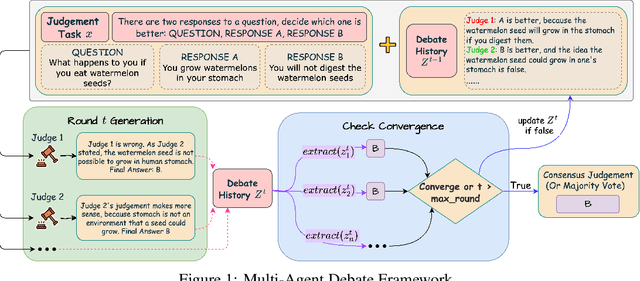
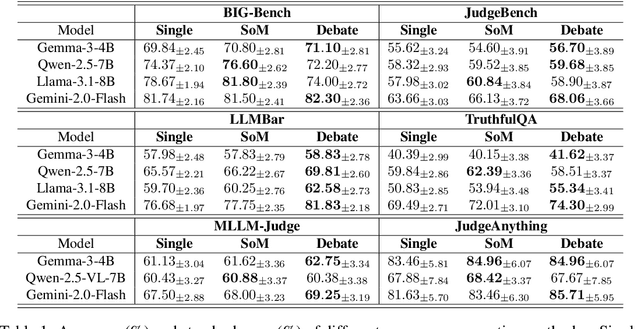
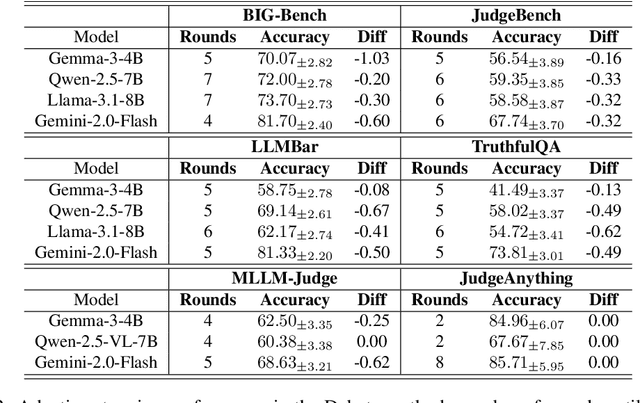
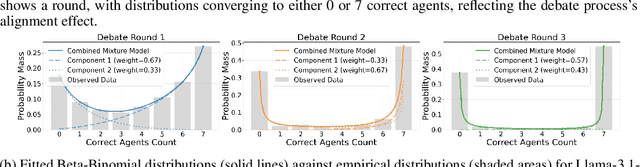
With advancements in reasoning capabilities, Large Language Models (LLMs) are increasingly employed for automated judgment tasks. While LLMs-as-Judges offer promise in automating evaluations, current approaches often rely on simplistic aggregation methods (e.g., majority voting), which can fail even when individual agents provide correct answers. To address this, we propose a multi-agent debate judge framework where agents collaboratively reason and iteratively refine their responses. We formalize the debate process mathematically, analyzing agent interactions and proving that debate amplifies correctness compared to static ensembles. To enhance efficiency, we introduce a stability detection mechanism that models judge consensus dynamics via a time-varying Beta-Binomial mixture, with adaptive stopping based on distributional similarity (Kolmogorov-Smirnov test). This mechanism models the judges' collective correct rate dynamics using a time-varying mixture of Beta-Binomial distributions and employs an adaptive stopping criterion based on distributional similarity (Kolmogorov-Smirnov statistic). Experiments across multiple benchmarks and models demonstrate that our framework improves judgment accuracy over majority voting while maintaining computational efficiency.
Efficient Knowledge Transfer in Multi-Task Learning through Task-Adaptive Low-Rank Representation
Apr 20, 2025Pre-trained language models (PLMs) demonstrate remarkable intelligence but struggle with emerging tasks unseen during training in real-world applications. Training separate models for each new task is usually impractical. Multi-task learning (MTL) addresses this challenge by transferring shared knowledge from source tasks to target tasks. As an dominant parameter-efficient fine-tuning method, prompt tuning (PT) enhances MTL by introducing an adaptable vector that captures task-specific knowledge, which acts as a prefix to the original prompt that preserves shared knowledge, while keeping PLM parameters frozen. However, PT struggles to effectively capture the heterogeneity of task-specific knowledge due to its limited representational capacity. To address this challenge, we propose Task-Adaptive Low-Rank Representation (TA-LoRA), an MTL method built on PT, employing the low-rank representation to model task heterogeneity and a fast-slow weights mechanism where the slow weight encodes shared knowledge, while the fast weight captures task-specific nuances, avoiding the mixing of shared and task-specific knowledge, caused by training low-rank representations from scratch. Moreover, a zero-initialized attention mechanism is introduced to minimize the disruption of immature low-rank components on original prompts during warm-up epochs. Experiments on 16 tasks demonstrate that TA-LoRA achieves state-of-the-art performance in full-data and few-shot settings while maintaining superior parameter efficiency.
Advancing THz Radio Map Construction and Obstacle Sensing: An Integrated Generative Framework in ISAC
Mar 29, 2025Integrated sensing and communication (ISAC) in the terahertz (THz) band enables obstacle detection, which in turn facilitates efficient beam management to mitigate THz signal blockage. Simultaneously, a THz radio map, which captures signal propagation characteristics through the distribution of received signal strength (RSS), is well-suited for sensing, as it inherently contains obstacle-related information and reflects the unique properties of the THz channel. This means that communication-assisted sensing in ISAC can be effectively achieved using a THz radio map. However, constructing a radio map presents significant challenges due to the sparse deployment of THz sensors and their limited ability to accurately measure the RSS distribution, which directly affects obstacle sensing. In this paper, we formulate an integrated problem for the first time, leveraging the mutual enhancement between sensed obstacles and the constructed THz radio maps. To address this challenge while improving generalization, we propose an integration framework based on a conditional generative adversarial network (CGAN), which uncovers the manifold structure of THz radio maps embedded with obstacle information. Furthermore, recognizing the shared environmental semantics across THz radio maps from different beam directions, we introduce a novel voting-based sensing scheme, where obstacles are detected by aggregating votes from THz radio maps generated by the CGAN. Simulation results demonstrate that the proposed framework outperforms non-integrated baselines in both radio map construction and obstacle sensing, achieving up to 44.3% and 90.6% reductions in mean squared error (MSE), respectively, in a real-world scenario. These results validate the effectiveness of the proposed voting-based scheme.
Towards THz-based Obstacle Sensing: A Generative Radio Environment Awareness Framework
Feb 11, 2025Obstacle sensing is essential for terahertz (THz) communication since the subsequent beam management can avoid THz signals blocked by the obstacles. In parallel, radio environment, which can be manifested by channel knowledge such as the distribution of received signal strength (RSS), reveals signal propagation situation and the corresponding obstacle information. However, the awareness of the radio environment for obstacle sensing is challenging in practice, as the sparsely deployed THz sensors can acquire only little a priori knowledge with their RSS measurements. Therefore, we formulate in this paper a radio environment awareness problem, which for the first time considers a probability distribution of obstacle attributes. To solve such a problem, we propose a THz-based generative radio environment awareness framework, in which obstacle information is obtained directly from the aware radio environment. We also propose a novel generative model based on conditional generative adversarial network (CGAN), where U-net and the objective function of the problem are introduced to enable accurate awareness of RSS distribution. Simulation results show that the proposed framework can improve the awareness of the radio environment, and thus achieve superior sensing performance in terms of average precision regarding obstacles' shape and location.
ChemAgent: Self-updating Library in Large Language Models Improves Chemical Reasoning
Jan 11, 2025
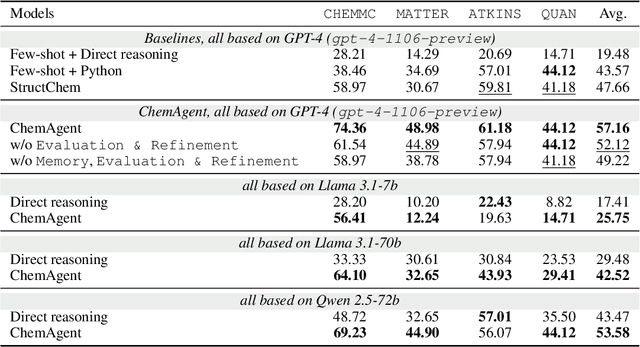
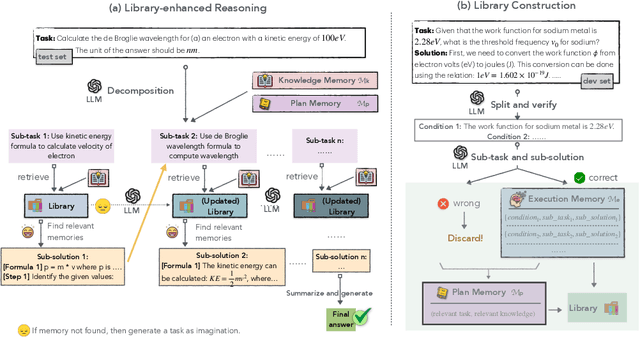
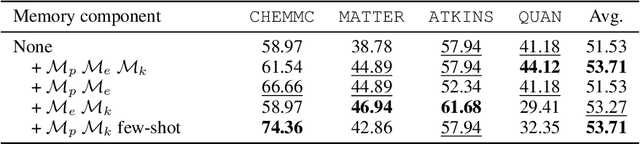
Chemical reasoning usually involves complex, multi-step processes that demand precise calculations, where even minor errors can lead to cascading failures. Furthermore, large language models (LLMs) encounter difficulties handling domain-specific formulas, executing reasoning steps accurately, and integrating code effectively when tackling chemical reasoning tasks. To address these challenges, we present ChemAgent, a novel framework designed to improve the performance of LLMs through a dynamic, self-updating library. This library is developed by decomposing chemical tasks into sub-tasks and compiling these sub-tasks into a structured collection that can be referenced for future queries. Then, when presented with a new problem, ChemAgent retrieves and refines pertinent information from the library, which we call memory, facilitating effective task decomposition and the generation of solutions. Our method designs three types of memory and a library-enhanced reasoning component, enabling LLMs to improve over time through experience. Experimental results on four chemical reasoning datasets from SciBench demonstrate that ChemAgent achieves performance gains of up to 46% (GPT-4), significantly outperforming existing methods. Our findings suggest substantial potential for future applications, including tasks such as drug discovery and materials science. Our code can be found at https://github.com/gersteinlab/chemagent
CreDes: Causal Reasoning Enhancement and Dual-End Searching for Solving Long-Range Reasoning Problems using LLMs
Oct 02, 2024Large language models (LLMs) have demonstrated limitations in handling combinatorial optimization problems involving long-range reasoning, partially due to causal hallucinations and huge search space. As for causal hallucinations, i.e., the inconsistency between reasoning and corresponding state transition, this paper introduces the Causal Relationship Enhancement (CRE) mechanism combining cause-effect interventions and the Individual Treatment Effect (ITE) to guarantee the solid causal rightness between each step of reasoning and state transition. As for the long causal range and huge search space limiting the performances of existing models featuring single-direction search, a Dual-End Searching (DES) approach is proposed to seek solutions by simultaneously starting from both the initial and goal states on the causal probability tree. By integrating CRE and DES (CreDes), our model has realized simultaneous multi-step reasoning, circumventing the inefficiencies from cascading multiple one-step reasoning like the Chain-of-Thought (CoT). Experiments demonstrate that CreDes significantly outperforms existing State-Of-The-Art (SOTA) solutions in long-range reasoning tasks in terms of both accuracy and time efficiency.
Online Learning of Multiple Tasks and Their Relationships : Testing on Spam Email Data and EEG Signals Recorded in Construction Fields
Jun 26, 2024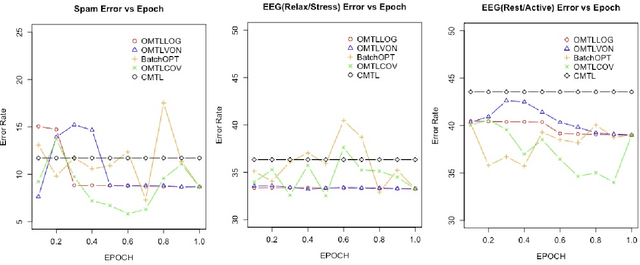

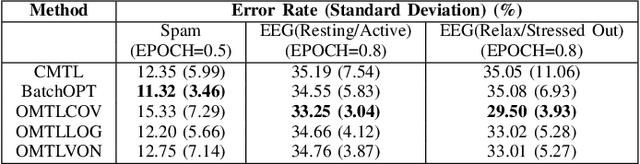
This paper examines an online multi-task learning (OMTL) method, which processes data sequentially to predict labels across related tasks. The framework learns task weights and their relatedness concurrently. Unlike previous models that assumed static task relatedness, our approach treats tasks as initially independent, updating their relatedness iteratively using newly calculated weight vectors. We introduced three rules to update the task relatedness matrix: OMTLCOV, OMTLLOG, and OMTLVON, and compared them against a conventional method (CMTL) that uses a fixed relatedness value. Performance evaluations on three datasets a spam dataset and two EEG datasets from construction workers under varying conditions demonstrated that our OMTL methods outperform CMTL, improving accuracy by 1\% to 3\% on EEG data, and maintaining low error rates around 12\% on the spam dataset.
Enhancing Short-Term Wind Speed Forecasting using Graph Attention and Frequency-Enhanced Mechanisms
May 22, 2023



The safe and stable operation of power systems is greatly challenged by the high variability and randomness of wind power in large-scale wind-power-integrated grids. Wind power forecasting is an effective solution to tackle this issue, with wind speed forecasting being an essential aspect. In this paper, a Graph-attentive Frequency-enhanced Spatial-Temporal Wind Speed Forecasting model based on graph attention and frequency-enhanced mechanisms, i.e., GFST-WSF, is proposed to improve the accuracy of short-term wind speed forecasting. The GFST-WSF comprises a Transformer architecture for temporal feature extraction and a Graph Attention Network (GAT) for spatial feature extraction. The GAT is specifically designed to capture the complex spatial dependencies among wind speed stations to effectively aggregate information from neighboring nodes in the graph, thus enhancing the spatial representation of the data. To model the time lag in wind speed correlation between adjacent wind farms caused by geographical factors, a dynamic complex adjacency matrix is formulated and utilized by the GAT. Benefiting from the effective spatio-temporal feature extraction and the deep architecture of the Transformer, the GFST-WSF outperforms other baselines in wind speed forecasting for the 6-24 hours ahead forecast horizon in case studies.