 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2MBench: A Benchmark for Out-of-Distribution Text-to-Motion Generation
Feb 14, 2026Most existing evaluations of text-to-motion generation focus on in-distribution textual inputs and a limited set of evaluation criteria, which restricts their ability to systematically assess model generalization and motion generation capabilities under complex out-of-distribution (OOD) textual conditions. To address this limitation, we propose a benchmark specifically designed for OOD text-to-motion evaluation, which includes a comprehensive analysis of 14 representative baseline models and the two datasets derived from evaluation results. Specifically, we construct an OOD prompt dataset consisting of 1,025 textual descriptions. Based on this prompt dataset, we introduce a unified evaluation framework that integrates LLM-based Evaluation, Multi-factor Motion evaluation, and Fine-grained Accuracy Evaluation. Our experimental results reveal that while different baseline models demonstrate strengths in areas such as text-to-motion semantic alignment, motion generalizability, and physical quality, most models struggle to achieve strong performance with Fine-grained Accuracy Evaluation. These findings highlight the limitations of existing methods in OOD scenarios and offer practical guidance for the design and evaluation of future production-level text-to-motion models.
LP-DETR: Layer-wise Progressive Relations for Object Detection
Feb 07, 2025



This paper presents LP-DETR (Layer-wise Progressive DETR), a novel approach that enhances DETR-based object detection through multi-scale relation modeling. Our method introduces learnable spatial relationships between object queries through a relation-aware self-attention mechanism, which adaptively learns to balance different scales of relations (local, medium and global) across decoder layers. This progressive design enables the model to effectively capture evolving spatial dependencies throughout the detection pipeline. Extensive experiments on COCO 2017 dataset demonstrate that our method improves both convergence speed and detection accuracy compared to standard self-attention module. The proposed method achieves competitive results, reaching 52.3\% AP with 12 epochs and 52.5\% AP with 24 epochs using ResNet-50 backbone, and further improving to 58.0\% AP with Swin-L backbone. Furthermore, our analysis reveals an interesting pattern: the model naturally learns to prioritize local spatial relations in early decoder layers while gradually shifting attention to broader contexts in deeper layers, providing valuable insights for future research in object detection.
CoVis: A Collaborative Framework for Fine-grained Graphic Visual Understanding
Nov 27, 2024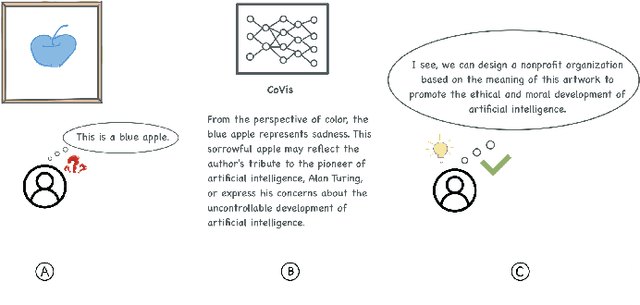
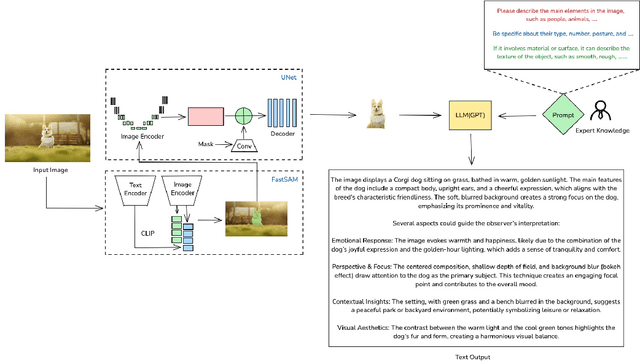
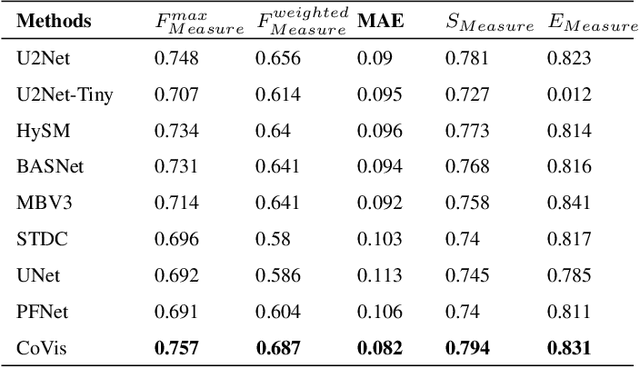

Graphic visual content helps in promoting information communication and inspiration divergence. However, the interpretation of visual content currently relies mainly on humans' personal knowledge background, thereby affecting the quality and efficiency of information acquisition and understanding. To improve the quality and efficiency of visual information transmission and avoid the limitation of the observer due to the information cocoon, we propose CoVis, a collaborative framework for fine-grained visual understanding. By designing and implementing a cascaded dual-layer segmentation network coupled with a large-language-model (LLM) based content generator, the framework extracts as much knowledge as possible from an image. Then, it generates visual analytics for images, assisting observers in comprehending imagery from a more holistic perspective. Quantitative experiments and qualitative experiments based on 32 human participants indicate that the CoVis has better performance than current methods in feature extraction and can generate more comprehensive and detailed visual descriptions than current general-purpose large models.
Predicting 30-Day Hospital Readmission in Medicare Patients: Insights from an LSTM Deep Learning Model
Oct 23, 2024Readmissions among Medicare beneficiaries are a major problem for the US healthcare system from a perspective of both healthcare operations and patient caregiving outcomes. Our study analyzes Medicare hospital readmissions using LSTM networks with feature engineering to assess feature contributions. We selected variables from admission-level data, inpatient medical history and patient demography. The LSTM model is designed to capture temporal dynamics from admission-level and patient-level data. On a case study on the MIMIC dataset, the LSTM model outperformed the logistic regression baseline, accurately leveraging temporal features to predict readmission. The major features were the Charlson Comorbidity Index, hospital length of stay, the hospital admissions over the past 6 months, while demographic variables were less impactful. This work suggests that LSTM networks offers a more promising approach to improve Medicare patient readmission prediction. It captures temporal interactions in patient databases, enhancing current prediction models for healthcare providers. Adoption of predictive models into clinical practice may be more effective in identifying Medicare patients to provide early and targeted interventions to improve patient outcomes.
Optimization and Application of Cloud-based Deep Learning Architecture for Multi-Source Data Prediction
Oct 16, 2024
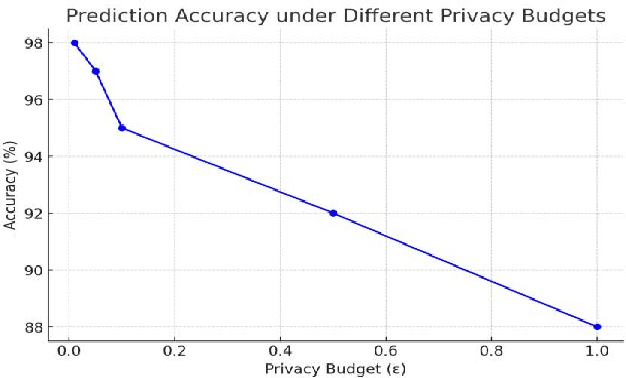
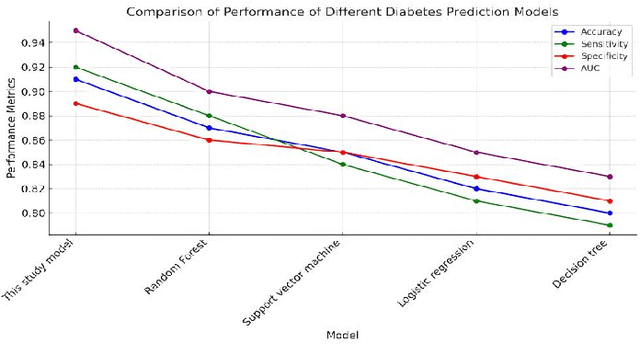
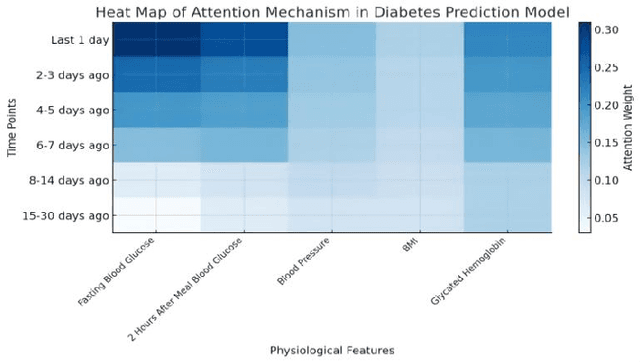
This study develops a cloud-based deep learning system for early prediction of diabetes, leveraging the distributed computing capabilities of the AWS cloud platform and deep learning technologies to achieve efficient and accurate risk assessment. The system utilizes EC2 p3.8xlarge GPU instances to accelerate model training, reducing training time by 93.2% while maintaining a prediction accuracy of 94.2%. With an automated data processing and model training pipeline built using Apache Airflow, the system can complete end-to-end updates within 18.7 hours. In clinical applications, the system demonstrates a prediction accuracy of 89.8%, sensitivity of 92.3%, and specificity of 95.1%. Early interventions based on predictions lead to a 37.5% reduction in diabetes incidence among the target population. The system's high performance and scalability provide strong support for large-scale diabetes prevention and management, showcasing significant public health value.
Online Learning of Multiple Tasks and Their Relationships : Testing on Spam Email Data and EEG Signals Recorded in Construction Fields
Jun 26, 2024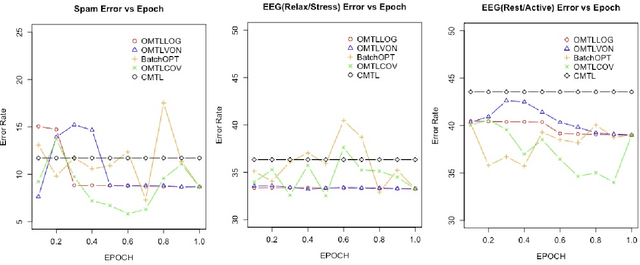

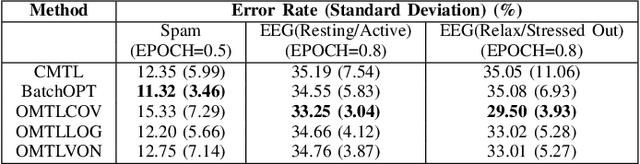
This paper examines an online multi-task learning (OMTL) method, which processes data sequentially to predict labels across related tasks. The framework learns task weights and their relatedness concurrently. Unlike previous models that assumed static task relatedness, our approach treats tasks as initially independent, updating their relatedness iteratively using newly calculated weight vectors. We introduced three rules to update the task relatedness matrix: OMTLCOV, OMTLLOG, and OMTLVON, and compared them against a conventional method (CMTL) that uses a fixed relatedness value. Performance evaluations on three datasets a spam dataset and two EEG datasets from construction workers under varying conditions demonstrated that our OMTL methods outperform CMTL, improving accuracy by 1\% to 3\% on EEG data, and maintaining low error rates around 12\% on the spam dataset.