 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Summarization of Twitter
Jul 11, 2024
In this paper, we describe our approaches to TREC Real-Time Summarization of Twitter. We focus on real time push notification scenario, which requires a system monitors the stream of sampled tweets and returns the tweets relevant and novel to given interest profiles. Dirichlet score with and with very little smoothing (baseline) are employed to classify whether a tweet is relevant to a given interest profile. Using metrics including Mean Average Precision (MAP, cumulative gain (CG) and discount cumulative gain (DCG), the experiment indicates that our approach has a good performance. It is also desired to remove the redundant tweets from the pushing queue. Due to the precision limit, we only describe the algorithm in this paper.
Online Learning of Multiple Tasks and Their Relationships : Testing on Spam Email Data and EEG Signals Recorded in Construction Fields
Jun 26, 2024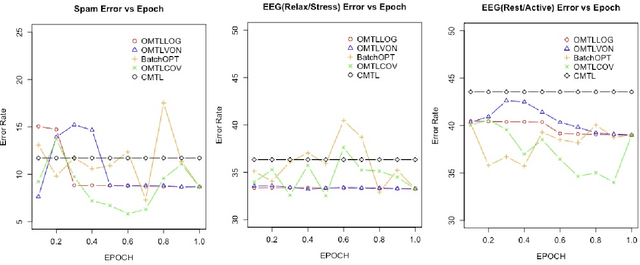

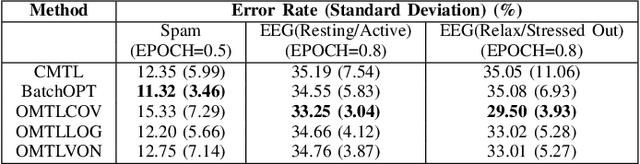
This paper examines an online multi-task learning (OMTL) method, which processes data sequentially to predict labels across related tasks. The framework learns task weights and their relatedness concurrently. Unlike previous models that assumed static task relatedness, our approach treats tasks as initially independent, updating their relatedness iteratively using newly calculated weight vectors. We introduced three rules to update the task relatedness matrix: OMTLCOV, OMTLLOG, and OMTLVON, and compared them against a conventional method (CMTL) that uses a fixed relatedness value. Performance evaluations on three datasets a spam dataset and two EEG datasets from construction workers under varying conditions demonstrated that our OMTL methods outperform CMTL, improving accuracy by 1\% to 3\% on EEG data, and maintaining low error rates around 12\% on the spam dataset.
CLIPLoss and Norm-Based Data Selection Methods for Multimodal Contrastive Learning
May 29, 2024Data selection has emerged as a core issue for large-scale visual-language model pretaining (e.g., CLIP), particularly with noisy web-curated datasets. Three main data selection approaches are: (1) leveraging external non-CLIP models to aid data selection, (2) training new CLIP-style embedding models that are more effective at selecting high-quality data than the original OpenAI CLIP model, and (3) designing better metrics or strategies universally applicable to any CLIP embedding without requiring specific model properties (e.g., CLIPScore is one popular metric). While the first two approaches have been extensively studied, the third remains under-explored. In this paper, we advance the third approach by proposing two new methods. Firstly, instead of classical CLIP scores that only consider the alignment between two modalities from a single sample, we introduce negCLIPLoss, a CLIP loss-inspired method that adds the alignment between one sample and its contrastive pairs as an extra normalization term for better quality measurement. Secondly, when downstream tasks are known, we propose a new norm-based metric, NormSim, to measure the similarity between pretraining data and target data. We test our methods on the data selection benchmark, DataComp~\cite{gadre2023datacomp}. Compared to the best baseline using only OpenAI's CLIP-L/14, our methods achieve a 5.3\% improvement on ImageNet-1k and a 2.8\% improvement on 38 downstream evaluation tasks. Moreover, both negCLIPLoss and NormSim are compatible with existing techniques. By combining our methods with the current best methods DFN~\cite{fang2023data} and HYPE~\cite{kim2024hype}, we can boost average performance on downstream tasks by 0.9\%, achieving a new state-of-the-art.
A Comparative Study on Enhancing Prediction in Social Network Advertisement through Data Augmentation
Apr 28, 2024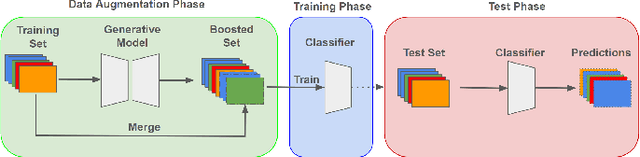
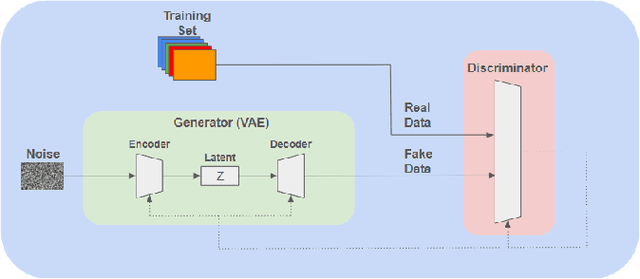
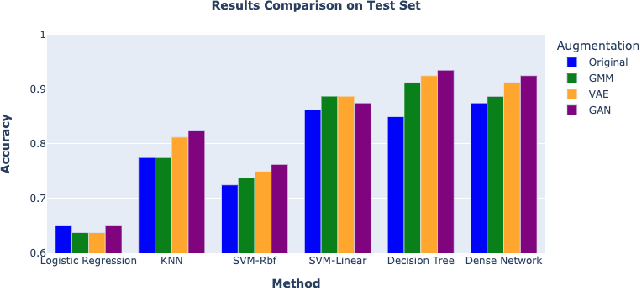
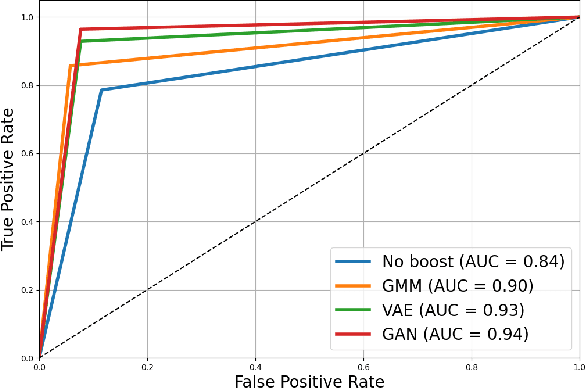
In the ever-evolving landscape of social network advertising, the volume and accuracy of data play a critical role in the performance of predictive models. However, the development of robust predictive algorithms is often hampered by the limited size and potential bias present in real-world datasets. This study presents and explores a generative augmentation framework of social network advertising data. Our framework explores three generative models for data augmentation - Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Gaussian Mixture Models (GMMs) - to enrich data availability and diversity in the context of social network advertising analytics effectiveness. By performing synthetic extensions of the feature space, we find that through data augmentation, the performance of various classifiers has been quantitatively improved. Furthermore, we compare the relative performance gains brought by each data augmentation technique, providing insights for practitioners to select appropriate techniques to enhance model performance. This paper contributes to the literature by showing that synthetic data augmentation alleviates the limitations imposed by small or imbalanced datasets in the field of social network advertising. At the same time, this article also provides a comparative perspective on the practicality of different data augmentation methods, thereby guiding practitioners to choose appropriate techniques to enhance model performance.
Adaptive speed planning for Unmanned Vehicle Based on Deep Reinforcement Learning
Apr 26, 2024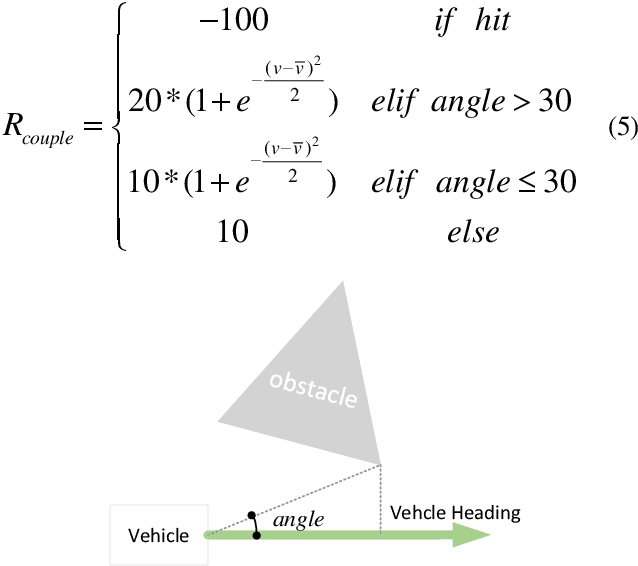
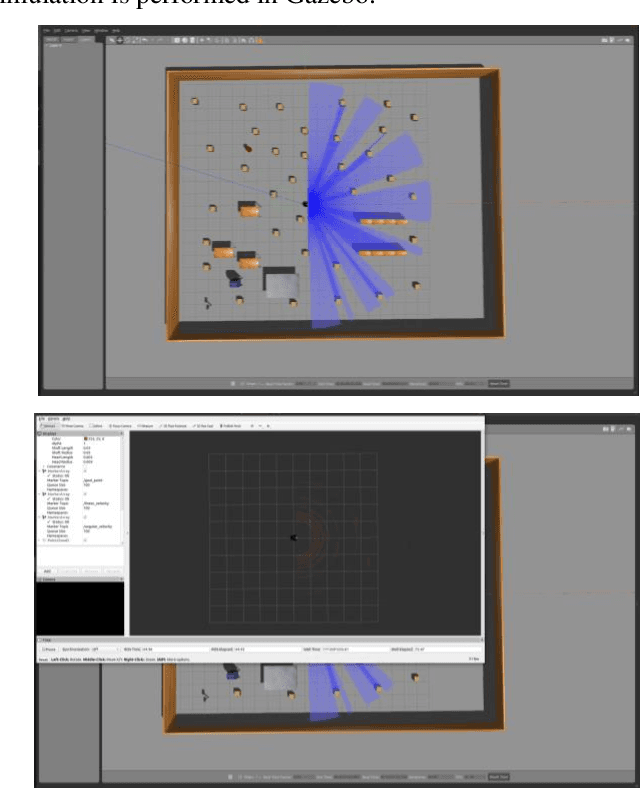
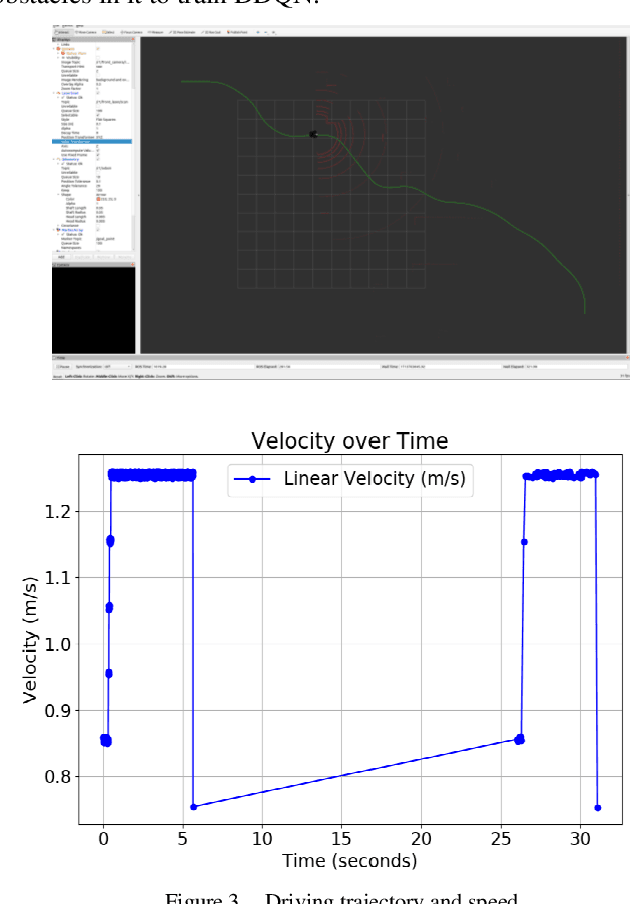

In order to solve the problem of frequent deceleration of unmanned vehicles when approaching obstacles, this article uses a Deep Q-Network (DQN) and its extension, the Double Deep Q-Network (DDQN), to develop a local navigation system that adapts to obstacles while maintaining optimal speed planning. By integrating improved reward functions and obstacle angle determination methods, the system demonstrates significant enhancements in maneuvering capabilities without frequent decelerations. Experiments conducted in simulated environments with varying obstacle densities confirm the effectiveness of the proposed method in achieving more stable and efficient path planning.
Localization Through Particle Filter Powered Neural Network Estimated Monocular Camera Poses
Apr 26, 2024The reduced cost and computational and calibration requirements of monocular cameras make them ideal positioning sensors for mobile robots, albeit at the expense of any meaningful depth measurement. Solutions proposed by some scholars to this localization problem involve fusing pose estimates from convolutional neural networks (CNNs) with pose estimates from geometric constraints on motion to generate accurate predictions of robot trajectories. However, the distribution of attitude estimation based on CNN is not uniform, resulting in certain translation problems in the prediction of robot trajectories. This paper proposes improving these CNN-based pose estimates by propagating a SE(3) uniform distribution driven by a particle filter. The particles utilize the same motion model used by the CNN, while updating their weights using CNN-based estimates. The results show that while the rotational component of pose estimation does not consistently improve relative to CNN-based estimation, the translational component is significantly more accurate. This factor combined with the superior smoothness of the filtered trajectories shows that the use of particle filters significantly improves the performance of CNN-based localization algorithms.
Utilizing Deep Learning to Optimize Software Development Processes
Apr 21, 2024This study explores the application of deep learning technologies in software development processes, particularly in automating code reviews, error prediction, and test generation to enhance code quality and development efficiency. Through a series of empirical studies, experimental groups using deep learning tools and control groups using traditional methods were compared in terms of code error rates and project completion times. The results demonstrated significant improvements in the experimental group, validating the effectiveness of deep learning technologies. The research also discusses potential optimization points, methodologies, and technical challenges of deep learning in software development, as well as how to integrate these technologies into existing software development workflows.
Exploring Diverse Methods in Visual Question Answering
Apr 21, 2024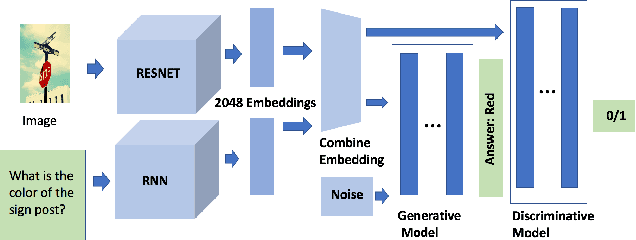
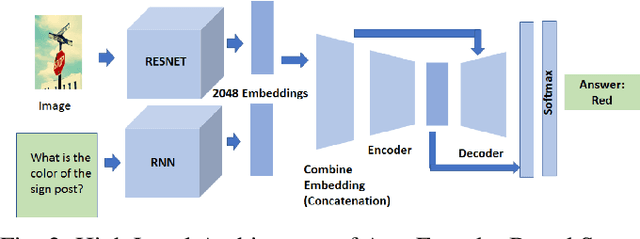
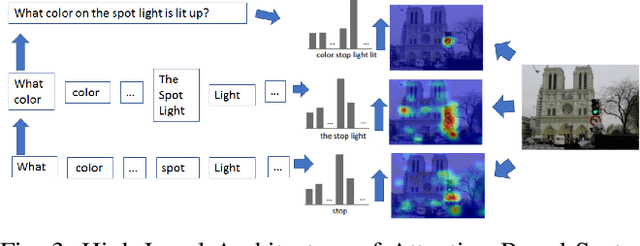

This study explores innovative methods for improving Visual Question Answering (VQA) using Generative Adversarial Networks (GANs), autoencoders, and attention mechanisms. Leveraging a balanced VQA dataset, we investigate three distinct strategies. Firstly, GAN-based approaches aim to generate answer embeddings conditioned on image and question inputs, showing potential but struggling with more complex tasks. Secondly, autoencoder-based techniques focus on learning optimal embeddings for questions and images, achieving comparable results with GAN due to better ability on complex questions. Lastly, attention mechanisms, incorporating Multimodal Compact Bilinear pooling (MCB), address language priors and attention modeling, albeit with a complexity-performance trade-off. This study underscores the challenges and opportunities in VQA and suggests avenues for future research, including alternative GAN formulations and attentional mechanisms.
Graph Distance Neural Networks for Predicting Multiple Drug Interactions
Aug 30, 2022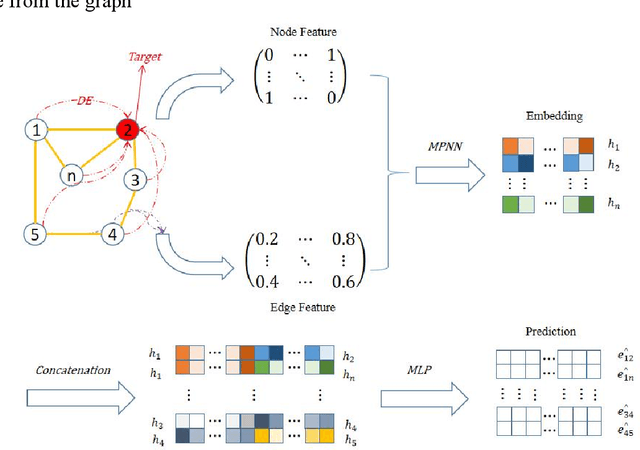
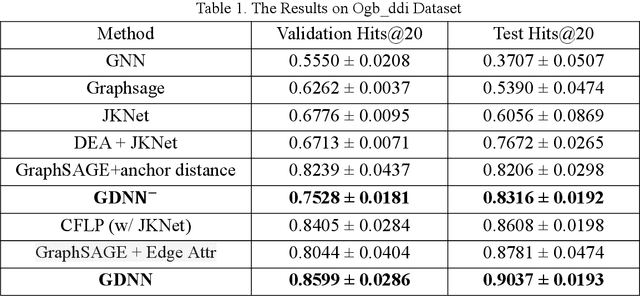
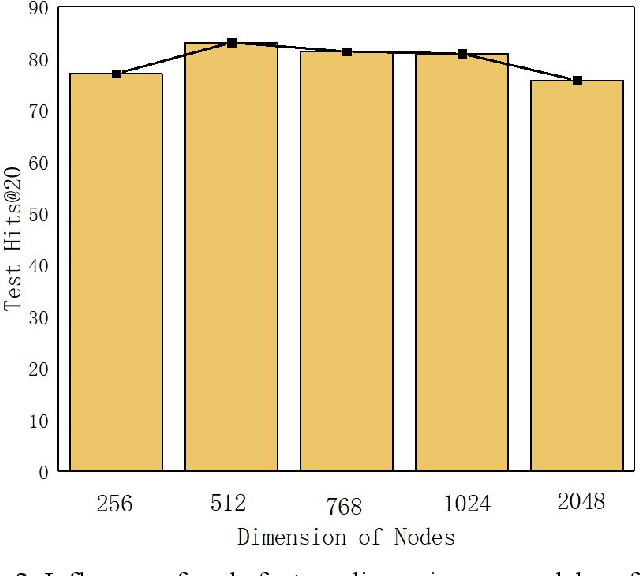
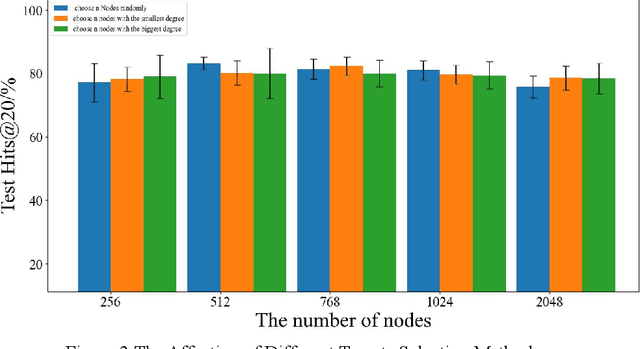
Since multidrug combination is widely applied, the accurate prediction of drug-drug interaction (DDI) is becoming more and more critical. In our method, we use graph to represent drug-drug interaction: nodes represent drug; edges represent drug-drug interactions. Based on our assumption, we convert the prediction of DDI to link prediction problem, utilizing known drug node characteristics and DDI types to predict unknown DDI types. This work proposes a Graph Distance Neural Network (GDNN) to predict drug-drug interactions. Firstly, GDNN generates initial features for nodes via target point method, fully including the distance information in the graph. Secondly, GDNN adopts an improved message passing framework to better generate each drug node embedded expression, comprehensively considering the nodes and edges characteristics synchronously. Thirdly, GDNN aggregates the embedded expressions, undergoing MLP processing to generate the final predicted drug interaction type. GDNN achieved Test Hits@20=0.9037 on the ogb-ddi dataset, proving GDNN can predict DDI efficiently.