 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock Circulant Adapter for Large Language Models
May 01, 2025Fine-tuning large language models (LLMs) is difficult due to their huge model size. Recent Fourier domain-based methods show potential for reducing fine-tuning costs. We propose a block circulant matrix-based fine-tuning method with a stable training heuristic to leverage the properties of circulant matrices and one-dimensional Fourier transforms to reduce storage and computation costs. Experiments show that our method uses $14\times$ less number of parameters than VeRA, $16\times$ smaller than LoRA and $32\times$ less FLOPs than FourierFT, while maintaining close or better task performance. Our approach presents a promising way in frequency domain to fine-tune large models on downstream tasks.
Deep Learning for Medical Text Processing: BERT Model Fine-Tuning and Comparative Study
Oct 28, 2024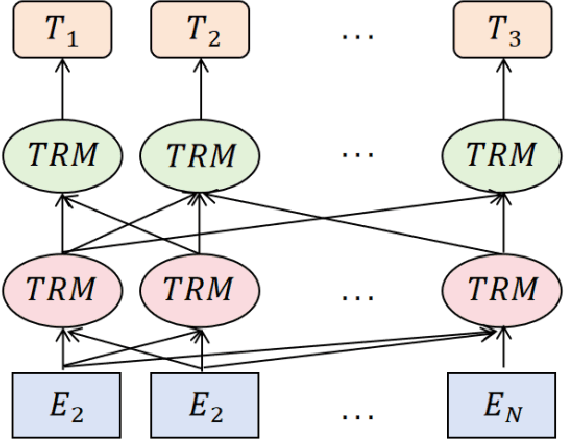
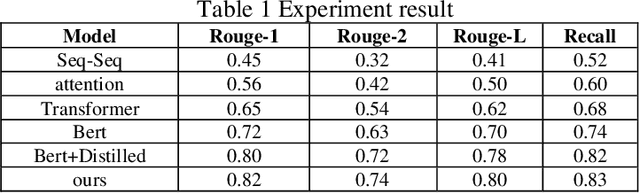
This paper proposes a medical literature summary generation method based on the BERT model to address the challenges brought by the current explosion of medical information. By fine-tuning and optimizing the BERT model, we develop an efficient summary generation system that can quickly extract key information from medical literature and generate coherent, accurate summaries. In the experiment, we compared various models, including Seq-Seq, Attention, Transformer, and BERT, and demonstrated that the improved BERT model offers significant advantages in the Rouge and Recall metrics. Furthermore, the results of this study highlight the potential of knowledge distillation techniques to further enhance model performance. The system has demonstrated strong versatility and efficiency in practical applications, offering a reliable tool for the rapid screening and analysis of medical literature.
Real-Time Summarization of Twitter
Jul 11, 2024
In this paper, we describe our approaches to TREC Real-Time Summarization of Twitter. We focus on real time push notification scenario, which requires a system monitors the stream of sampled tweets and returns the tweets relevant and novel to given interest profiles. Dirichlet score with and with very little smoothing (baseline) are employed to classify whether a tweet is relevant to a given interest profile. Using metrics including Mean Average Precision (MAP, cumulative gain (CG) and discount cumulative gain (DCG), the experiment indicates that our approach has a good performance. It is also desired to remove the redundant tweets from the pushing queue. Due to the precision limit, we only describe the algorithm in this paper.
Online Learning of Multiple Tasks and Their Relationships : Testing on Spam Email Data and EEG Signals Recorded in Construction Fields
Jun 26, 2024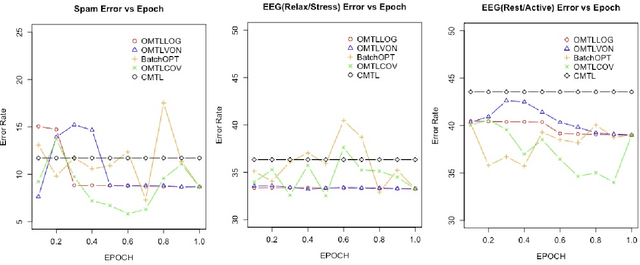

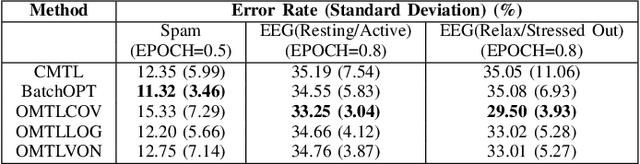
This paper examines an online multi-task learning (OMTL) method, which processes data sequentially to predict labels across related tasks. The framework learns task weights and their relatedness concurrently. Unlike previous models that assumed static task relatedness, our approach treats tasks as initially independent, updating their relatedness iteratively using newly calculated weight vectors. We introduced three rules to update the task relatedness matrix: OMTLCOV, OMTLLOG, and OMTLVON, and compared them against a conventional method (CMTL) that uses a fixed relatedness value. Performance evaluations on three datasets a spam dataset and two EEG datasets from construction workers under varying conditions demonstrated that our OMTL methods outperform CMTL, improving accuracy by 1\% to 3\% on EEG data, and maintaining low error rates around 12\% on the spam dataset.
Exploration of Attention Mechanism-Enhanced Deep Learning Models in the Mining of Medical Textual Data
May 23, 2024



The research explores the utilization of a deep learning model employing an attention mechanism in medical text mining. It targets the challenge of analyzing unstructured text information within medical data. This research seeks to enhance the model's capability to identify essential medical information by incorporating deep learning and attention mechanisms. This paper reviews the basic principles and typical model architecture of attention mechanisms and shows the effectiveness of their application in the tasks of disease prediction, drug side effect monitoring, and entity relationship extraction. Aiming at the particularity of medical texts, an adaptive attention model integrating domain knowledge is proposed, and its ability to understand medical terms and process complex contexts is optimized. The experiment verifies the model's effectiveness in improving task accuracy and robustness, especially when dealing with long text. The future research path of enhancing model interpretation, realizing cross-domain knowledge transfer, and adapting to low-resource scenarios is discussed in the research outlook, which provides a new perspective and method support for intelligent medical information processing and clinical decision assistance. Finally, cross-domain knowledge transfer and adaptation strategies for low-resource scenarios, providing theoretical basis and technical reference for promoting the development of intelligent medical information processing and clinical decision support systems.
Elbert: Fast Albert with Confidence-Window Based Early Exit
Jul 01, 2021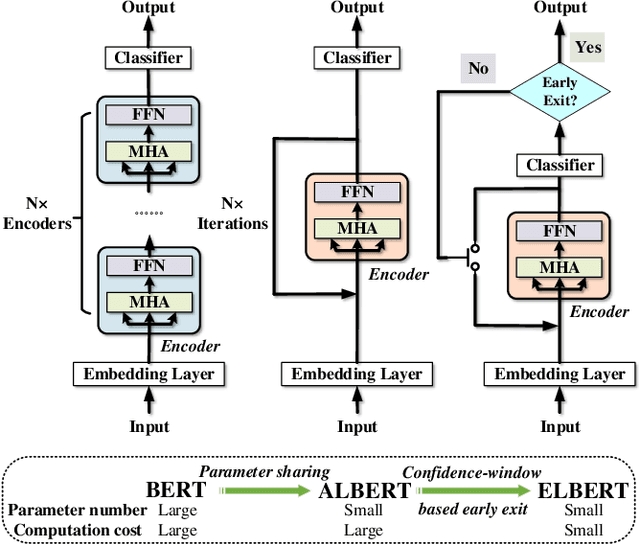
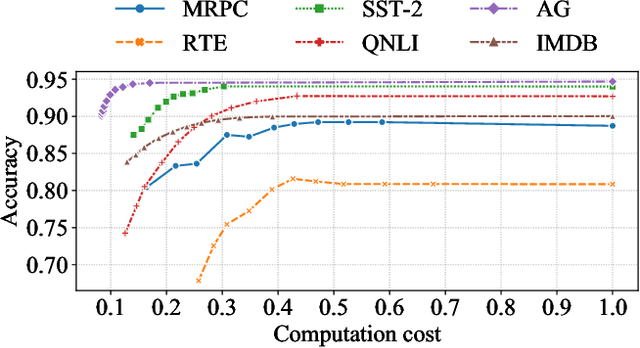
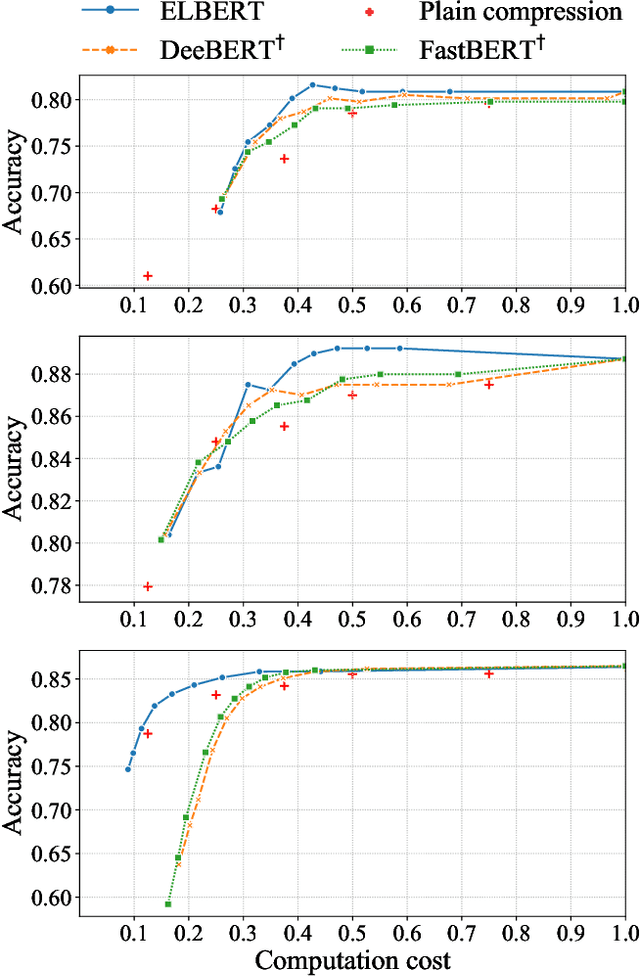
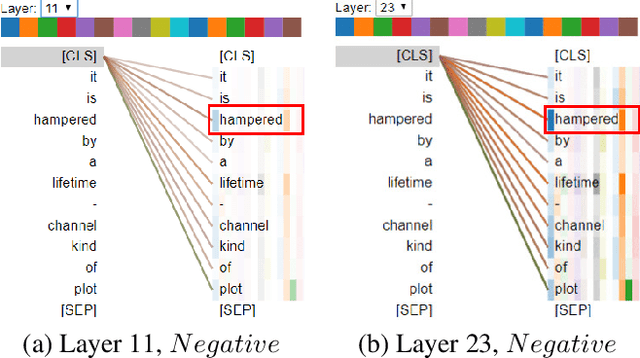
Despite the great success in Natural Language Processing (NLP) area, large pre-trained language models like BERT are not well-suited for resource-constrained or real-time applications owing to the large number of parameters and slow inference speed. Recently, compressing and accelerating BERT have become important topics. By incorporating a parameter-sharing strategy, ALBERT greatly reduces the number of parameters while achieving competitive performance. Nevertheless, ALBERT still suffers from a long inference time. In this work, we propose the ELBERT, which significantly improves the average inference speed compared to ALBERT due to the proposed confidence-window based early exit mechanism, without introducing additional parameters or extra training overhead. Experimental results show that ELBERT achieves an adaptive inference speedup varying from 2$\times$ to 10$\times$ with negligible accuracy degradation compared to ALBERT on various datasets. Besides, ELBERT achieves higher accuracy than existing early exit methods used for accelerating BERT under the same computation cost. Furthermore, to understand the principle of the early exit mechanism, we also visualize the decision-making process of it in ELBERT.
Transform-Based Feature Map Compression for CNN Inference
Jun 24, 2021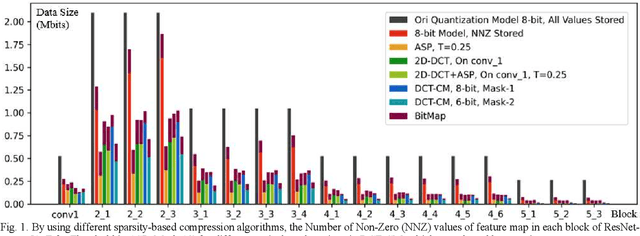
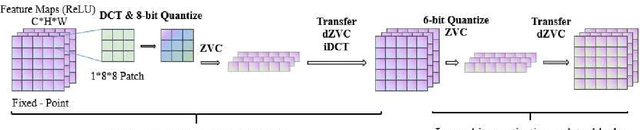
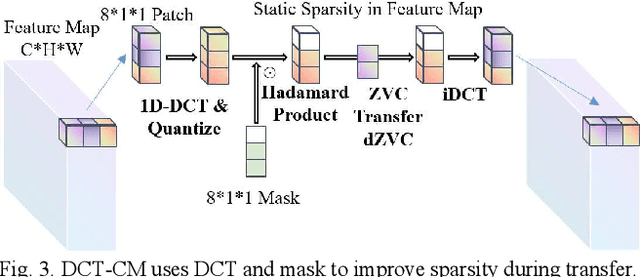
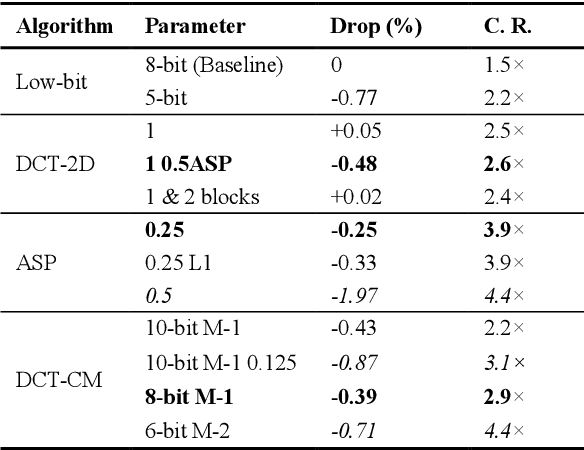
To achieve higher accuracy in machine learning tasks, very deep convolutional neural networks (CNNs) are designed recently. However, the large memory access of deep CNNs will lead to high power consumption. A variety of hardware-friendly compression methods have been proposed to reduce the data transfer bandwidth by exploiting the sparsity of feature maps. Most of them focus on designing a specialized encoding format to increase the compression ratio. Differently, we observe and exploit the sparsity distinction between activations in earlier and later layers to improve the compression ratio. We propose a novel hardware-friendly transform-based method named 1D-Discrete Cosine Transform on Channel dimension with Masks (DCT-CM), which intelligently combines DCT, masks, and a coding format to compress activations. The proposed algorithm achieves an average compression ratio of 2.9x (53% higher than the state-of-the-art transform-based feature map compression works) during inference on ResNet-50 with an 8-bit quantization scheme.
Machine Learning in Heliophysics and Space Weather Forecasting: A White Paper of Findings and Recommendations
Jun 22, 2020The authors of this white paper met on 16-17 January 2020 at the New Jersey Institute of Technology, Newark, NJ, for a 2-day workshop that brought together a group of heliophysicists, data providers, expert modelers, and computer/data scientists. Their objective was to discuss critical developments and prospects of the application of machine and/or deep learning techniques for data analysis, modeling and forecasting in Heliophysics, and to shape a strategy for further developments in the field. The workshop combined a set of plenary sessions featuring invited introductory talks interleaved with a set of open discussion sessions. The outcome of the discussion is encapsulated in this white paper that also features a top-level list of recommendations agreed by participants.
NTIRE 2020 Challenge on NonHomogeneous Dehazing
May 07, 2020
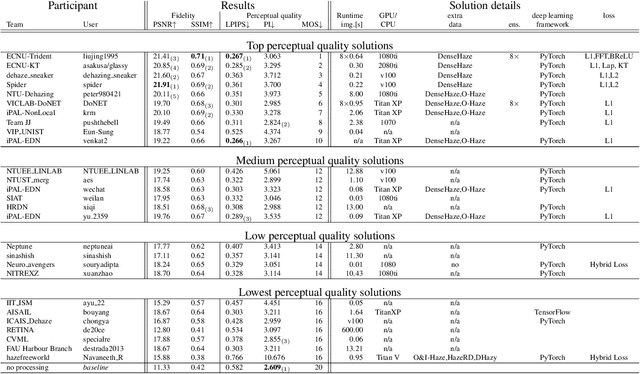
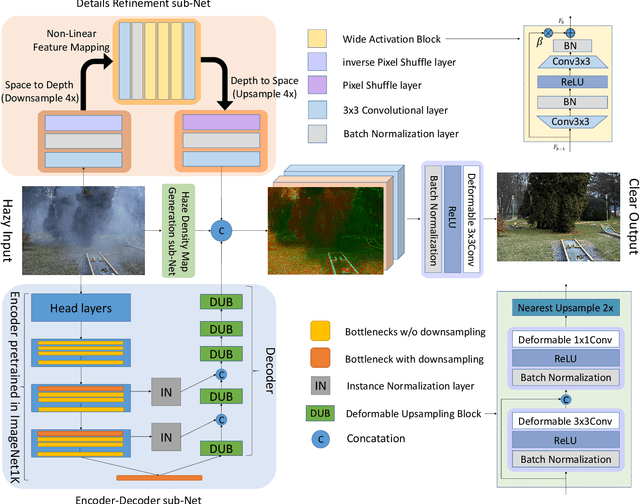
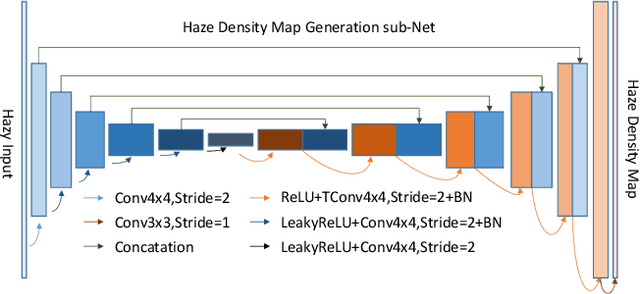
This paper reviews the NTIRE 2020 Challenge on NonHomogeneous Dehazing of images (restoration of rich details in hazy image). We focus on the proposed solutions and their results evaluated on NH-Haze, a novel dataset consisting of 55 pairs of real haze free and nonhomogeneous hazy images recorded outdoor. NH-Haze is the first realistic nonhomogeneous haze dataset that provides ground truth images. The nonhomogeneous haze has been produced using a professional haze generator that imitates the real conditions of haze scenes. 168 participants registered in the challenge and 27 teams competed in the final testing phase. The proposed solutions gauge the state-of-the-art in image dehazing.