 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElbert: Fast Albert with Confidence-Window Based Early Exit
Paper and Code
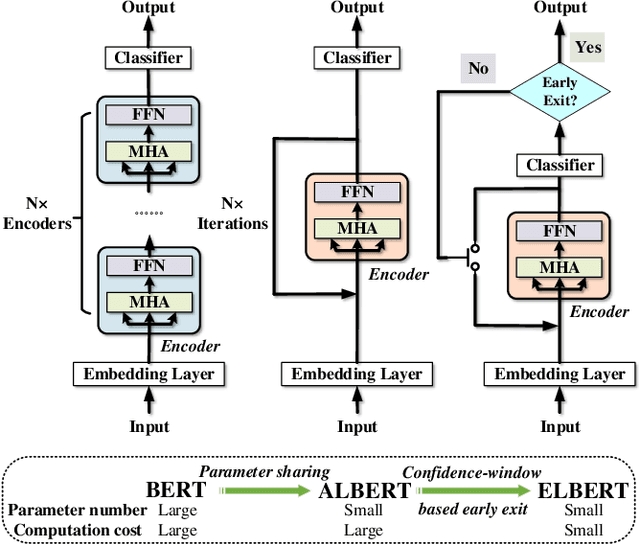
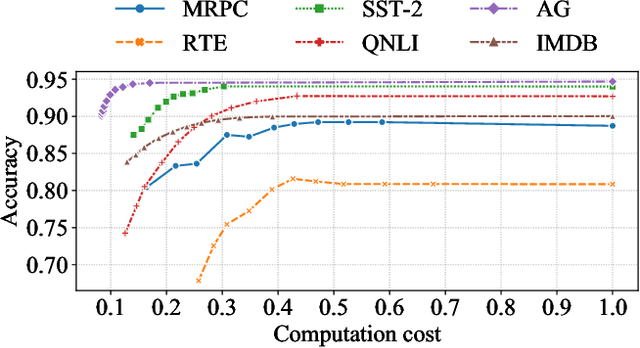
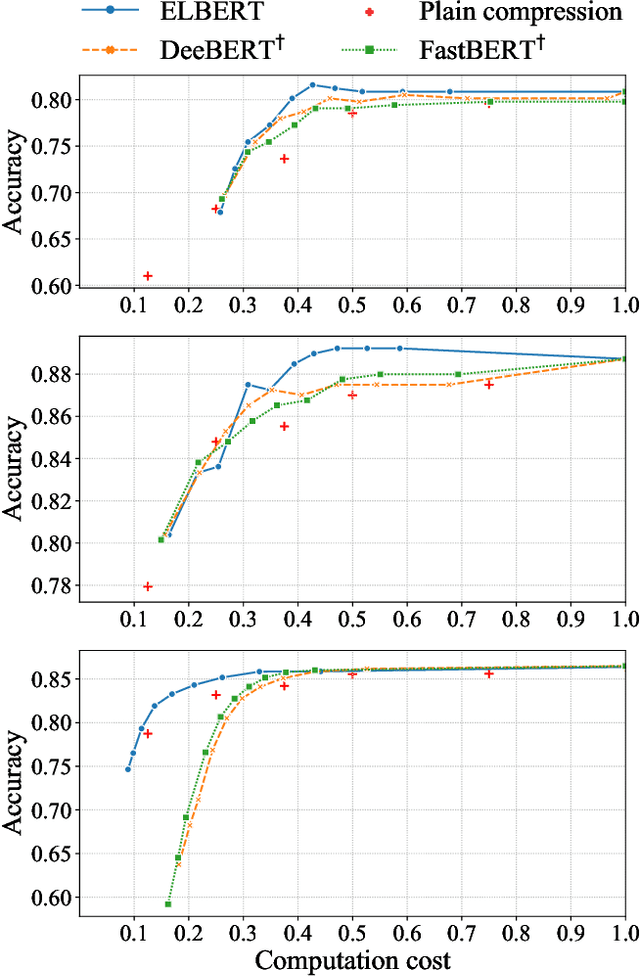
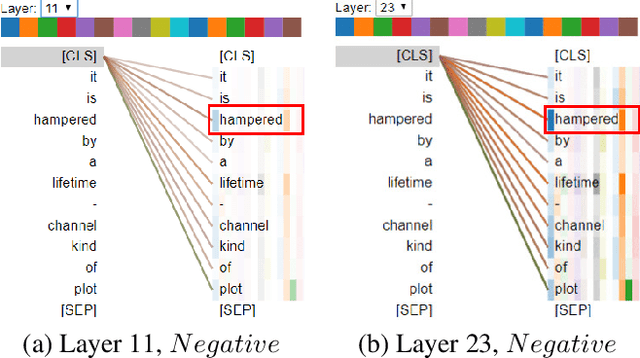
Despite the great success in Natural Language Processing (NLP) area, large pre-trained language models like BERT are not well-suited for resource-constrained or real-time applications owing to the large number of parameters and slow inference speed. Recently, compressing and accelerating BERT have become important topics. By incorporating a parameter-sharing strategy, ALBERT greatly reduces the number of parameters while achieving competitive performance. Nevertheless, ALBERT still suffers from a long inference time. In this work, we propose the ELBERT, which significantly improves the average inference speed compared to ALBERT due to the proposed confidence-window based early exit mechanism, without introducing additional parameters or extra training overhead. Experimental results show that ELBERT achieves an adaptive inference speedup varying from 2$\times$ to 10$\times$ with negligible accuracy degradation compared to ALBERT on various datasets. Besides, ELBERT achieves higher accuracy than existing early exit methods used for accelerating BERT under the same computation cost. Furthermore, to understand the principle of the early exit mechanism, we also visualize the decision-making process of it in ELBERT.