 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH2Tune: Federated Foundation Model Fine-Tuning with Hybrid Heterogeneity
Jul 30, 2025Different from existing federated fine-tuning (FFT) methods for foundation models, hybrid heterogeneous federated fine-tuning (HHFFT) is an under-explored scenario where clients exhibit double heterogeneity in model architectures and downstream tasks. This hybrid heterogeneity introduces two significant challenges: 1) heterogeneous matrix aggregation, where clients adopt different large-scale foundation models based on their task requirements and resource limitations, leading to dimensional mismatches during LoRA parameter aggregation; and 2) multi-task knowledge interference, where local shared parameters, trained with both task-shared and task-specific knowledge, cannot ensure only task-shared knowledge is transferred between clients. To address these challenges, we propose H2Tune, a federated foundation model fine-tuning with hybrid heterogeneity. Our framework H2Tune consists of three key components: (i) sparsified triple matrix decomposition to align hidden dimensions across clients through constructing rank-consistent middle matrices, with adaptive sparsification based on client resources; (ii) relation-guided matrix layer alignment to handle heterogeneous layer structures and representation capabilities; and (iii) alternating task-knowledge disentanglement mechanism to decouple shared and specific knowledge of local model parameters through alternating optimization. Theoretical analysis proves a convergence rate of O(1/\sqrt{T}). Extensive experiments show our method achieves up to 15.4% accuracy improvement compared to state-of-the-art baselines. Our code is available at https://anonymous.4open.science/r/H2Tune-1407.
MorphAgent: Empowering Agents through Self-Evolving Profiles and Decentralized Collaboration
Oct 19, 2024

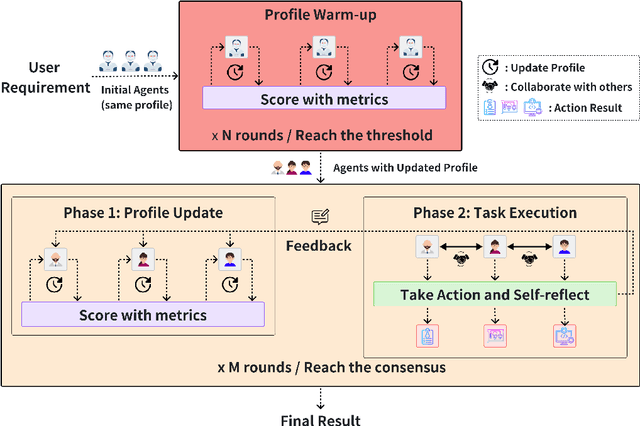
Large Language Model (LLM) based multi-agent systems (MAS) have shown promise in tackling complex tasks, but often rely on predefined roles and centralized coordination, limiting their adaptability to evolving challenges. This paper introduces MorphAgent, a novel framework for decentralized multi-agent collaboration that enables agents to dynamically evolve their roles and capabilities. Our approach employs self-evolving agent profiles, optimized through three key metrics, guiding agents in refining their individual expertise while maintaining complementary team dynamics. MorphAgent implements a two-phase process: a warm-up phase for initial profile optimization, followed by a task execution phase where agents continuously adapt their roles based on task feedback. Our experimental results show that MorphAgent outperforms traditional static-role MAS in terms of task performance and adaptability to changing requirements, paving the way for more robust and versatile multi-agent collaborative systems. Our code will be publicly available at \url{https://github.com/LINs-lab/learn2collaborate}.
Unleashing the Potential of Large Language Models as Prompt Optimizers: An Analogical Analysis with Gradient-based Model Optimizers
Feb 27, 2024
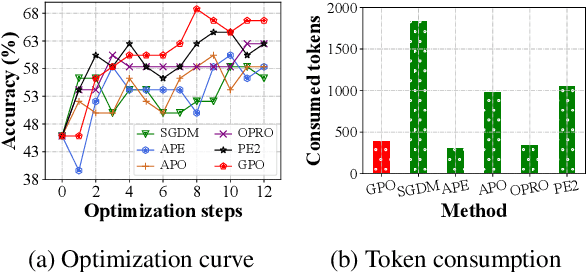

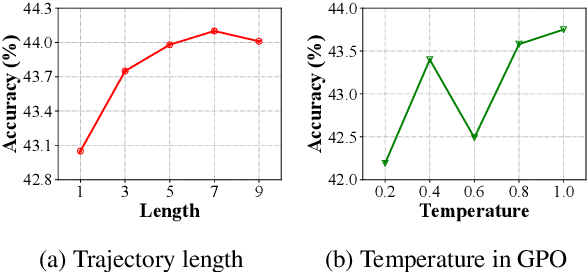
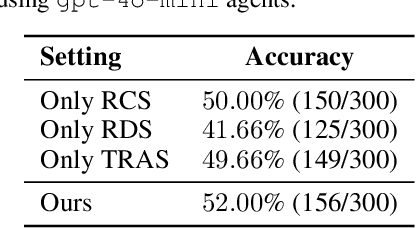
Automatic prompt optimization is an important approach to improving the performance of large language models (LLMs). Recent research demonstrates the potential of using LLMs as prompt optimizers, which can generate improved task prompts via iterative refinement. In this paper, we propose a novel perspective to investigate the design of LLM-based prompt optimizers, by drawing an analogy with gradient-based model optimizers. To connect these two approaches, we identify two pivotal factors in model parameter learning: update direction and update method. Focused on the two aspects, we borrow the theoretical framework and learning methods from gradient-based optimization to design improved strategies for LLM-based prompt optimizers. By systematically analyzing a rich set of improvement strategies, we further develop a capable Gradient-inspired LLM-based Prompt Optimizer called GPO. At each step, it first retrieves relevant prompts from the optimization trajectory as the update direction. Then, it utilizes the generation-based refinement strategy to perform the update, while controlling the edit distance through a cosine-based decay strategy. Extensive experiments demonstrate the effectiveness and efficiency of GPO. In particular, GPO brings an additional improvement of up to 56.8% on Big-Bench Hard and 55.3% on MMLU compared to baseline methods.
PreAct: Predicting Future in ReAct Enhances Agent's Planning Ability
Feb 18, 2024Addressing the discrepancies between predictions and actual outcomes often aids individuals in expanding their thought processes and engaging in reflection, thereby facilitating reasoning in the correct direction. In this paper, we introduce $\textbf{PreAct}$, an agent framework that integrates $\textbf{pre}$diction with $\textbf{rea}$soning and $\textbf{act}$ion. Leveraging the information provided by predictions, a large language model (LLM) based agent can offer more diversified and strategically oriented reasoning, which in turn leads to more effective actions that help the agent complete complex tasks. Our experiments demonstrate that PreAct outperforms the ReAct approach in accomplishing complex tasks and that PreAct can be co-enhanced when combined with Reflexion methods. We prompt the model with different numbers of historical predictions and find that historical predictions have a sustained positive effect on LLM planning. The differences in single-step reasoning between PreAct and ReAct show that PreAct indeed offers advantages in terms of diversity and strategic directivity over ReAct.
Fast and Accurate FSA System Using ELBERT: An Efficient and Lightweight BERT
Dec 06, 2022With the development of deep learning and Transformer-based pre-trained models like BERT, the accuracy of many NLP tasks has been dramatically improved. However, the large number of parameters and computations also pose challenges for their deployment. For instance, using BERT can improve the predictions in the financial sentiment analysis (FSA) task but slow it down, where speed and accuracy are equally important in terms of profits. To address these issues, we first propose an efficient and lightweight BERT (ELBERT) along with a novel confidence-window-based (CWB) early exit mechanism. Based on ELBERT, an innovative method to accelerate text processing on the GPU platform is developed, solving the difficult problem of making the early exit mechanism work more effectively with a large input batch size. Afterward, a fast and high-accuracy FSA system is built. Experimental results show that the proposed CWB early exit mechanism achieves significantly higher accuracy than existing early exit methods on BERT under the same computation cost. By using this acceleration method, our FSA system can boost the processing speed by nearly 40 times to over 1000 texts per second with sufficient accuracy, which is nearly twice as fast as FastBERT, thus providing a more powerful text processing capability for modern trading systems.
Rethinking WMMSE: Can Its Complexity Scale Linearly With the Number of BS Antennas?
May 22, 2022
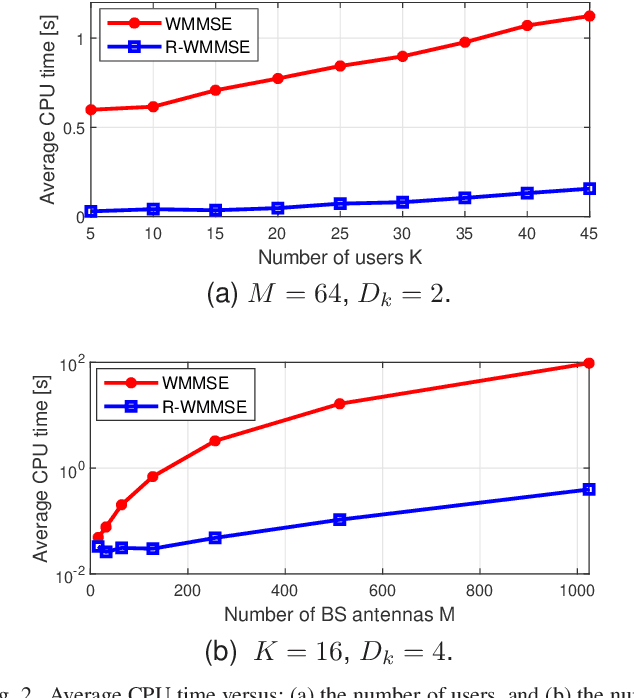

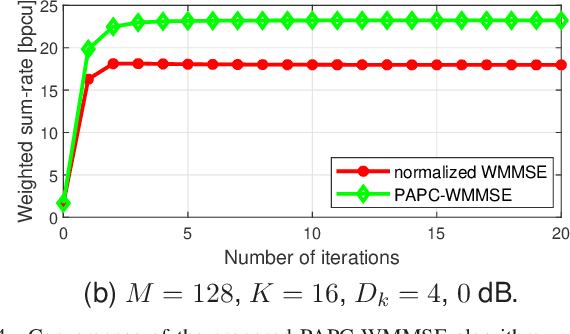
Precoding design for maximizing weighted sum-rate (WSR) is a fundamental problem for downlink of massive multi-user multiple-input multiple-output (MU-MIMO) systems. It is well-known that this problem is generally NP-hard due to the presence of multi-user interference. The weighted minimum mean-square error (WMMSE) algorithm is a popular approach for WSR maximization. However, its computational complexity is cubic in the number of base station (BS) antennas, which is unaffordable when the BS is equipped with a large antenna array. In this paper, we consider the WSR maximization problem with either a sum-power constraint (SPC) or per-antenna power constraints (PAPCs). For the former, we prove that any nontrivial stationary point must have a low-dimensional subspace structure, and then propose a reduced-WMMSE (R-WMMSE) with linear complexity by exploiting the solution structure. For the latter, we propose a linear-complexity WMMSE approach, named PAPC-WMMSE, by using a novel recursive design of the algorithm. Both R-WMMSE and PAPC-WMMSE have simple closed-form updates and guaranteed convergence to stationary points. Simulation results verify the efficacy of the proposed designs, especially the much lower complexity as compared to the state-of-the-art approaches for massive MU-MIMO systems.
Elbert: Fast Albert with Confidence-Window Based Early Exit
Jul 01, 2021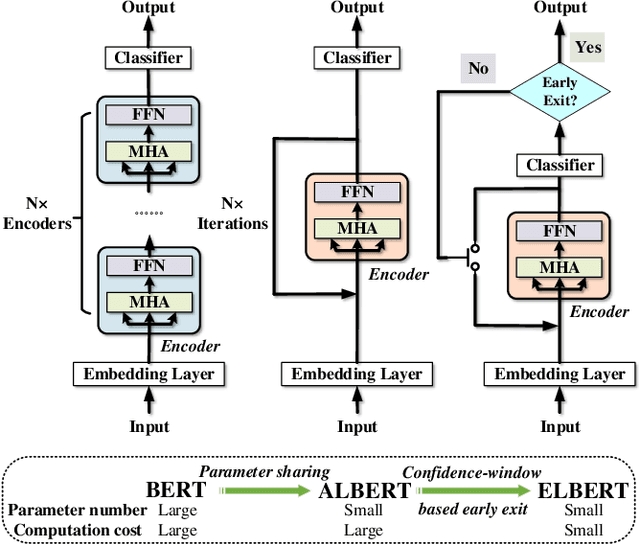
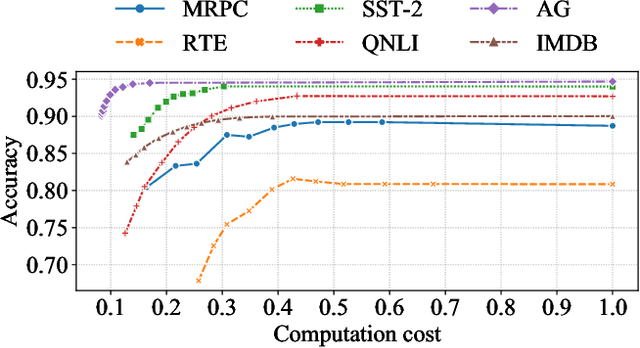
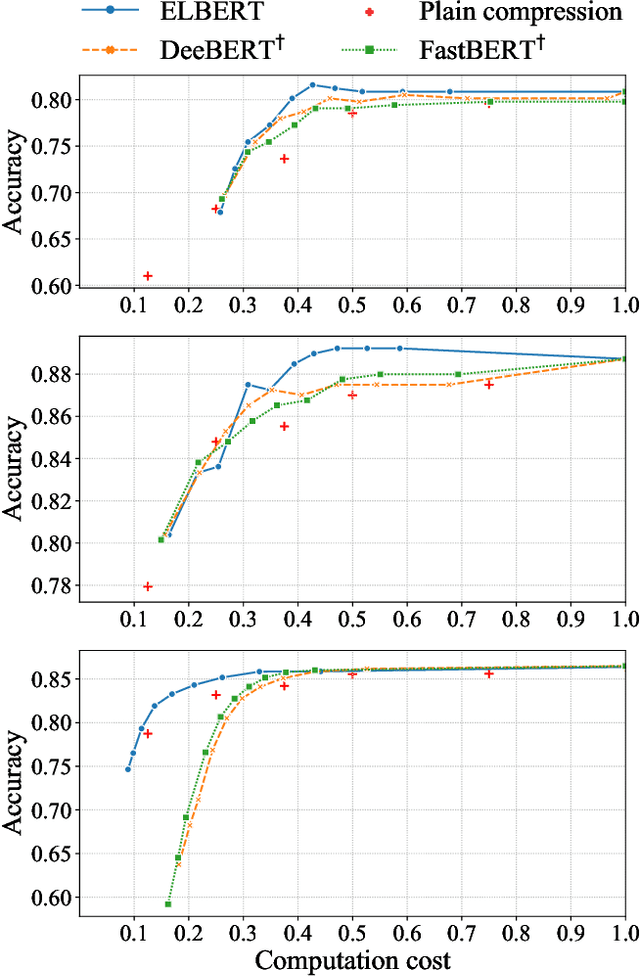
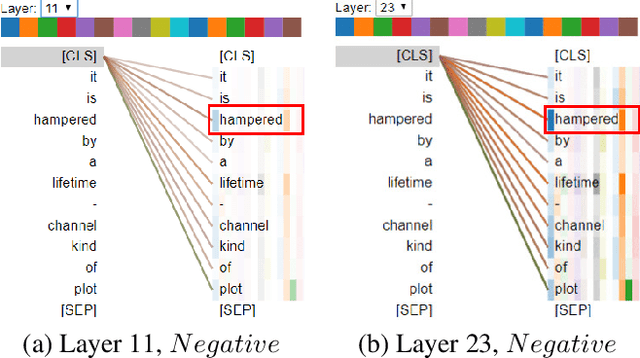
Despite the great success in Natural Language Processing (NLP) area, large pre-trained language models like BERT are not well-suited for resource-constrained or real-time applications owing to the large number of parameters and slow inference speed. Recently, compressing and accelerating BERT have become important topics. By incorporating a parameter-sharing strategy, ALBERT greatly reduces the number of parameters while achieving competitive performance. Nevertheless, ALBERT still suffers from a long inference time. In this work, we propose the ELBERT, which significantly improves the average inference speed compared to ALBERT due to the proposed confidence-window based early exit mechanism, without introducing additional parameters or extra training overhead. Experimental results show that ELBERT achieves an adaptive inference speedup varying from 2$\times$ to 10$\times$ with negligible accuracy degradation compared to ALBERT on various datasets. Besides, ELBERT achieves higher accuracy than existing early exit methods used for accelerating BERT under the same computation cost. Furthermore, to understand the principle of the early exit mechanism, we also visualize the decision-making process of it in ELBERT.
PAIRS AutoGeo: an Automated Machine Learning Framework for Massive Geospatial Data
Dec 12, 2020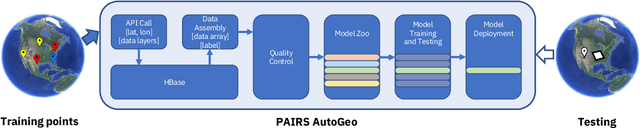
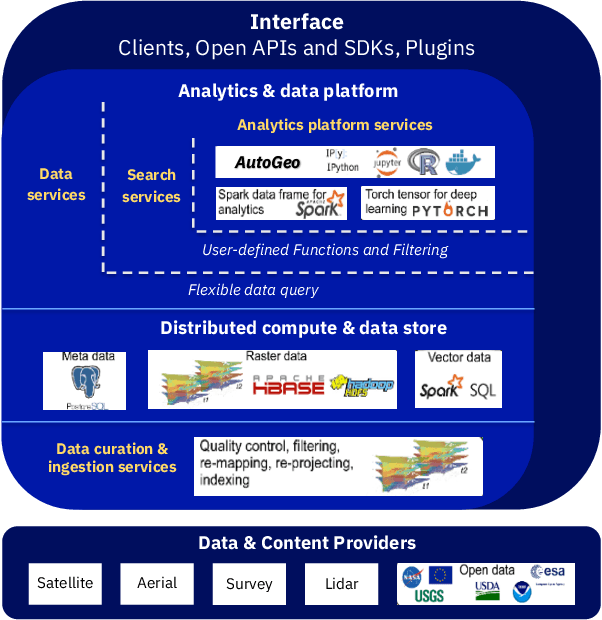

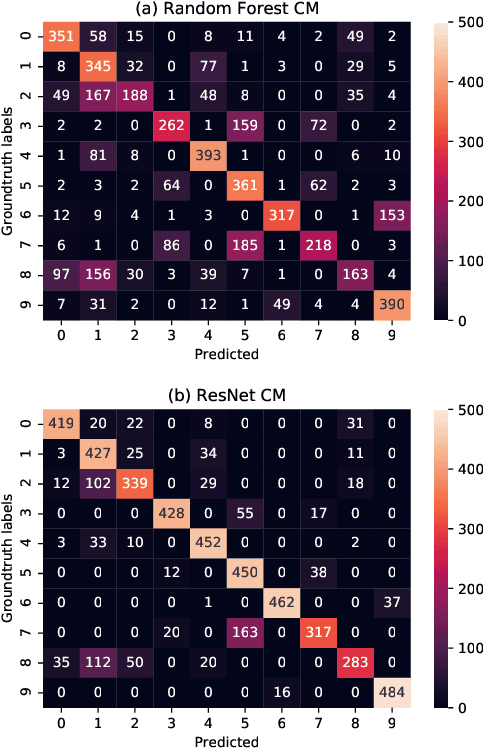
An automated machine learning framework for geospatial data named PAIRS AutoGeo is introduced on IBM PAIRS Geoscope big data and analytics platform. The framework simplifies the development of industrial machine learning solutions leveraging geospatial data to the extent that the user inputs are minimized to merely a text file containing labeled GPS coordinates. PAIRS AutoGeo automatically gathers required data at the location coordinates, assembles the training data, performs quality check, and trains multiple machine learning models for subsequent deployment. The framework is validated using a realistic industrial use case of tree species classification. Open-source tree species data are used as the input to train a random forest classifier and a modified ResNet model for 10-way tree species classification based on aerial imagery, which leads to an accuracy of $59.8\%$ and $81.4\%$, respectively. This use case exemplifies how PAIRS AutoGeo enables users to leverage machine learning without extensive geospatial expertise.
Map Generation from Large Scale Incomplete and Inaccurate Data Labels
May 20, 2020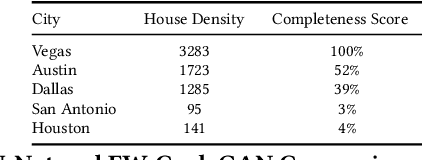
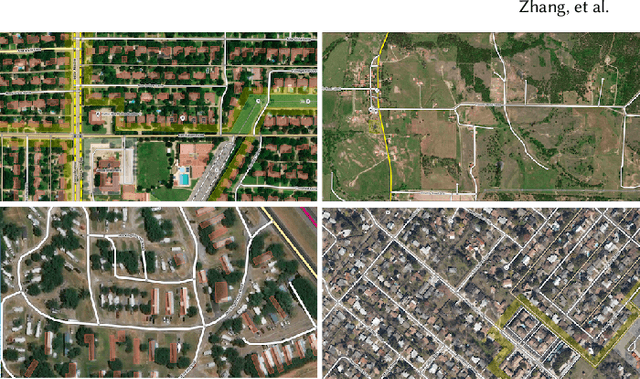

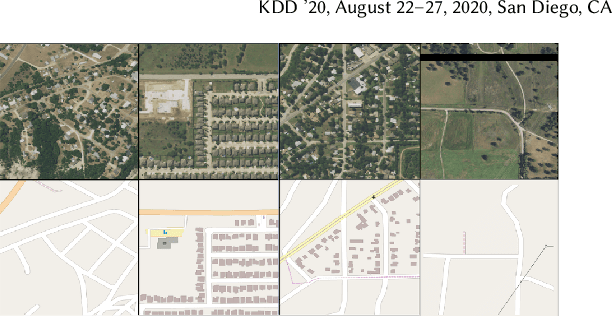
Accurately and globally mapping human infrastructure is an important and challenging task with applications in routing, regulation compliance monitoring, and natural disaster response management etc.. In this paper we present progress in developing an algorithmic pipeline and distributed compute system that automates the process of map creation using high resolution aerial images. Unlike previous studies, most of which use datasets that are available only in a few cities across the world, we utilizes publicly available imagery and map data, both of which cover the contiguous United States (CONUS). We approach the technical challenge of inaccurate and incomplete training data adopting state-of-the-art convolutional neural network architectures such as the U-Net and the CycleGAN to incrementally generate maps with increasingly more accurate and more complete labels of man-made infrastructure such as roads and houses. Since scaling the mapping task to CONUS calls for parallelization, we then adopted an asynchronous distributed stochastic parallel gradient descent training scheme to distribute the computational workload onto a cluster of GPUs with nearly linear speed-up.
Training Deep Neural Networks Using Posit Number System
Sep 06, 2019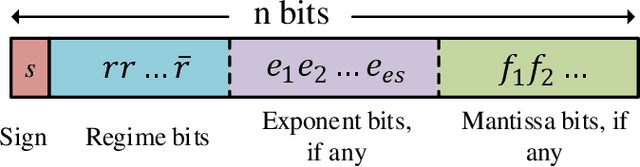
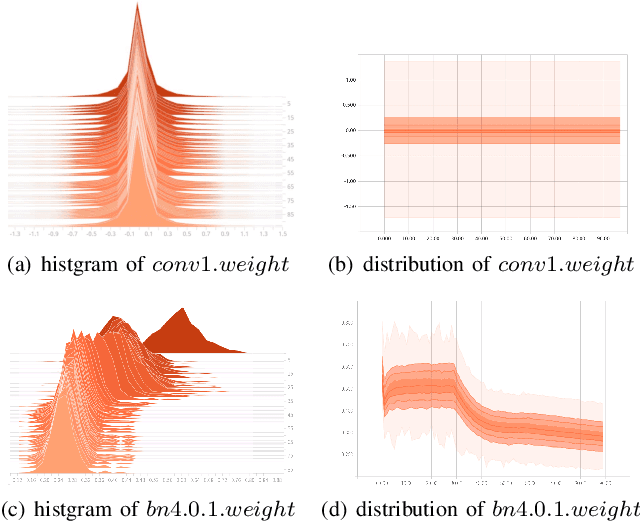
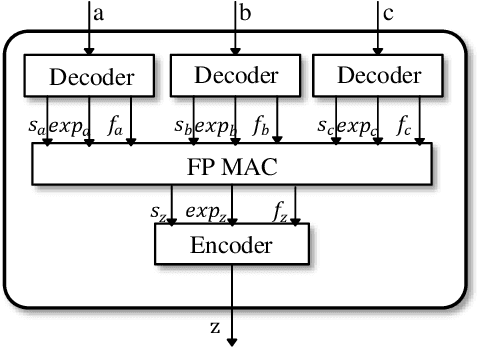
With the increasing size of Deep Neural Network (DNN) models, the high memory space requirements and computational complexity have become an obstacle for efficient DNN implementations. To ease this problem, using reduced-precision representations for DNN training and inference has attracted many interests from researchers. This paper first proposes a methodology for training DNNs with the posit arithmetic, a type- 3 universal number (Unum) format that is similar to the floating point(FP) but has reduced precision. A warm-up training strategy and layer-wise scaling factors are adopted to stabilize training and fit the dynamic range of DNN parameters. With the proposed training methodology, we demonstrate the first successful training of DNN models on ImageNet image classification task in 16 bits posit with no accuracy loss. Then, an efficient hardware architecture for the posit multiply-and-accumulate operation is also proposed, which can achieve significant improvement in energy efficiency than traditional floating-point implementations. The proposed design is helpful for future low-power DNN training accelerators.