 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMBoost: Make Large Language Models Stronger with Boosting
Dec 26, 2025Ensemble learning of LLMs has emerged as a promising alternative to enhance performance, but existing approaches typically treat models as black boxes, combining the inputs or final outputs while overlooking the rich internal representations and interactions across models.In this work, we introduce LLMBoost, a novel ensemble fine-tuning framework that breaks this barrier by explicitly leveraging intermediate states of LLMs. Inspired by the boosting paradigm, LLMBoost incorporates three key innovations. First, a cross-model attention mechanism enables successor models to access and fuse hidden states from predecessors, facilitating hierarchical error correction and knowledge transfer. Second, a chain training paradigm progressively fine-tunes connected models with an error-suppression objective, ensuring that each model rectifies the mispredictions of its predecessor with minimal additional computation. Third, a near-parallel inference paradigm design pipelines hidden states across models layer by layer, achieving inference efficiency approaching single-model decoding. We further establish the theoretical foundations of LLMBoost, proving that sequential integration guarantees monotonic improvements under bounded correction assumptions. Extensive experiments on commonsense reasoning and arithmetic reasoning tasks demonstrate that LLMBoost consistently boosts accuracy while reducing inference latency.
Two-dimensional Sparse Parallelism for Large Scale Deep Learning Recommendation Model Training
Aug 05, 2025The increasing complexity of deep learning recommendation models (DLRM) has led to a growing need for large-scale distributed systems that can efficiently train vast amounts of data. In DLRM, the sparse embedding table is a crucial component for managing sparse categorical features. Typically, these tables in industrial DLRMs contain trillions of parameters, necessitating model parallelism strategies to address memory constraints. However, as training systems expand with massive GPUs, the traditional fully parallelism strategies for embedding table post significant scalability challenges, including imbalance and straggler issues, intensive lookup communication, and heavy embedding activation memory. To overcome these limitations, we propose a novel two-dimensional sparse parallelism approach. Rather than fully sharding tables across all GPUs, our solution introduces data parallelism on top of model parallelism. This enables efficient all-to-all communication and reduces peak memory consumption. Additionally, we have developed the momentum-scaled row-wise AdaGrad algorithm to mitigate performance losses associated with the shift in training paradigms. Our extensive experiments demonstrate that the proposed approach significantly enhances training efficiency while maintaining model performance parity. It achieves nearly linear training speed scaling up to 4K GPUs, setting a new state-of-the-art benchmark for recommendation model training.
Knowledge Transfer across Multiple Principal Component Analysis Studies
Mar 12, 2024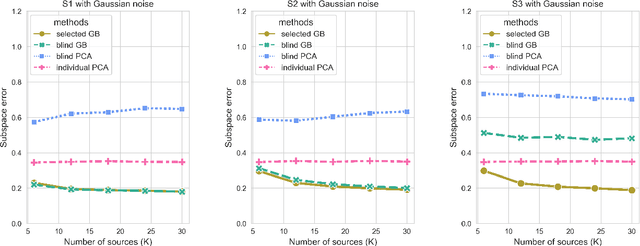
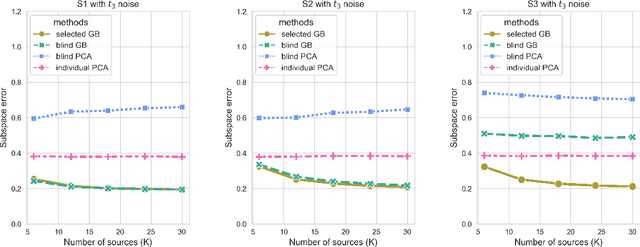
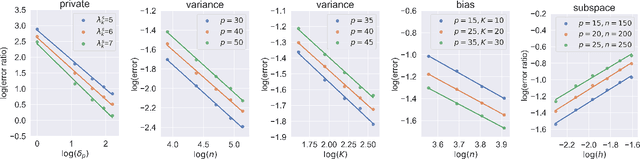
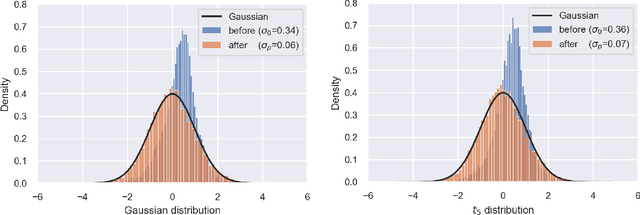
Transfer learning has aroused great interest in the statistical community. In this article, we focus on knowledge transfer for unsupervised learning tasks in contrast to the supervised learning tasks in the literature. Given the transferable source populations, we propose a two-step transfer learning algorithm to extract useful information from multiple source principal component analysis (PCA) studies, thereby enhancing estimation accuracy for the target PCA task. In the first step, we integrate the shared subspace information across multiple studies by a proposed method named as Grassmannian barycenter, instead of directly performing PCA on the pooled dataset. The proposed Grassmannian barycenter method enjoys robustness and computational advantages in more general cases. Then the resulting estimator for the shared subspace from the first step is further utilized to estimate the target private subspace in the second step. Our theoretical analysis credits the gain of knowledge transfer between PCA studies to the enlarged eigenvalue gap, which is different from the existing supervised transfer learning tasks where sparsity plays the central role. In addition, we prove that the bilinear forms of the empirical spectral projectors have asymptotic normality under weaker eigenvalue gap conditions after knowledge transfer. When the set of informativesources is unknown, we endow our algorithm with the capability of useful dataset selection by solving a rectified optimization problem on the Grassmann manifold, which in turn leads to a computationally friendly rectified Grassmannian K-means procedure. In the end, extensive numerical simulation results and a real data case concerning activity recognition are reported to support our theoretical claims and to illustrate the empirical usefulness of the proposed transfer learning methods.
Quantification of Carbon Sequestration in Urban Forests
Jun 01, 2021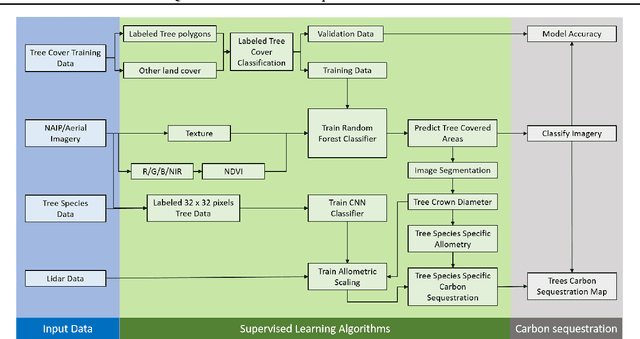



Vegetation, trees in particular, sequester carbon by absorbing carbon dioxide from the atmosphere, however, the lack of efficient quantification methods of carbon stored in trees renders it difficult to track the process. Here we present an approach to estimate the carbon storage in trees based on fusing multispectral aerial imagery and LiDAR data to identify tree coverage, geometric shape, and tree species, which are crucial attributes in carbon storage quantification. We demonstrate that tree species information and their three-dimensional geometric shapes can be estimated from remote imagery in order to calculate the tree's biomass. Specifically, for Manhattan, New York City, we estimate a total of $52,000$ tons of carbon sequestered in trees.
PAIRS AutoGeo: an Automated Machine Learning Framework for Massive Geospatial Data
Dec 12, 2020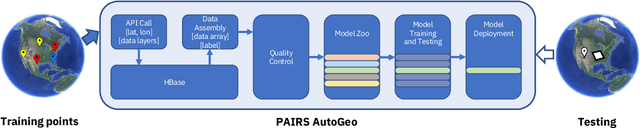
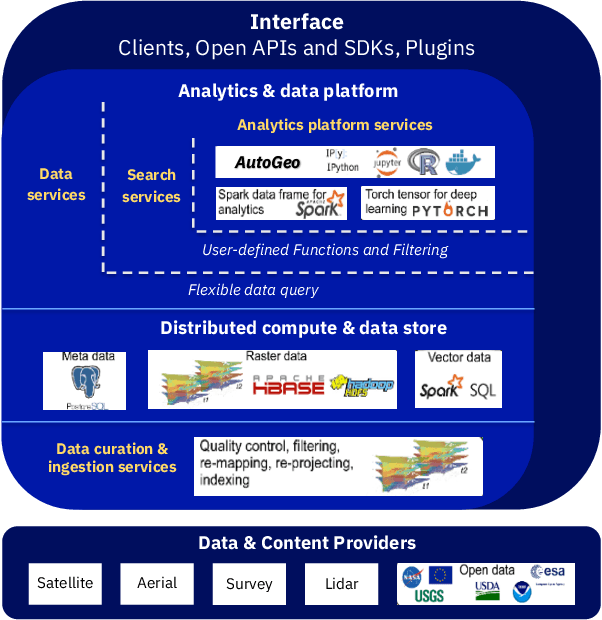

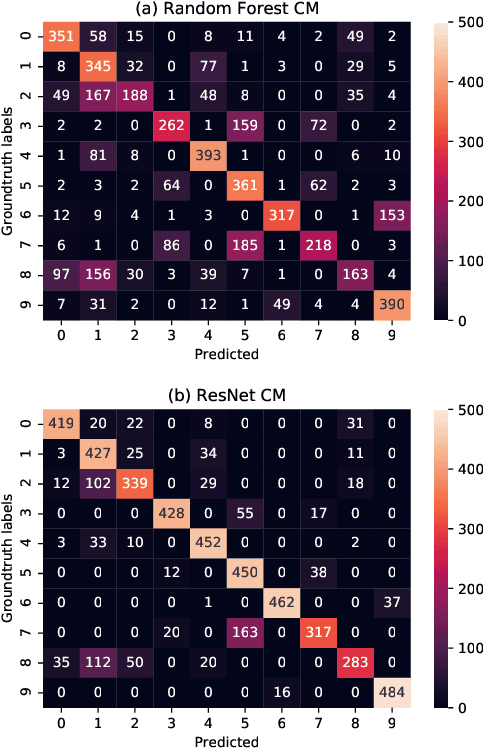
An automated machine learning framework for geospatial data named PAIRS AutoGeo is introduced on IBM PAIRS Geoscope big data and analytics platform. The framework simplifies the development of industrial machine learning solutions leveraging geospatial data to the extent that the user inputs are minimized to merely a text file containing labeled GPS coordinates. PAIRS AutoGeo automatically gathers required data at the location coordinates, assembles the training data, performs quality check, and trains multiple machine learning models for subsequent deployment. The framework is validated using a realistic industrial use case of tree species classification. Open-source tree species data are used as the input to train a random forest classifier and a modified ResNet model for 10-way tree species classification based on aerial imagery, which leads to an accuracy of $59.8\%$ and $81.4\%$, respectively. This use case exemplifies how PAIRS AutoGeo enables users to leverage machine learning without extensive geospatial expertise.
Monitoring the Impact of Wildfires on Tree Species with Deep Learning
Nov 12, 2020
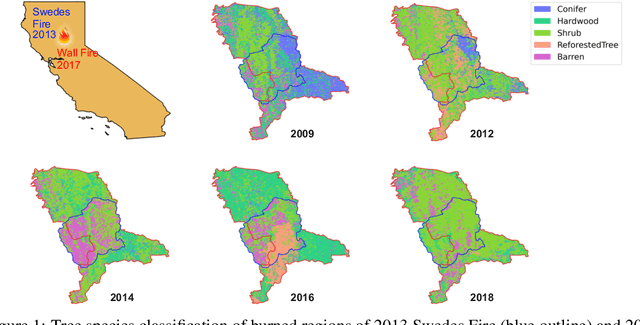

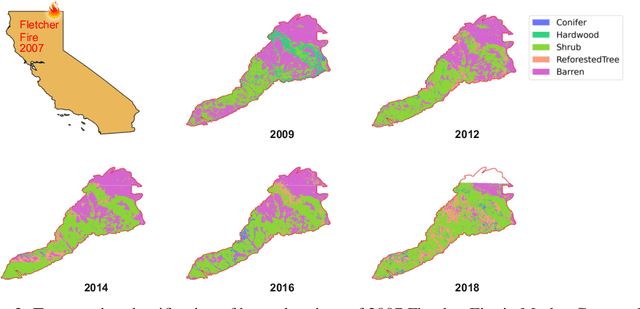
One of the impacts of climate change is the difficulty of tree regrowth after wildfires over areas that traditionally were covered by certain tree species. Here a deep learning model is customized to classify land covers from four-band aerial imagery before and after wildfires to study the prolonged consequences of wildfires on tree species. The tree species labels are generated from manually delineated maps for five land cover classes: Conifer, Hardwood, Shrub, ReforestedTree and Barren land. With an accuracy of $92\%$ on the test split, the model is applied to three wildfires on data from 2009 to 2018. The model accurately delineates areas damaged by wildfires, changes in tree species and rebound of burned areas. The result shows clear evidence of wildfires impacting the local ecosystem and the outlined approach can help monitor reforested areas, observe changes in forest composition and track wildfire impact on tree species.
Physics-Informed Neural Network Super Resolution for Advection-Diffusion Models
Nov 04, 2020
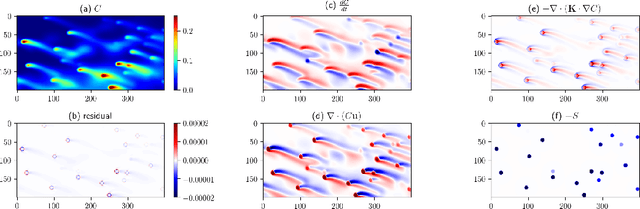
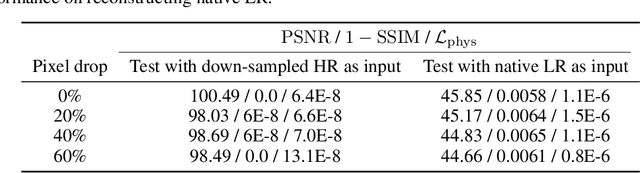
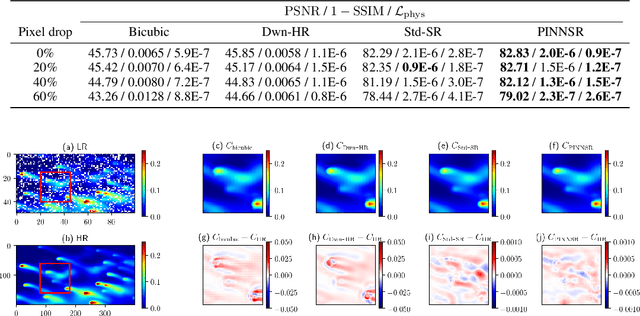
Physics-informed neural networks (NN) are an emerging technique to improve spatial resolution and enforce physical consistency of data from physics models or satellite observations. A super-resolution (SR) technique is explored to reconstruct high-resolution images ($4\times$) from lower resolution images in an advection-diffusion model of atmospheric pollution plumes. SR performance is generally increased when the advection-diffusion equation constrains the NN in addition to conventional pixel-based constraints. The ability of SR techniques to also reconstruct missing data is investigated by randomly removing image pixels from the simulations and allowing the system to learn the content of missing data. Improvements in S/N of $11\%$ are demonstrated when physics equations are included in SR with $40\%$ pixel loss. Physics-informed NNs accurately reconstruct corrupted images and generate better results compared to the standard SR approaches.
Lifelong Object Detection
Sep 02, 2020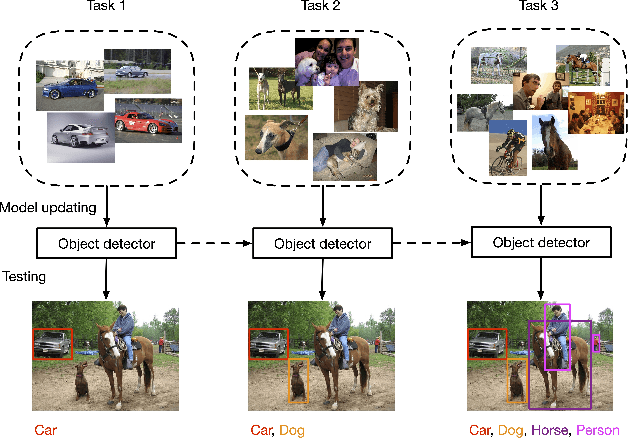
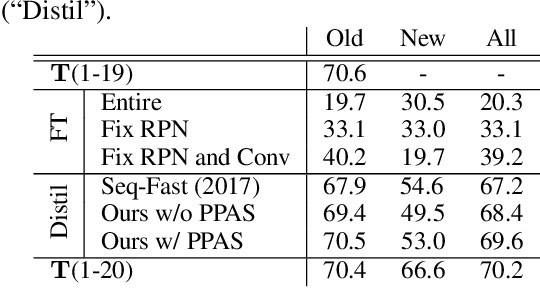
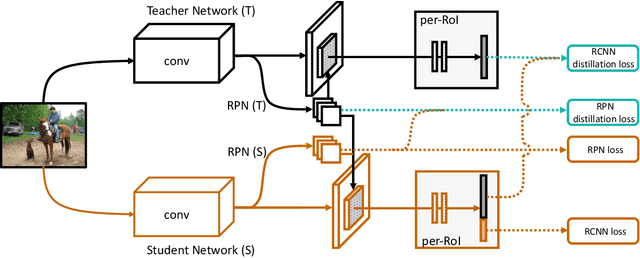

Recent advances in object detection have benefited significantly from rapid developments in deep neural networks. However, neural networks suffer from the well-known issue of catastrophic forgetting, which makes continual or lifelong learning problematic. In this paper, we leverage the fact that new training classes arrive in a sequential manner and incrementally refine the model so that it additionally detects new object classes in the absence of previous training data. Specifically, we consider the representative object detector, Faster R-CNN, for both accurate and efficient prediction. To prevent abrupt performance degradation due to catastrophic forgetting, we propose to apply knowledge distillation on both the region proposal network and the region classification network, to retain the detection of previously trained classes. A pseudo-positive-aware sampling strategy is also introduced for distillation sample selection. We evaluate the proposed method on PASCAL VOC 2007 and MS COCO benchmarks and show competitive mAP and 6x inference speed improvement, which makes the approach more suitable for real-time applications. Our implementation will be publicly available.
Statistical inference in massive datasets by empirical likelihood
Apr 18, 2020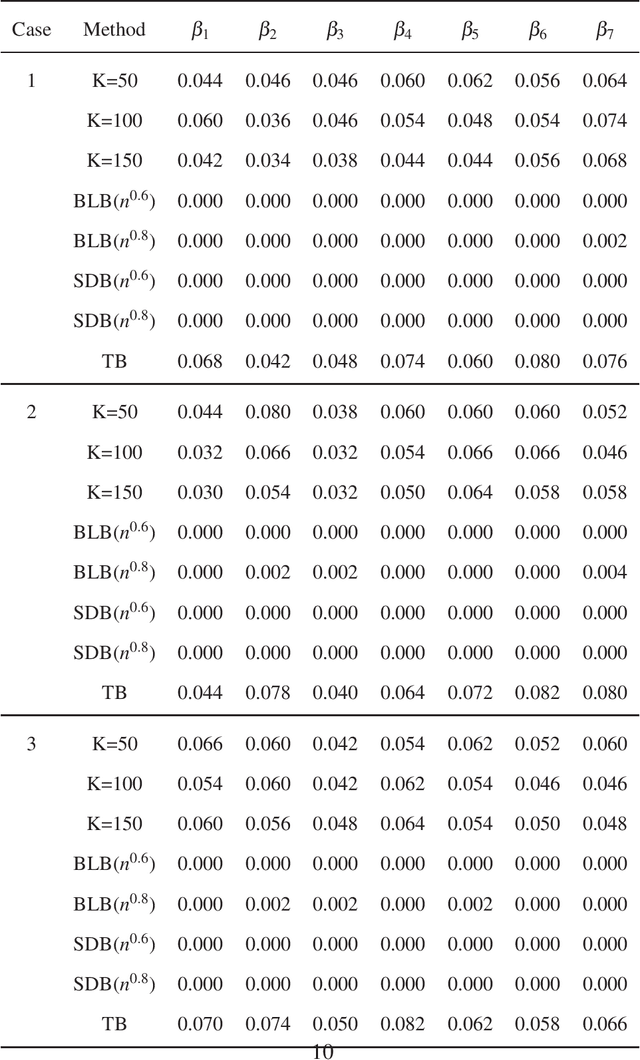
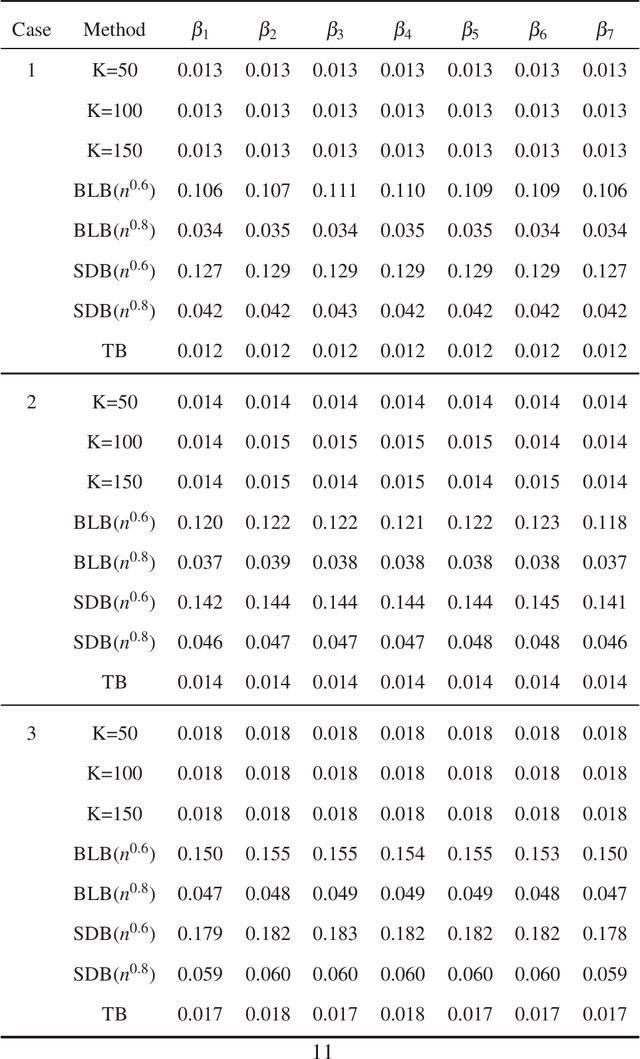
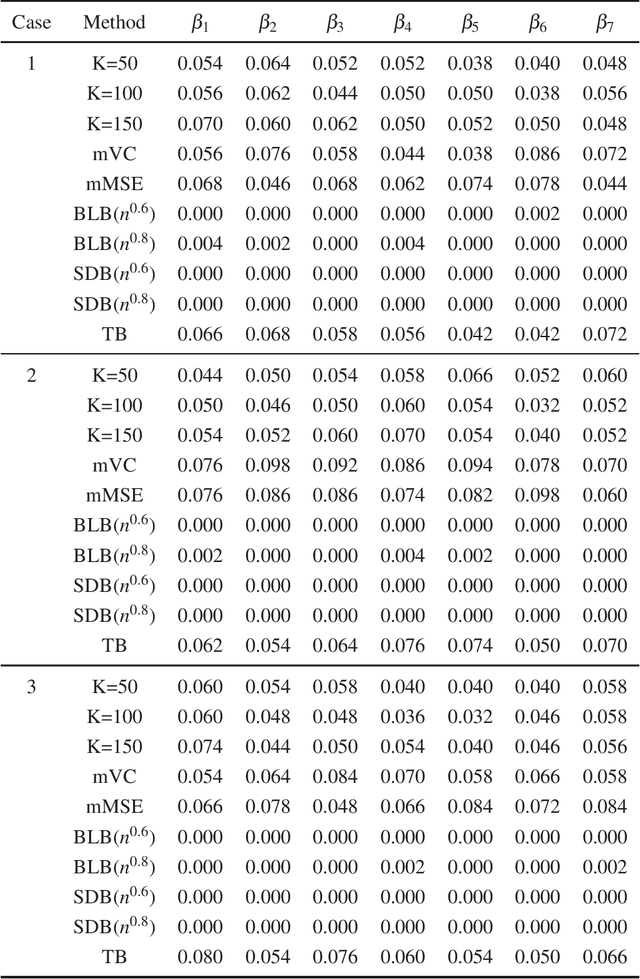
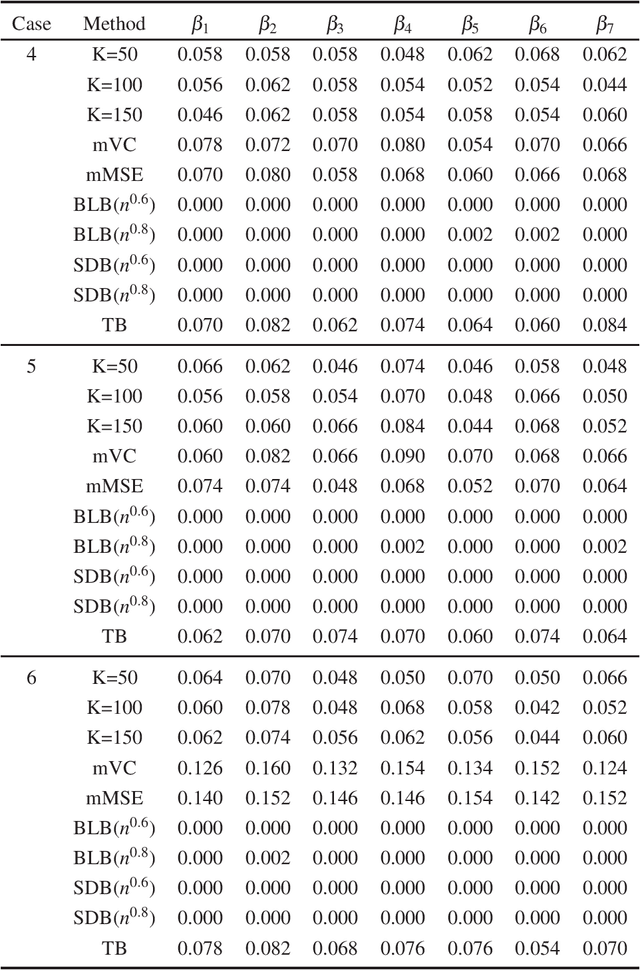
In this paper, we propose a new statistical inference method for massive data sets, which is very simple and efficient by combining divide-and-conquer method and empirical likelihood. Compared with two popular methods (the bag of little bootstrap and the subsampled double bootstrap), we make full use of data sets, and reduce the computation burden. Extensive numerical studies and real data analysis demonstrate the effectiveness and flexibility of our proposed method. Furthermore, the asymptotic property of our method is derived.
Generalizable Resource Allocation in Stream Processing via Deep Reinforcement Learning
Nov 19, 2019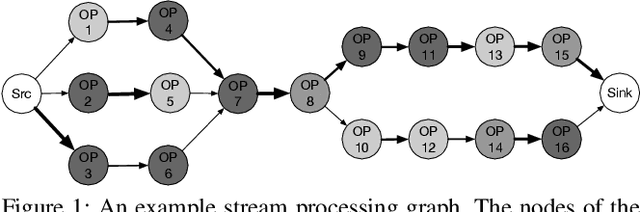



This paper considers the problem of resource allocation in stream processing, where continuous data flows must be processed in real time in a large distributed system. To maximize system throughput, the resource allocation strategy that partitions the computation tasks of a stream processing graph onto computing devices must simultaneously balance workload distribution and minimize communication. Since this problem of graph partitioning is known to be NP-complete yet crucial to practical streaming systems, many heuristic-based algorithms have been developed to find reasonably good solutions. In this paper, we present a graph-aware encoder-decoder framework to learn a generalizable resource allocation strategy that can properly distribute computation tasks of stream processing graphs unobserved from training data. We, for the first time, propose to leverage graph embedding to learn the structural information of the stream processing graphs. Jointly trained with the graph-aware decoder using deep reinforcement learning, our approach can effectively find optimized solutions for unseen graphs. Our experiments show that the proposed model outperforms both METIS, a state-of-the-art graph partitioning algorithm, and an LSTM-based encoder-decoder model, in about 70% of the test cases.