 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMC-Search: Evaluating and Enhancing Multimodal Agentic Search with Structured Long Reasoning Chains
Mar 01, 2026With the increasing demand for step-wise, cross-modal, and knowledge-grounded reasoning, multimodal large language models (MLLMs) are evolving beyond the traditional fixed retrieve-then-generate paradigm toward more sophisticated agentic multimodal retrieval-augmented generation (MM-RAG). Existing benchmarks, however, mainly focus on simplified QA with short retrieval chains, leaving adaptive planning and multimodal reasoning underexplored. We present MC-Search, the first benchmark for agentic MM-RAG with long, step-wise annotated reasoning chains spanning five representative reasoning structures. Each example specifies sub-questions, retrieval modalities, supporting facts, and intermediate answers, with fidelity ensured by HAVE (Hop-wise Attribution and Verification of Evidence), resulting in 3,333 high-quality examples averaging 3.7 hops. Beyond answer accuracy, MC-Search introduces new process-level metrics for reasoning quality, stepwise retrieval and planning accuracy. By developing a unified agentic MM-RAG pipeline, we benchmark six leading MLLMs and reveal systematic issues such as over- and under-retrieval and modality-misaligned planning. Finally, we introduce Search-Align, a process-supervised fine-tuning framework leveraging verified reasoning chains, showing that our data not only enables faithful evaluation but also improves planning and retrieval fidelity in open-source MLLMs.
Mem-Gallery: Benchmarking Multimodal Long-Term Conversational Memory for MLLM Agents
Jan 07, 2026Long-term memory is a critical capability for multimodal large language model (MLLM) agents, particularly in conversational settings where information accumulates and evolves over time. However, existing benchmarks either evaluate multi-session memory in text-only conversations or assess multimodal understanding within localized contexts, failing to evaluate how multimodal memory is preserved, organized, and evolved across long-term conversational trajectories. Thus, we introduce Mem-Gallery, a new benchmark for evaluating multimodal long-term conversational memory in MLLM agents. Mem-Gallery features high-quality multi-session conversations grounded in both visual and textual information, with long interaction horizons and rich multimodal dependencies. Building on this dataset, we propose a systematic evaluation framework that assesses key memory capabilities along three functional dimensions: memory extraction and test-time adaptation, memory reasoning, and memory knowledge management. Extensive benchmarking across thirteen memory systems reveals several key findings, highlighting the necessity of explicit multimodal information retention and memory organization, the persistent limitations in memory reasoning and knowledge management, as well as the efficiency bottleneck of current models.
Breaking Silos: Adaptive Model Fusion Unlocks Better Time Series Forecasting
May 24, 2025Time-series forecasting plays a critical role in many real-world applications. Although increasingly powerful models have been developed and achieved superior results on benchmark datasets, through a fine-grained sample-level inspection, we find that (i) no single model consistently outperforms others across different test samples, but instead (ii) each model excels in specific cases. These findings prompt us to explore how to adaptively leverage the distinct strengths of various forecasting models for different samples. We introduce TimeFuse, a framework for collective time-series forecasting with sample-level adaptive fusion of heterogeneous models. TimeFuse utilizes meta-features to characterize input time series and trains a learnable fusor to predict optimal model fusion weights for any given input. The fusor can leverage samples from diverse datasets for joint training, allowing it to adapt to a wide variety of temporal patterns and thus generalize to new inputs, even from unseen datasets. Extensive experiments demonstrate the effectiveness of TimeFuse in various long-/short-term forecasting tasks, achieving near-universal improvement over the state-of-the-art individual models. Code is available at https://github.com/ZhiningLiu1998/TimeFuse.
CLIMB: Class-imbalanced Learning Benchmark on Tabular Data
May 23, 2025Class-imbalanced learning (CIL) on tabular data is important in many real-world applications where the minority class holds the critical but rare outcomes. In this paper, we present CLIMB, a comprehensive benchmark for class-imbalanced learning on tabular data. CLIMB includes 73 real-world datasets across diverse domains and imbalance levels, along with unified implementations of 29 representative CIL algorithms. Built on a high-quality open-source Python package with unified API designs, detailed documentation, and rigorous code quality controls, CLIMB supports easy implementation and comparison between different CIL algorithms. Through extensive experiments, we provide practical insights on method accuracy and efficiency, highlighting the limitations of naive rebalancing, the effectiveness of ensembles, and the importance of data quality. Our code, documentation, and examples are available at https://github.com/ZhiningLiu1998/imbalanced-ensemble.
ClimateBench-M: A Multi-Modal Climate Data Benchmark with a Simple Generative Method
Apr 10, 2025Climate science studies the structure and dynamics of Earth's climate system and seeks to understand how climate changes over time, where the data is usually stored in the format of time series, recording the climate features, geolocation, time attributes, etc. Recently, much research attention has been paid to the climate benchmarks. In addition to the most common task of weather forecasting, several pioneering benchmark works are proposed for extending the modality, such as domain-specific applications like tropical cyclone intensity prediction and flash flood damage estimation, or climate statement and confidence level in the format of natural language. To further motivate the artificial general intelligence development for climate science, in this paper, we first contribute a multi-modal climate benchmark, i.e., ClimateBench-M, which aligns (1) the time series climate data from ERA5, (2) extreme weather events data from NOAA, and (3) satellite image data from NASA HLS based on a unified spatial-temporal granularity. Second, under each data modality, we also propose a simple but strong generative method that could produce competitive performance in weather forecasting, thunderstorm alerts, and crop segmentation tasks in the proposed ClimateBench-M. The data and code of ClimateBench-M are publicly available at https://github.com/iDEA-iSAIL-Lab-UIUC/ClimateBench-M.
Language in the Flow of Time: Time-Series-Paired Texts Weaved into a Unified Temporal Narrative
Feb 13, 2025While many advances in time series models focus exclusively on numerical data, research on multimodal time series, particularly those involving contextual textual information commonly encountered in real-world scenarios, remains in its infancy. Consequently, effectively integrating the text modality remains challenging. In this work, we highlight an intuitive yet significant observation that has been overlooked by existing works: time-series-paired texts exhibit periodic properties that closely mirror those of the original time series. Building on this insight, we propose a novel framework, Texts as Time Series (TaTS), which considers the time-series-paired texts to be auxiliary variables of the time series. TaTS can be plugged into any existing numerical-only time series models and enable them to handle time series data with paired texts effectively. Through extensive experiments on both multimodal time series forecasting and imputation tasks across benchmark datasets with various existing time series models, we demonstrate that TaTS can enhance predictive performance and achieve outperformance without modifying model architectures.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024



This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
AIM: Attributing, Interpreting, Mitigating Data Unfairness
Jun 18, 2024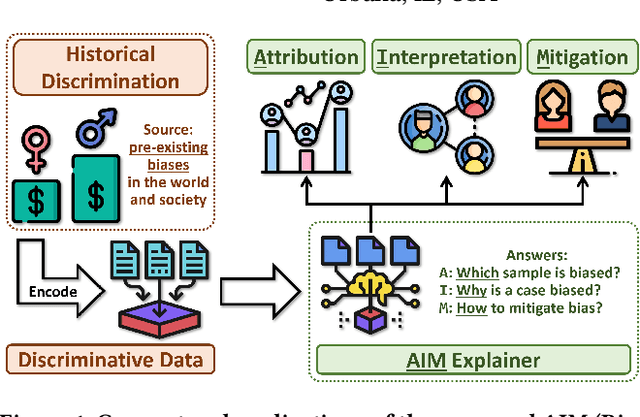
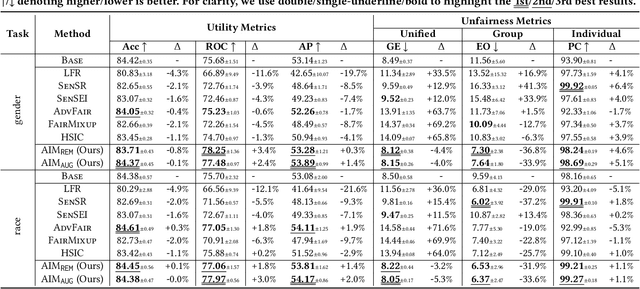
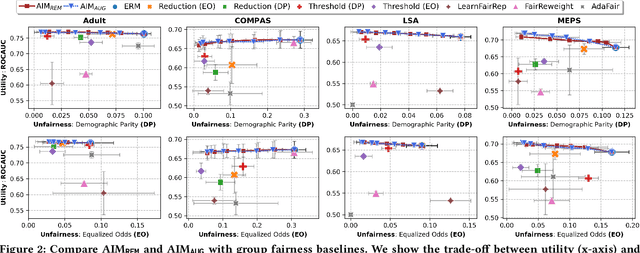
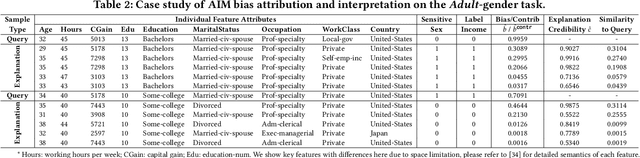
Data collected in the real world often encapsulates historical discrimination against disadvantaged groups and individuals. Existing fair machine learning (FairML) research has predominantly focused on mitigating discriminative bias in the model prediction, with far less effort dedicated towards exploring how to trace biases present in the data, despite its importance for the transparency and interpretability of FairML. To fill this gap, we investigate a novel research problem: discovering samples that reflect biases/prejudices from the training data. Grounding on the existing fairness notions, we lay out a sample bias criterion and propose practical algorithms for measuring and countering sample bias. The derived bias score provides intuitive sample-level attribution and explanation of historical bias in data. On this basis, we further design two FairML strategies via sample-bias-informed minimal data editing. They can mitigate both group and individual unfairness at the cost of minimal or zero predictive utility loss. Extensive experiments and analyses on multiple real-world datasets demonstrate the effectiveness of our methods in explaining and mitigating unfairness. Code is available at https://github.com/ZhiningLiu1998/AIM.
AI Foundation Models for Weather and Climate: Applications, Design, and Implementation
Sep 20, 2023

Machine learning and deep learning methods have been widely explored in understanding the chaotic behavior of the atmosphere and furthering weather forecasting. There has been increasing interest from technology companies, government institutions, and meteorological agencies in building digital twins of the Earth. Recent approaches using transformers, physics-informed machine learning, and graph neural networks have demonstrated state-of-the-art performance on relatively narrow spatiotemporal scales and specific tasks. With the recent success of generative artificial intelligence (AI) using pre-trained transformers for language modeling and vision with prompt engineering and fine-tuning, we are now moving towards generalizable AI. In particular, we are witnessing the rise of AI foundation models that can perform competitively on multiple domain-specific downstream tasks. Despite this progress, we are still in the nascent stages of a generalizable AI model for global Earth system models, regional climate models, and mesoscale weather models. Here, we review current state-of-the-art AI approaches, primarily from transformer and operator learning literature in the context of meteorology. We provide our perspective on criteria for success towards a family of foundation models for nowcasting and forecasting weather and climate predictions. We also discuss how such models can perform competitively on downstream tasks such as downscaling (super-resolution), identifying conditions conducive to the occurrence of wildfires, and predicting consequential meteorological phenomena across various spatiotemporal scales such as hurricanes and atmospheric rivers. In particular, we examine current AI methodologies and contend they have matured enough to design and implement a weather foundation model.
TensorBank:Tensor Lakehouse for Foundation Model Training
Sep 07, 2023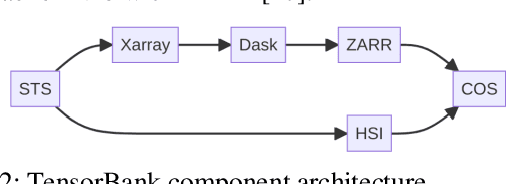
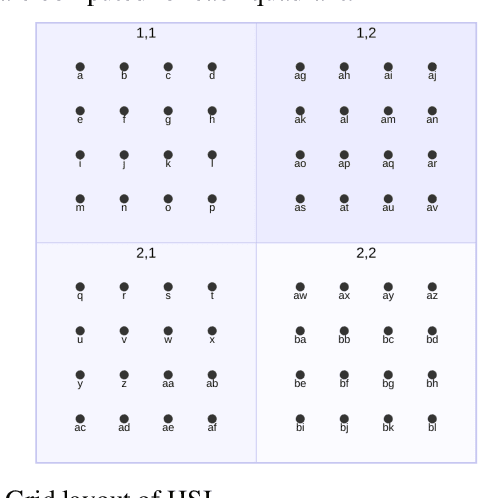
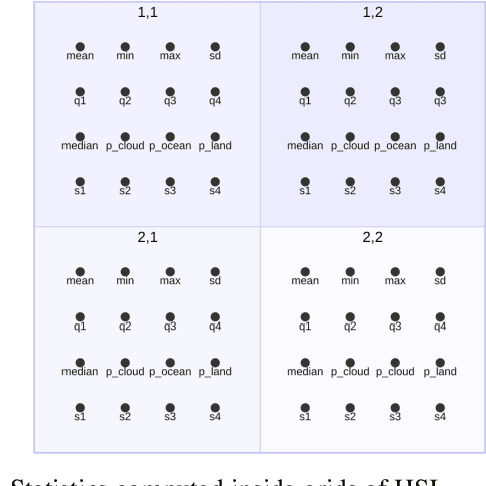
Storing and streaming high dimensional data for foundation model training became a critical requirement with the rise of foundation models beyond natural language. In this paper we introduce TensorBank, a petabyte scale tensor lakehouse capable of streaming tensors from Cloud Object Store (COS) to GPU memory at wire speed based on complex relational queries. We use Hierarchical Statistical Indices (HSI) for query acceleration. Our architecture allows to directly address tensors on block level using HTTP range reads. Once in GPU memory, data can be transformed using PyTorch transforms. We provide a generic PyTorch dataset type with a corresponding dataset factory translating relational queries and requested transformations as an instance. By making use of the HSI, irrelevant blocks can be skipped without reading them as those indices contain statistics on their content at different hierarchical resolution levels. This is an opinionated architecture powered by open standards and making heavy use of open-source technology. Although, hardened for production use using geospatial-temporal data, this architecture generalizes to other use case like computer vision, computational neuroscience, biological sequence analysis and more.