 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerraFlow: Multimodal, Multitemporal Representation Learning for Earth Observation
Mar 13, 2026We propose TerraFlow, a novel approach to multimodal, multitemporal learning for Earth observation. TerraFlow builds on temporal training objectives that enable sequence-aware learning across space, time, and modality, while remaining robust to the variable-length inputs commonly encountered in real-world Earth observation data. Our experiments demonstrate superiority of TerraFlow over state-of-the-art foundation models for Earth observation across all temporal tasks of the GEO-Bench-2 benchmark. We additionally demonstrate that TerraFlow is able to make initial steps towards deep-learning based risk map prediction for natural disasters -- a task on which other state-of-the-art foundation models frequently collapse. TerraFlow outperforms state-of-the-art foundation models by up to 50% in F1 score and 24% in Brier score.
Task-Agnostic Fusion of Time Series and Imagery for Earth Observation
Oct 27, 2025We propose a task-agnostic framework for multimodal fusion of time series and single timestamp images, enabling cross-modal generation and robust downstream performance. Our approach explores deterministic and learned strategies for time series quantization and then leverages a masked correlation learning objective, aligning discrete image and time series tokens in a unified representation space. Instantiated in the Earth observation domain, the pretrained model generates consistent global temperature profiles from satellite imagery and is validated through counterfactual experiments. Across downstream tasks, our task-agnostic pretraining outperforms task-specific fusion by 6\% in R$^2$ and 2\% in RMSE on average, and exceeds baseline methods by 50\% in R$^2$ and 12\% in RMSE. Finally, we analyze gradient sensitivity across modalities, providing insights into model robustness. Code, data, and weights will be released under a permissive license.
TerraCodec: Compressing Earth Observations
Oct 14, 2025



Earth observation (EO) satellites produce massive streams of multispectral image time series, posing pressing challenges for storage and transmission. Yet, learned EO compression remains fragmented, lacking publicly available pretrained models and misaligned with advances in compression for natural imagery. Image codecs overlook temporal redundancy, while video codecs rely on motion priors that fail to capture the radiometric evolution of largely static scenes. We introduce TerraCodec (TEC), a family of learned codecs tailored to EO. TEC includes efficient image-based variants adapted to multispectral inputs, as well as a Temporal Transformer model (TEC-TT) that leverages dependencies across time. To overcome the fixed-rate setting of today's neural codecs, we present Latent Repacking, a novel method for training flexible-rate transformer models that operate on varying rate-distortion settings. Trained on Sentinel-2 data, TerraCodec outperforms classical codecs, achieving 3-10x stronger compression at equivalent image quality. Beyond compression, TEC-TT enables zero-shot cloud inpainting, surpassing state-of-the-art methods on the AllClear benchmark. Our results establish bespoke, learned compression algorithms as a promising direction for Earth observation. Code and model weights will be released under a permissive license.
Fine-tune Smarter, Not Harder: Parameter-Efficient Fine-Tuning for Geospatial Foundation Models
Apr 24, 2025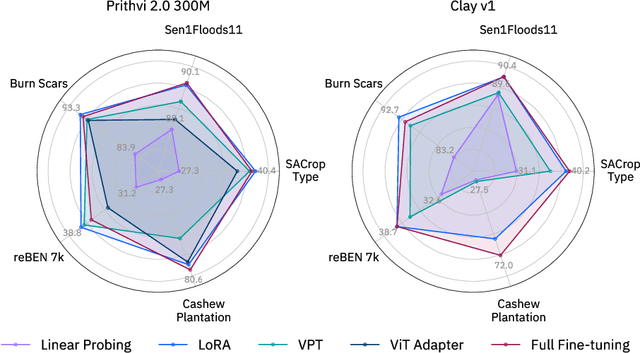

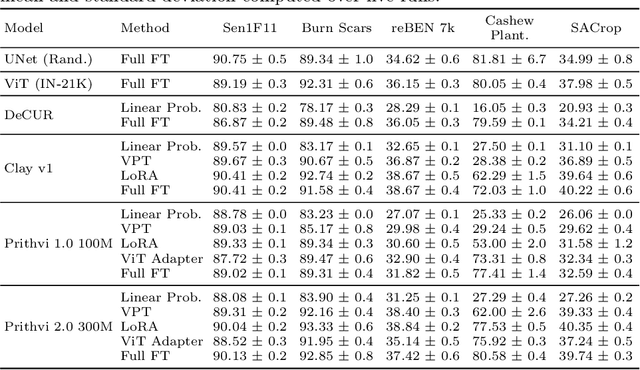
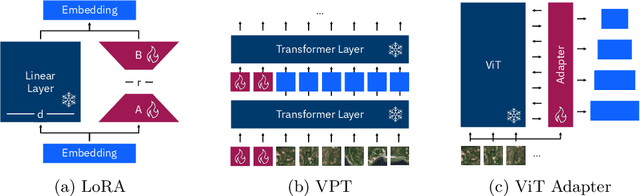
Earth observation (EO) is crucial for monitoring environmental changes, responding to disasters, and managing natural resources. In this context, foundation models facilitate remote sensing image analysis to retrieve relevant geoinformation accurately and efficiently. However, as these models grow in size, fine-tuning becomes increasingly challenging due to the associated computational resources and costs, limiting their accessibility and scalability. Furthermore, full fine-tuning can lead to forgetting pre-trained features and even degrade model generalization. To address this, Parameter-Efficient Fine-Tuning (PEFT) techniques offer a promising solution. In this paper, we conduct extensive experiments with various foundation model architectures and PEFT techniques to evaluate their effectiveness on five different EO datasets. Our results provide a comprehensive comparison, offering insights into when and how PEFT methods support the adaptation of pre-trained geospatial models. We demonstrate that PEFT techniques match or even exceed full fine-tuning performance and enhance model generalisation to unseen geographic regions, while reducing training time and memory requirements. Additional experiments investigate the effect of architecture choices such as the decoder type or the use of metadata, suggesting UNet decoders and fine-tuning without metadata as the recommended configuration. We have integrated all evaluated foundation models and techniques into the open-source package TerraTorch to support quick, scalable, and cost-effective model adaptation.
Hyperspectral Vision Transformers for Greenhouse Gas Estimations from Space
Apr 23, 2025Hyperspectral imaging provides detailed spectral information and holds significant potential for monitoring of greenhouse gases (GHGs). However, its application is constrained by limited spatial coverage and infrequent revisit times. In contrast, multispectral imaging offers broader spatial and temporal coverage but often lacks the spectral detail that can enhance GHG detection. To address these challenges, this study proposes a spectral transformer model that synthesizes hyperspectral data from multispectral inputs. The model is pre-trained via a band-wise masked autoencoder and subsequently fine-tuned on spatio-temporally aligned multispectral-hyperspectral image pairs. The resulting synthetic hyperspectral data retain the spatial and temporal benefits of multispectral imagery and improve GHG prediction accuracy relative to using multispectral data alone. This approach effectively bridges the trade-off between spectral resolution and coverage, highlighting its potential to advance atmospheric monitoring by combining the strengths of hyperspectral and multispectral systems with self-supervised deep learning.
TerraMind: Large-Scale Generative Multimodality for Earth Observation
Apr 15, 2025



We present TerraMind, the first any-to-any generative, multimodal foundation model for Earth observation (EO). Unlike other multimodal models, TerraMind is pretrained on dual-scale representations combining both token-level and pixel-level data across modalities. On a token level, TerraMind encodes high-level contextual information to learn cross-modal relationships, while on a pixel level, TerraMind leverages fine-grained representations to capture critical spatial nuances. We pretrained TerraMind on nine geospatial modalities of a global, large-scale dataset. In this paper, we demonstrate that (i) TerraMind's dual-scale early fusion approach unlocks a range of zero-shot and few-shot applications for Earth observation, (ii) TerraMind introduces "Thinking-in-Modalities" (TiM) -- the capability of generating additional artificial data during finetuning and inference to improve the model output -- and (iii) TerraMind achieves beyond state-of-the-art performance in community-standard benchmarks for EO like PANGAEA. The pretraining dataset, the model weights, and our code is open-sourced under a permissive license.
TerraMesh: A Planetary Mosaic of Multimodal Earth Observation Data
Apr 15, 2025Large-scale foundation models in Earth Observation can learn versatile, label-efficient representations by leveraging massive amounts of unlabeled data. However, existing public datasets are often limited in scale, geographic coverage, or sensor variety. We introduce TerraMesh, a new globally diverse, multimodal dataset combining optical, synthetic aperture radar, elevation, and land-cover modalities in an Analysis-Ready Data format. TerraMesh includes over 9 million samples with eight spatiotemporal aligned modalities, enabling large-scale pre-training and fostering robust cross-modal correlation learning. We provide detailed data processing steps, comprehensive statistics, and empirical evidence demonstrating improved model performance when pre-trained on TerraMesh. The dataset will be made publicly available with a permissive license.
TerraTorch: The Geospatial Foundation Models Toolkit
Mar 26, 2025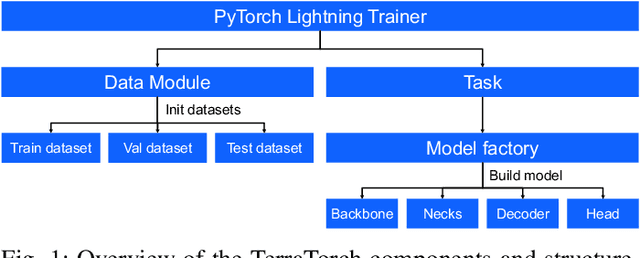
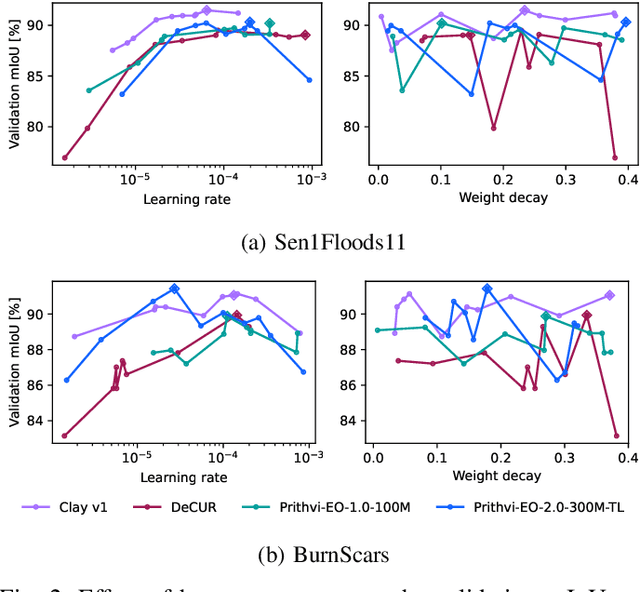
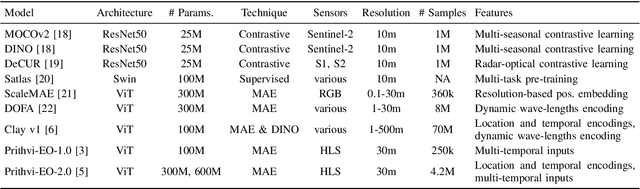

TerraTorch is a fine-tuning and benchmarking toolkit for Geospatial Foundation Models built on PyTorch Lightning and tailored for satellite, weather, and climate data. It integrates domain-specific data modules, pre-defined tasks, and a modular model factory that pairs any backbone with diverse decoder heads. These components allow researchers and practitioners to fine-tune supported models in a no-code fashion by simply editing a training configuration. By consolidating best practices for model development and incorporating the automated hyperparameter optimization extension Iterate, TerraTorch reduces the expertise and time required to fine-tune or benchmark models on new Earth Observation use cases. Furthermore, TerraTorch directly integrates with GEO-Bench, allowing for systematic and reproducible benchmarking of Geospatial Foundation Models. TerraTorch is open sourced under Apache 2.0, available at https://github.com/IBM/terratorch, and can be installed via pip install terratorch.
Beyond the Visible: Multispectral Vision-Language Learning for Earth Observation
Mar 20, 2025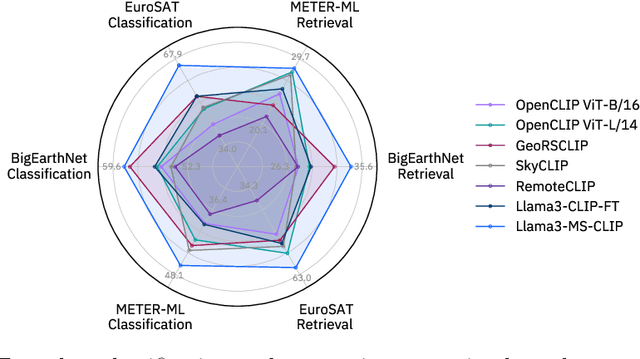
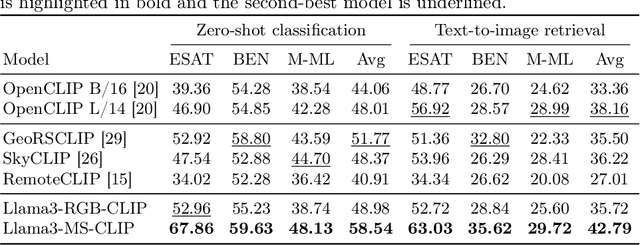
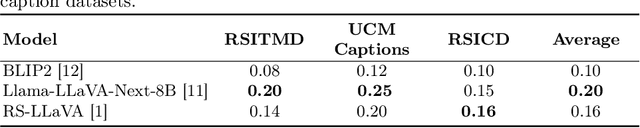

Vision-language models for Earth observation (EO) typically rely on the visual spectrum of data as the only model input, thus failing to leverage the rich spectral information available in the multispectral channels recorded by satellites. Therefore, in this paper, we introduce Llama3-MS-CLIP, the first vision-language model pre-trained with contrastive learning on a large-scale multispectral dataset and report on the performance gains due to the extended spectral range. Furthermore, we present the largest-to-date image-caption dataset for multispectral data, consisting of one million Sentinel-2 samples and corresponding textual descriptions generated with Llama3-LLaVA-Next and Overture Maps data. We develop a scalable captioning pipeline, which is validated by domain experts. We evaluate Llama3-MS-CLIP on multispectral zero-shot image classification and retrieval using three datasets of varying complexity. Our results demonstrate that Llama3-MS-CLIP significantly outperforms other RGB-based approaches, improving classification accuracy by 6.77% on average and retrieval performance by 4.63% mAP compared to the second-best model. Our results emphasize the relevance of multispectral vision-language learning. We release the image-caption dataset, code, and model weights under an open-source license.
Multispectral to Hyperspectral using Pretrained Foundational model
Feb 26, 2025
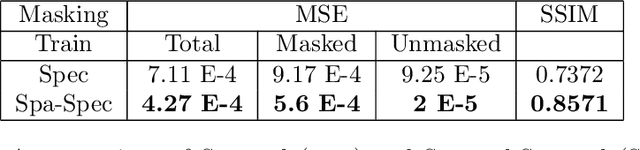
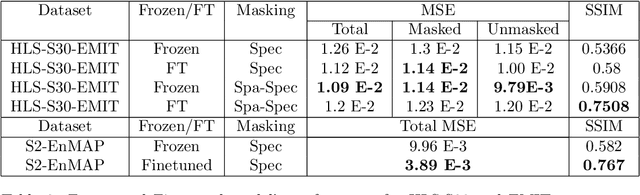
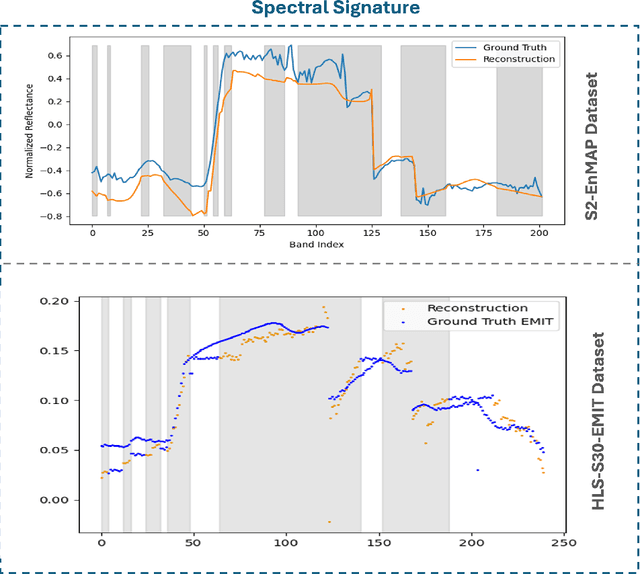
Hyperspectral imaging provides detailed spectral information, offering significant potential for monitoring greenhouse gases like CH4 and NO2. However, its application is constrained by limited spatial coverage and infrequent revisit times. In contrast, multispectral imaging delivers broader spatial and temporal coverage but lacks the spectral granularity required for precise GHG detection. To address these challenges, this study proposes Spectral and Spatial-Spectral transformer models that reconstruct hyperspectral data from multispectral inputs. The models in this paper are pretrained on EnMAP and EMIT datasets and fine-tuned on spatio-temporally aligned (Sentinel-2, EnMAP) and (HLS-S30, EMIT) image pairs respectively. Our model has the potential to enhance atmospheric monitoring by combining the strengths of hyperspectral and multispectral imaging systems.