 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerraTorch: The Geospatial Foundation Models Toolkit
Mar 26, 2025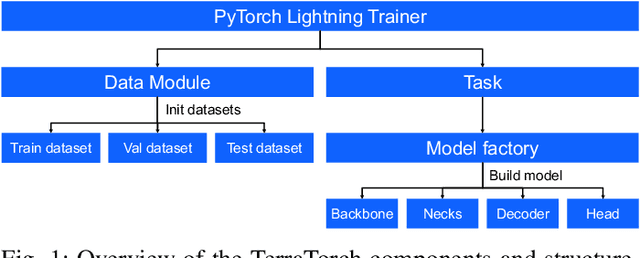

TerraTorch is a fine-tuning and benchmarking toolkit for Geospatial Foundation Models built on PyTorch Lightning and tailored for satellite, weather, and climate data. It integrates domain-specific data modules, pre-defined tasks, and a modular model factory that pairs any backbone with diverse decoder heads. These components allow researchers and practitioners to fine-tune supported models in a no-code fashion by simply editing a training configuration. By consolidating best practices for model development and incorporating the automated hyperparameter optimization extension Iterate, TerraTorch reduces the expertise and time required to fine-tune or benchmark models on new Earth Observation use cases. Furthermore, TerraTorch directly integrates with GEO-Bench, allowing for systematic and reproducible benchmarking of Geospatial Foundation Models. TerraTorch is open sourced under Apache 2.0, available at https://github.com/IBM/terratorch, and can be installed via pip install terratorch.
Prithvi-EO-2.0: A Versatile Multi-Temporal Foundation Model for Earth Observation Applications
Dec 03, 2024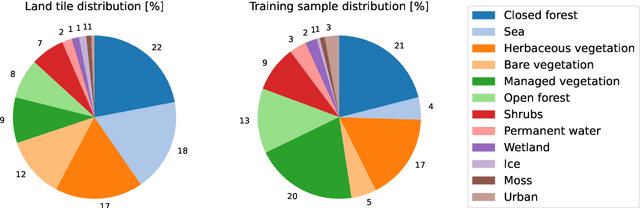
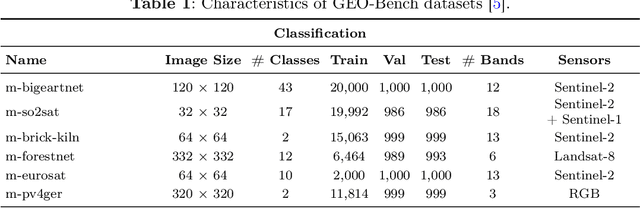
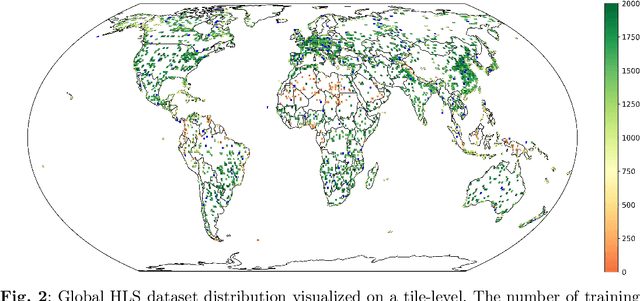
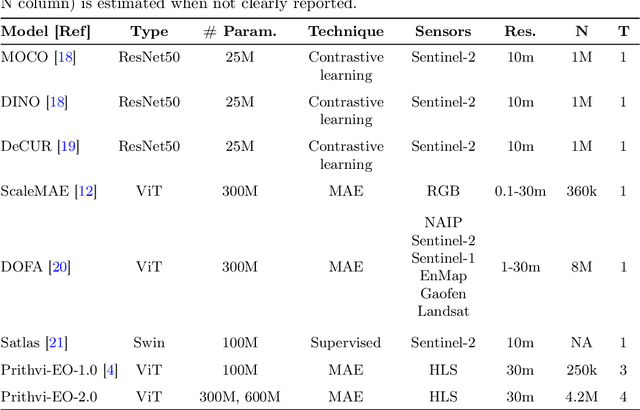
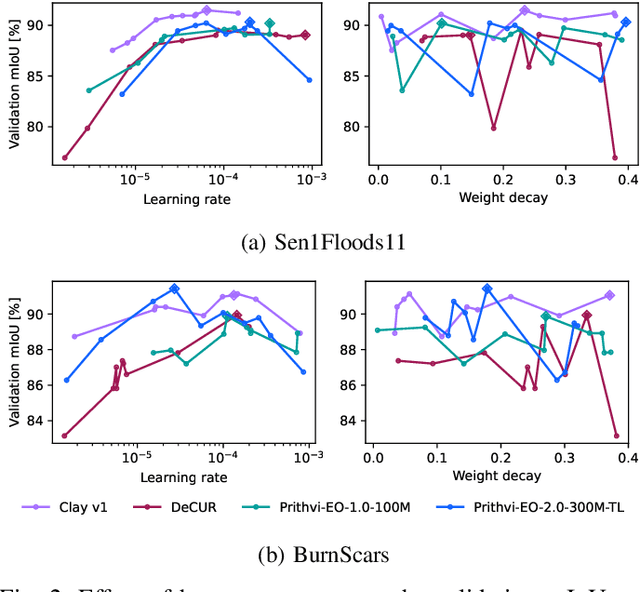
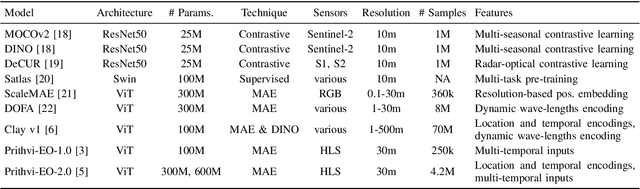
This technical report presents Prithvi-EO-2.0, a new geospatial foundation model that offers significant improvements over its predecessor, Prithvi-EO-1.0. Trained on 4.2M global time series samples from NASA's Harmonized Landsat and Sentinel-2 data archive at 30m resolution, the new 300M and 600M parameter models incorporate temporal and location embeddings for enhanced performance across various geospatial tasks. Through extensive benchmarking with GEO-Bench, the 600M version outperforms the previous Prithvi-EO model by 8\% across a range of tasks. It also outperforms six other geospatial foundation models when benchmarked on remote sensing tasks from different domains and resolutions (i.e. from 0.1m to 15m). The results demonstrate the versatility of the model in both classical earth observation and high-resolution applications. Early involvement of end-users and subject matter experts (SMEs) are among the key factors that contributed to the project's success. In particular, SME involvement allowed for constant feedback on model and dataset design, as well as successful customization for diverse SME-led applications in disaster response, land use and crop mapping, and ecosystem dynamics monitoring. Prithvi-EO-2.0 is available on Hugging Face and IBM terratorch, with additional resources on GitHub. The project exemplifies the Trusted Open Science approach embraced by all involved organizations.
Evaluating the transferability potential of deep learning models for climate downscaling
Jul 17, 2024



Climate downscaling, the process of generating high-resolution climate data from low-resolution simulations, is essential for understanding and adapting to climate change at regional and local scales. Deep learning approaches have proven useful in tackling this problem. However, existing studies usually focus on training models for one specific task, location and variable, which are therefore limited in their generalizability and transferability. In this paper, we evaluate the efficacy of training deep learning downscaling models on multiple diverse climate datasets to learn more robust and transferable representations. We evaluate the effectiveness of architectures zero-shot transferability using CNNs, Fourier Neural Operators (FNOs), and vision Transformers (ViTs). We assess the spatial, variable, and product transferability of downscaling models experimentally, to understand the generalizability of these different architecture types.
Fine-tuning of Geospatial Foundation Models for Aboveground Biomass Estimation
Jun 28, 2024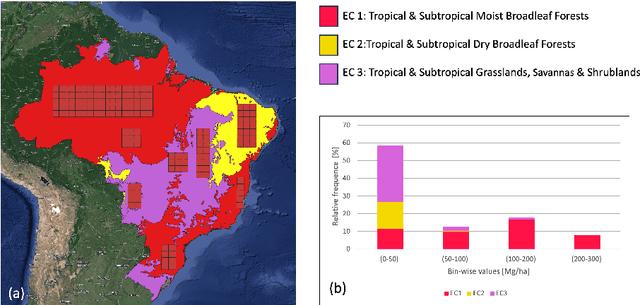

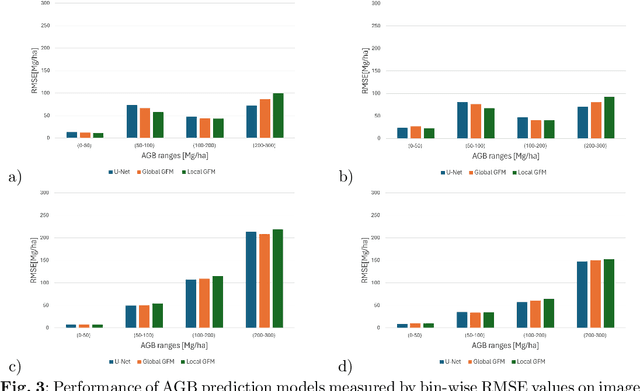
Global vegetation structure mapping is critical for understanding the global carbon cycle and maximizing the efficacy of nature-based carbon sequestration initiatives. Moreover, vegetation structure mapping can help reduce the impacts of climate change by, for example, guiding actions to improve water security, increase biodiversity and reduce flood risk. Global satellite measurements provide an important set of observations for monitoring and managing deforestation and degradation of existing forests, natural forest regeneration, reforestation, biodiversity restoration, and the implementation of sustainable agricultural practices. In this paper, we explore the effectiveness of fine-tuning of a geospatial foundation model to estimate above-ground biomass (AGB) using space-borne data collected across different eco-regions in Brazil. The fine-tuned model architecture consisted of a Swin-B transformer as the encoder (i.e., backbone) and a single convolutional layer for the decoder head. All results were compared to a U-Net which was trained as the baseline model Experimental results of this sparse-label prediction task demonstrate that the fine-tuned geospatial foundation model with a frozen encoder has comparable performance to a U-Net trained from scratch. This is despite the fine-tuned model having 13 times less parameters requiring optimization, which saves both time and compute resources. Further, we explore the transfer-learning capabilities of the geospatial foundation models by fine-tuning on satellite imagery with sparse labels from different eco-regions in Brazil.
A 3D super-resolution of wind fields via physics-informed pixel-wise self-attention generative adversarial network
Dec 20, 2023To mitigate global warming, greenhouse gas sources need to be resolved at a high spatial resolution and monitored in time to ensure the reduction and ultimately elimination of the pollution source. However, the complexity of computation in resolving high-resolution wind fields left the simulations impractical to test different time lengths and model configurations. This study presents a preliminary development of a physics-informed super-resolution (SR) generative adversarial network (GAN) that super-resolves the three-dimensional (3D) low-resolution wind fields by upscaling x9 times. We develop a pixel-wise self-attention (PWA) module that learns 3D weather dynamics via a self-attention computation followed by a 2D convolution. We also employ a loss term that regularizes the self-attention map during pretraining, capturing the vertical convection process from input wind data. The new PWA SR-GAN shows the high-fidelity super-resolved 3D wind data, learns a wind structure at the high-frequency domain, and reduces the computational cost of a high-resolution wind simulation by x89.7 times.
Foundation Models for Generalist Geospatial Artificial Intelligence
Nov 08, 2023Significant progress in the development of highly adaptable and reusable Artificial Intelligence (AI) models is expected to have a significant impact on Earth science and remote sensing. Foundation models are pre-trained on large unlabeled datasets through self-supervision, and then fine-tuned for various downstream tasks with small labeled datasets. This paper introduces a first-of-a-kind framework for the efficient pre-training and fine-tuning of foundational models on extensive geospatial data. We have utilized this framework to create Prithvi, a transformer-based geospatial foundational model pre-trained on more than 1TB of multispectral satellite imagery from the Harmonized Landsat-Sentinel 2 (HLS) dataset. Our study demonstrates the efficacy of our framework in successfully fine-tuning Prithvi to a range of Earth observation tasks that have not been tackled by previous work on foundation models involving multi-temporal cloud gap imputation, flood mapping, wildfire scar segmentation, and multi-temporal crop segmentation. Our experiments show that the pre-trained model accelerates the fine-tuning process compared to leveraging randomly initialized weights. In addition, pre-trained Prithvi compares well against the state-of-the-art, e.g., outperforming a conditional GAN model in multi-temporal cloud imputation by up to 5pp (or 5.7%) in the structural similarity index. Finally, due to the limited availability of labeled data in the field of Earth observation, we gradually reduce the quantity of available labeled data for refining the model to evaluate data efficiency and demonstrate that data can be decreased significantly without affecting the model's accuracy. The pre-trained 100 million parameter model and corresponding fine-tuning workflows have been released publicly as open source contributions to the global Earth sciences community through Hugging Face.
Fourier Neural Operators for Arbitrary Resolution Climate Data Downscaling
May 23, 2023



Climate simulations are essential in guiding our understanding of climate change and responding to its effects. However, it is computationally expensive to resolve complex climate processes at high spatial resolution. As one way to speed up climate simulations, neural networks have been used to downscale climate variables from fast-running low-resolution simulations, but high-resolution training data are often unobtainable or scarce, greatly limiting accuracy. In this work, we propose a downscaling method based on the Fourier neural operator. It trains with data of a small upsampling factor and then can zero-shot downscale its input to arbitrary unseen high resolution. Evaluated both on ERA5 climate model data and on the Navier-Stokes equation solution data, our downscaling model significantly outperforms state-of-the-art convolutional and generative adversarial downscaling models, both in standard single-resolution downscaling and in zero-shot generalization to higher upsampling factors. Furthermore, we show that our method also outperforms state-of-the-art data-driven partial differential equation solvers on Navier-Stokes equations. Overall, our work bridges the gap between simulation of a physical process and interpolation of low-resolution output, showing that it is possible to combine both approaches and significantly improve upon each other.
Generating physically-consistent high-resolution climate data with hard-constrained neural networks
Aug 08, 2022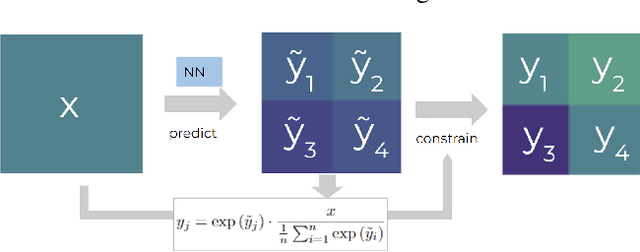

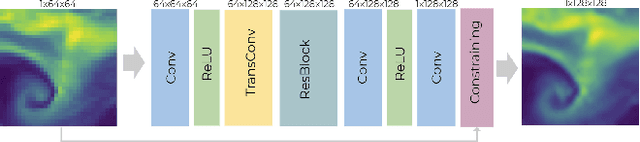
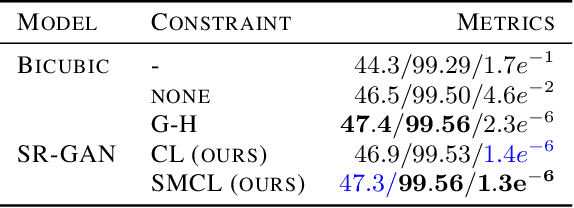
The availability of reliable, high-resolution climate and weather data is important to inform long-term decisions on climate adaptation and mitigation and to guide rapid responses to extreme events. Forecasting models are limited by computational costs and therefore often predict quantities at a coarse spatial resolution. Statistical downscaling can provide an efficient method of upsampling low-resolution data. In this field, deep learning has been applied successfully, often using methods from the super-resolution domain in computer vision. Despite often achieving visually compelling results, such models often violate conservation laws when predicting physical variables. In order to conserve important physical quantities, we develop methods that guarantee physical constraints are satisfied by a deep downscaling model while also increasing their performance according to traditional metrics. We introduce two ways of constraining the network: A renormalization layer added to the end of the neural network and a successive approach that scales with increasing upsampling factors. We show the applicability of our methods across different popular architectures and upsampling factors using ERA5 reanalysis data.
Extreme Precipitation Seasonal Forecast Using a Transformer Neural Network
Jul 14, 2021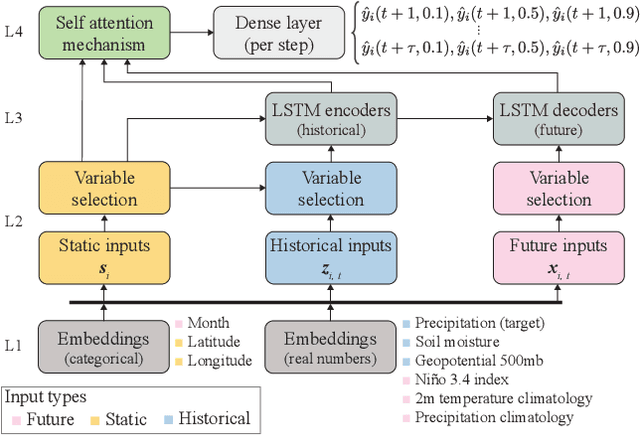
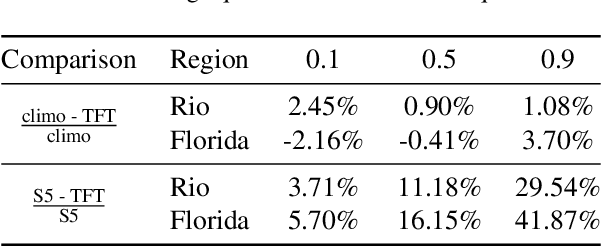
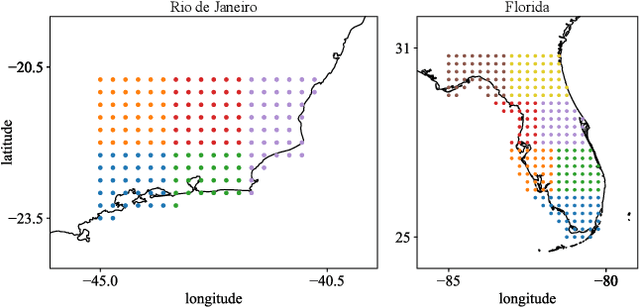
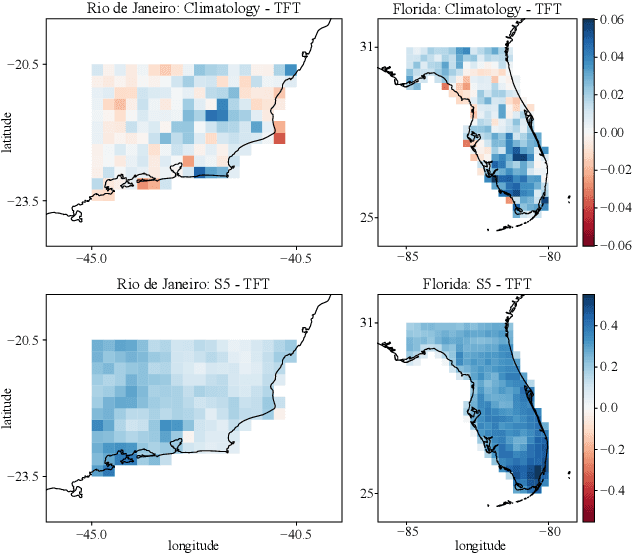
An impact of climate change is the increase in frequency and intensity of extreme precipitation events. However, confidently predicting the likelihood of extreme precipitation at seasonal scales remains an outstanding challenge. Here, we present an approach to forecasting the quantiles of the maximum daily precipitation in each week up to six months ahead using the temporal fusion transformer (TFT) model. Through experiments in two regions, we compare TFT predictions with those of two baselines: climatology and a calibrated ECMWF SEAS5 ensemble forecast (S5). Our results show that, in terms of quantile risk at six month lead time, the TFT predictions significantly outperform those from S5 and show an overall small improvement compared to climatology. The TFT also responds positively to departures from normal that climatology cannot.
A modular framework for extreme weather generation
Feb 05, 2021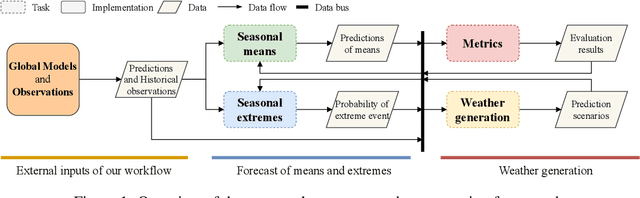
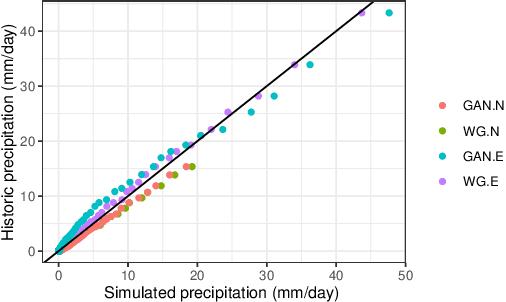
Extreme weather events have an enormous impact on society and are expected to become more frequent and severe with climate change. In this context, resilience planning becomes crucial for risk mitigation and coping with these extreme events. Machine learning techniques can play a critical role in resilience planning through the generation of realistic extreme weather event scenarios that can be used to evaluate possible mitigation actions. This paper proposes a modular framework that relies on interchangeable components to produce extreme weather event scenarios. We discuss possible alternatives for each of the components and show initial results comparing two approaches on the task of generating precipitation scenarios.