 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerraTorch: The Geospatial Foundation Models Toolkit
Mar 26, 2025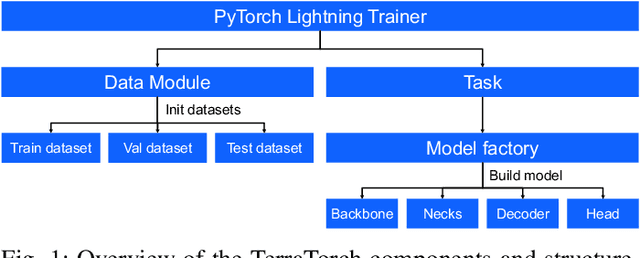
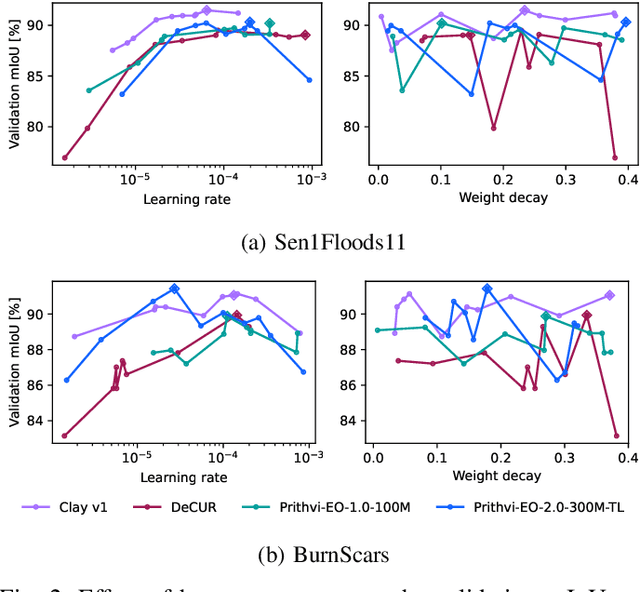
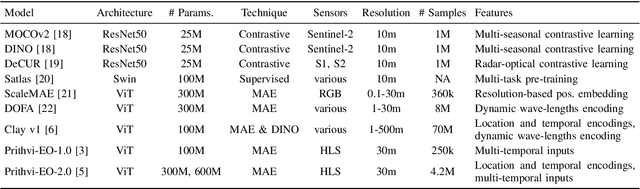

TerraTorch is a fine-tuning and benchmarking toolkit for Geospatial Foundation Models built on PyTorch Lightning and tailored for satellite, weather, and climate data. It integrates domain-specific data modules, pre-defined tasks, and a modular model factory that pairs any backbone with diverse decoder heads. These components allow researchers and practitioners to fine-tune supported models in a no-code fashion by simply editing a training configuration. By consolidating best practices for model development and incorporating the automated hyperparameter optimization extension Iterate, TerraTorch reduces the expertise and time required to fine-tune or benchmark models on new Earth Observation use cases. Furthermore, TerraTorch directly integrates with GEO-Bench, allowing for systematic and reproducible benchmarking of Geospatial Foundation Models. TerraTorch is open sourced under Apache 2.0, available at https://github.com/IBM/terratorch, and can be installed via pip install terratorch.
Lossy Neural Compression for Geospatial Analytics: A Review
Mar 03, 2025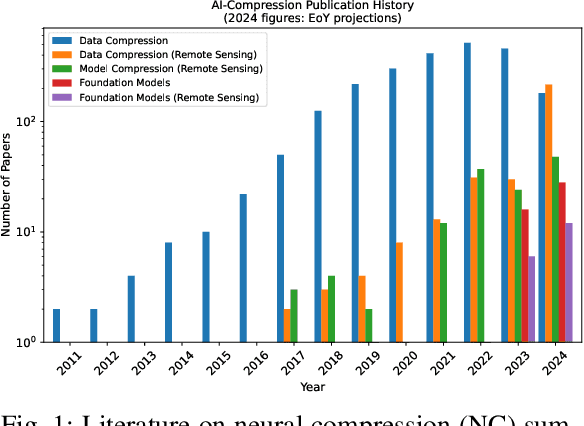
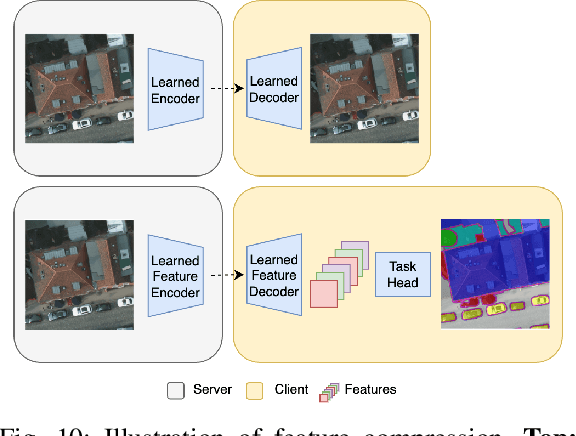
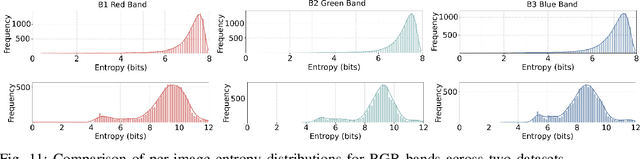
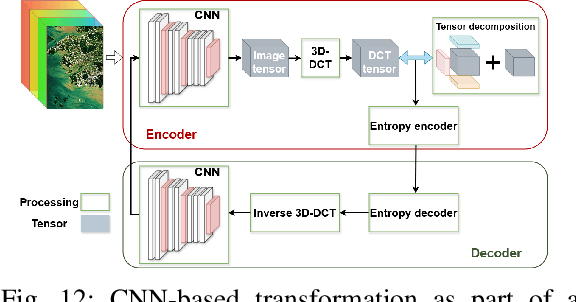
Over the past decades, there has been an explosion in the amount of available Earth Observation (EO) data. The unprecedented coverage of the Earth's surface and atmosphere by satellite imagery has resulted in large volumes of data that must be transmitted to ground stations, stored in data centers, and distributed to end users. Modern Earth System Models (ESMs) face similar challenges, operating at high spatial and temporal resolutions, producing petabytes of data per simulated day. Data compression has gained relevance over the past decade, with neural compression (NC) emerging from deep learning and information theory, making EO data and ESM outputs ideal candidates due to their abundance of unlabeled data. In this review, we outline recent developments in NC applied to geospatial data. We introduce the fundamental concepts of NC including seminal works in its traditional applications to image and video compression domains with focus on lossy compression. We discuss the unique characteristics of EO and ESM data, contrasting them with "natural images", and explain the additional challenges and opportunities they present. Moreover, we review current applications of NC across various EO modalities and explore the limited efforts in ESM compression to date. The advent of self-supervised learning (SSL) and foundation models (FM) has advanced methods to efficiently distill representations from vast unlabeled data. We connect these developments to NC for EO, highlighting the similarities between the two fields and elaborate on the potential of transferring compressed feature representations for machine--to--machine communication. Based on insights drawn from this review, we devise future directions relevant to applications in EO and ESM.
Multi-Spectral Remote Sensing Image Retrieval Using Geospatial Foundation Models
Mar 04, 2024



Image retrieval enables an efficient search through vast amounts of satellite imagery and returns similar images to a query. Deep learning models can identify images across various semantic concepts without the need for annotations. This work proposes to use Geospatial Foundation Models, like Prithvi, for remote sensing image retrieval with multiple benefits: i) the models encode multi-spectral satellite data and ii) generalize without further fine-tuning. We introduce two datasets to the retrieval task and observe a strong performance: Prithvi processes six bands and achieves a mean Average Precision of 97.62\% on BigEarthNet-43 and 44.51\% on ForestNet-12, outperforming other RGB-based models. Further, we evaluate three compression methods with binarized embeddings balancing retrieval speed and accuracy. They match the retrieval speed of much shorter hash codes while maintaining the same accuracy as floating-point embeddings but with a 32-fold compression. The code is available at https://github.com/IBM/remote-sensing-image-retrieval.
TensorBank:Tensor Lakehouse for Foundation Model Training
Sep 07, 2023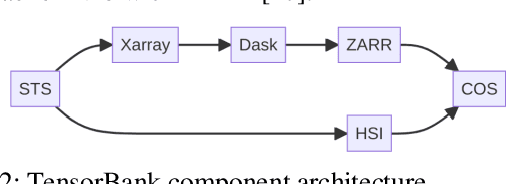
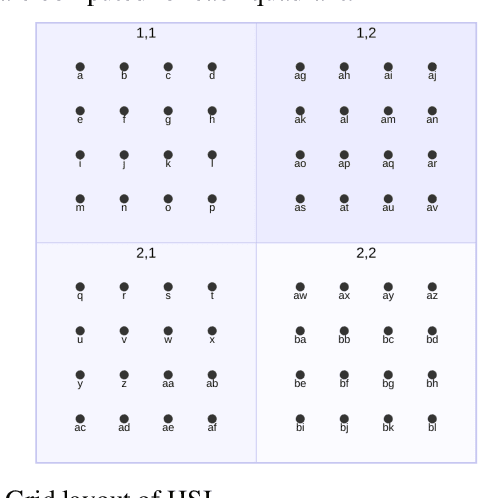
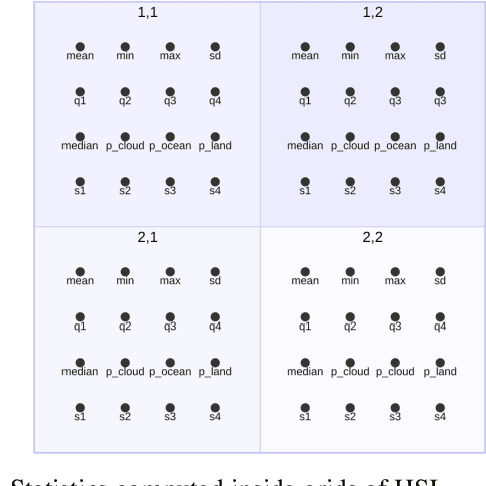
Storing and streaming high dimensional data for foundation model training became a critical requirement with the rise of foundation models beyond natural language. In this paper we introduce TensorBank, a petabyte scale tensor lakehouse capable of streaming tensors from Cloud Object Store (COS) to GPU memory at wire speed based on complex relational queries. We use Hierarchical Statistical Indices (HSI) for query acceleration. Our architecture allows to directly address tensors on block level using HTTP range reads. Once in GPU memory, data can be transformed using PyTorch transforms. We provide a generic PyTorch dataset type with a corresponding dataset factory translating relational queries and requested transformations as an instance. By making use of the HSI, irrelevant blocks can be skipped without reading them as those indices contain statistics on their content at different hierarchical resolution levels. This is an opinionated architecture powered by open standards and making heavy use of open-source technology. Although, hardened for production use using geospatial-temporal data, this architecture generalizes to other use case like computer vision, computational neuroscience, biological sequence analysis and more.
CLAIMED -- the open source framework for building coarse-grained operators for accelerated discovery in science
Jul 12, 2023



In modern data-driven science, reproducibility and reusability are key challenges. Scientists are well skilled in the process from data to publication. Although some publication channels require source code and data to be made accessible, rerunning and verifying experiments is usually hard due to a lack of standards. Therefore, reusing existing scientific data processing code from state-of-the-art research is hard as well. This is why we introduce CLAIMED, which has a proven track record in scientific research for addressing the repeatability and reusability issues in modern data-driven science. CLAIMED is a framework to build reusable operators and scalable scientific workflows by supporting the scientist to draw from previous work by re-composing workflows from existing libraries of coarse-grained scientific operators. Although various implementations exist, CLAIMED is programming language, scientific library, and execution environment agnostic.
CLAIMED, a visual and scalable component library for Trusted AI
Mar 04, 2021
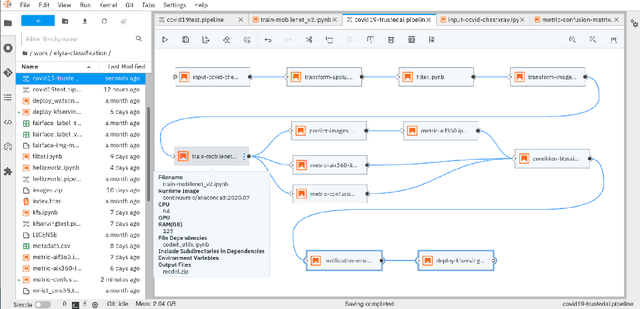
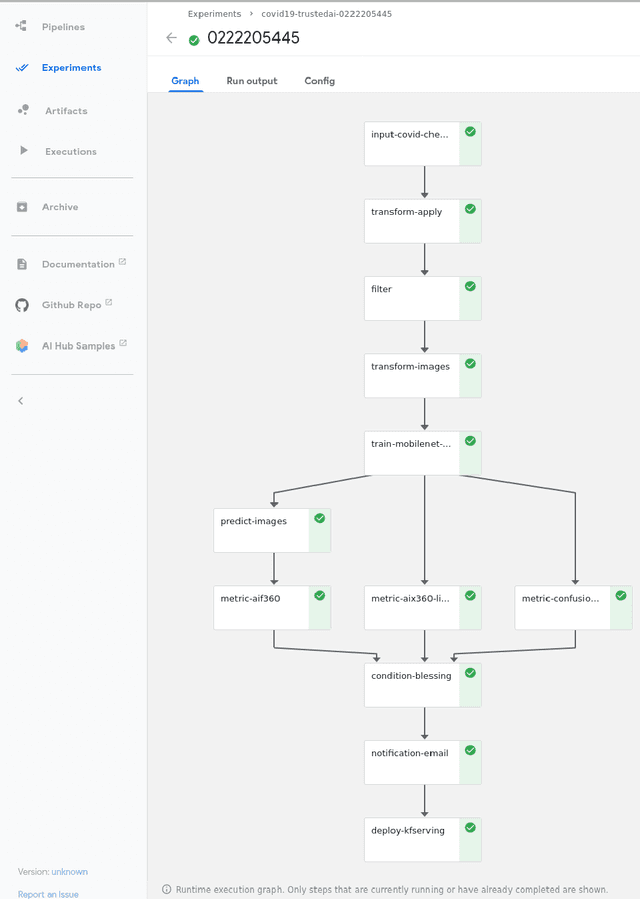
Deep Learning models are getting more and more popular but constraints on explainability, adversarial robustness and fairness are often major concerns for production deployment. Although the open source ecosystem is abundant on addressing those concerns, fully integrated, end to end systems are lacking in open source. Therefore we provide an entirely open source, reusable component framework, visual editor and execution engine for production grade machine learning on top of Kubernetes, a joint effort between IBM and the University Hospital Basel. It uses Kubeflow Pipelines, the AI Explainability360 toolkit, the AI Fairness360 toolkit and the Adversarial Robustness Toolkit on top of ElyraAI, Kubeflow, Kubernetes and JupyterLab. Using the Elyra pipeline editor, AI pipelines can be developed visually with a set of jupyter notebooks.