 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLossy Neural Compression for Geospatial Analytics: A Review
Mar 03, 2025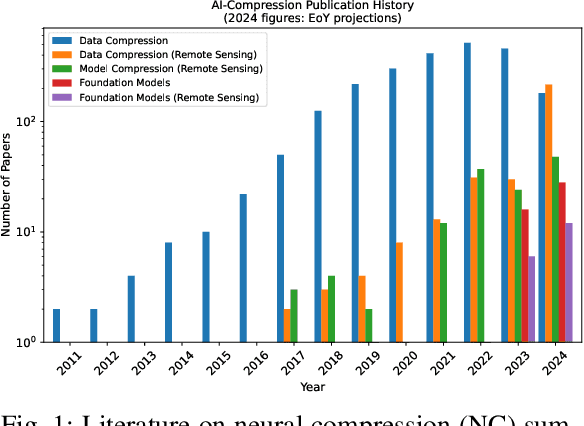
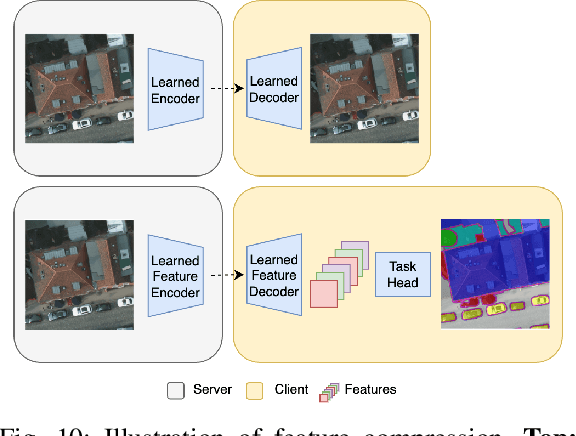
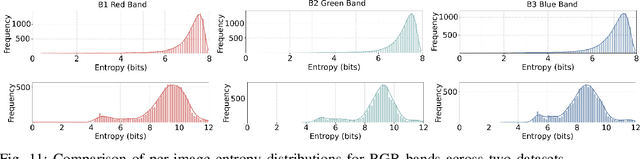
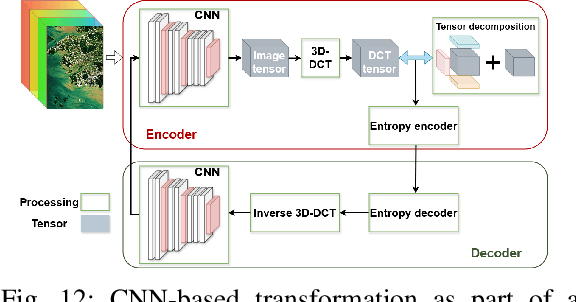
Over the past decades, there has been an explosion in the amount of available Earth Observation (EO) data. The unprecedented coverage of the Earth's surface and atmosphere by satellite imagery has resulted in large volumes of data that must be transmitted to ground stations, stored in data centers, and distributed to end users. Modern Earth System Models (ESMs) face similar challenges, operating at high spatial and temporal resolutions, producing petabytes of data per simulated day. Data compression has gained relevance over the past decade, with neural compression (NC) emerging from deep learning and information theory, making EO data and ESM outputs ideal candidates due to their abundance of unlabeled data. In this review, we outline recent developments in NC applied to geospatial data. We introduce the fundamental concepts of NC including seminal works in its traditional applications to image and video compression domains with focus on lossy compression. We discuss the unique characteristics of EO and ESM data, contrasting them with "natural images", and explain the additional challenges and opportunities they present. Moreover, we review current applications of NC across various EO modalities and explore the limited efforts in ESM compression to date. The advent of self-supervised learning (SSL) and foundation models (FM) has advanced methods to efficiently distill representations from vast unlabeled data. We connect these developments to NC for EO, highlighting the similarities between the two fields and elaborate on the potential of transferring compressed feature representations for machine--to--machine communication. Based on insights drawn from this review, we devise future directions relevant to applications in EO and ESM.
Rethinking Variational Inference for Probabilistic Programs with Stochastic Support
Nov 01, 2023



We introduce Support Decomposition Variational Inference (SDVI), a new variational inference (VI) approach for probabilistic programs with stochastic support. Existing approaches to this problem rely on designing a single global variational guide on a variable-by-variable basis, while maintaining the stochastic control flow of the original program. SDVI instead breaks the program down into sub-programs with static support, before automatically building separate sub-guides for each. This decomposition significantly aids in the construction of suitable variational families, enabling, in turn, substantial improvements in inference performance.
Beyond Bayesian Model Averaging over Paths in Probabilistic Programs with Stochastic Support
Oct 23, 2023The posterior in probabilistic programs with stochastic support decomposes as a weighted sum of the local posterior distributions associated with each possible program path. We show that making predictions with this full posterior implicitly performs a Bayesian model averaging (BMA) over paths. This is potentially problematic, as model misspecification can cause the BMA weights to prematurely collapse onto a single path, leading to sub-optimal predictions in turn. To remedy this issue, we propose alternative mechanisms for path weighting: one based on stacking and one based on ideas from PAC-Bayes. We show how both can be implemented as a cheap post-processing step on top of existing inference engines. In our experiments, we find them to be more robust and lead to better predictions compared to the default BMA weights.
Expectation Programming
Jun 09, 2021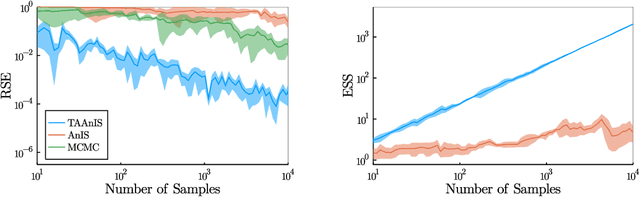
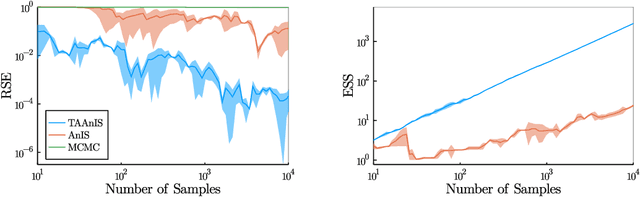
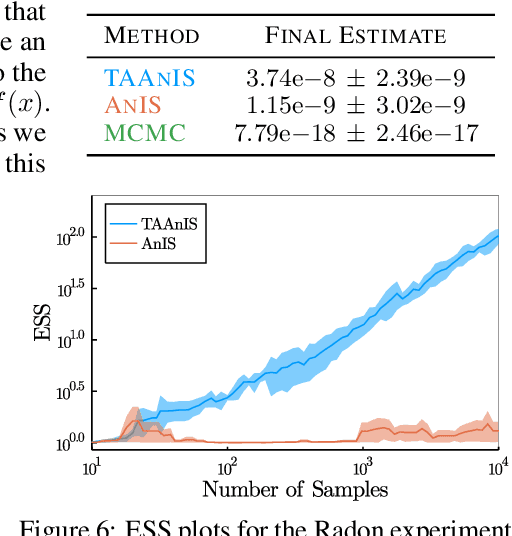

Building on ideas from probabilistic programming, we introduce the concept of an expectation programming framework (EPF) that automates the calculation of expectations. Analogous to a probabilistic program, an expectation program is comprised of a mix of probabilistic constructs and deterministic calculations that define a conditional distribution over its variables. However, the focus of the inference engine in an EPF is to directly estimate the resulting expectation of the program return values, rather than approximate the conditional distribution itself. This distinction allows us to achieve substantial performance improvements over the standard probabilistic programming pipeline by tailoring the inference to the precise expectation we care about. We realize a particular instantiation of our EPF concept by extending the probabilistic programming language Turing to allow so-called target-aware inference to be run automatically, and show that this leads to significant empirical gains compared to conventional posterior-based inference.