 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIMPLER: Efficient Foundation Model Adaptation via Similarity-Guided Layer Pruning for Earth Observation
Mar 20, 2026Fine-tuning foundation models for Earth Observation is computationally expensive, with high training time and memory demands for both training and deployment. Parameter-efficient methods reduce training cost but retain full inference complexity, while post-hoc compression optimizes inference only after costly full fine-tuning. We introduce SIMPLER, a pre-fine-tuning architecture selection method that reduces inference and deployment costs by identifying an effective model depth before adaptation. SIMPLER exploits stabilization of representations in deeper layers of pre-trained vision transformers: it computes layer-wise representation similarity on unlabeled task data and applies an automated scoring function to select redundant layers, with no gradients, magnitude heuristics, or hyperparameter tuning required. On Prithvi-EO-2, SIMPLER prunes up to 79% of parameters while retaining 94% of baseline performance, yielding a 2.1x training speedup and 2.6x inference speedup. The method generalizes to TerraMind (a multimodal EO foundation model) and ImageNet-pretrained ViT-MAE, demonstrating applicability across tasks, architectures, and spectral modalities. Code is available at https://gitlab.citius.gal/hpc4rs/simpler.
TerraFlow: Multimodal, Multitemporal Representation Learning for Earth Observation
Mar 13, 2026We propose TerraFlow, a novel approach to multimodal, multitemporal learning for Earth observation. TerraFlow builds on temporal training objectives that enable sequence-aware learning across space, time, and modality, while remaining robust to the variable-length inputs commonly encountered in real-world Earth observation data. Our experiments demonstrate superiority of TerraFlow over state-of-the-art foundation models for Earth observation across all temporal tasks of the GEO-Bench-2 benchmark. We additionally demonstrate that TerraFlow is able to make initial steps towards deep-learning based risk map prediction for natural disasters -- a task on which other state-of-the-art foundation models frequently collapse. TerraFlow outperforms state-of-the-art foundation models by up to 50% in F1 score and 24% in Brier score.
How To Embed Matters: Evaluation of EO Embedding Design Choices
Mar 11, 2026Earth observation (EO) missions produce petabytes of multispectral imagery, increasingly analyzed using large Geospatial Foundation Models (GeoFMs). Alongside end-to-end adaptation, workflows make growing use of intermediate representations as task-agnostic embeddings, enabling models to compute representations once and reuse them across downstream tasks. Consequently, when GeoFMs act as feature extractors, decisions about how representations are obtained, aggregated, and combined affect downstream performance and pipeline scalability. Understanding these trade-offs is essential for scalable embedding-based EO workflows, where compact embeddings can replace raw data while remaining broadly useful. We present a systematic analysis of embedding design in GeoFM-based EO workflows. Leveraging NeuCo-Bench, we study how backbone architecture, pretraining strategy, representation depth, spatial aggregation, and representation combination influence EO task performance. We demonstrate the usability of GeoFM embeddings by aggregating them into fixed-size representations more than 500x smaller than the raw input data. Across models, we find consistent trends: transformer backbones with mean pooling provide strong default embeddings, intermediate ResNet layers can outperform final layers, self-supervised objectives exhibit task-specific strengths, and combining embeddings from different objectives often improves robustness.
Partial recovery of meter-scale surface weather
Feb 26, 2026Near-surface atmospheric conditions can differ sharply over tens to hundreds of meters due to land cover and topography, yet this variability is absent from current weather analyses and forecasts. It is unclear whether such meter-scale variability reflects irreducibly chaotic dynamics or contains a component predictable from surface characteristics and large-scale atmospheric forcing. Here we show that a substantial, physically coherent component of meter-scale near-surface weather is statistically recoverable from existing observations. By conditioning coarse atmospheric state on sparse surface station measurements and high-resolution Earth observation data, we infer spatially continuous fields of near-surface wind, temperature, and humidity at 10 m resolution across the contiguous United States. Relative to ERA5, the inferred fields reduce wind error by 29% and temperature and dewpoint error by 6%, while explaining substantially more spatial variance at fixed time steps. They also exhibit physically interpretable structure, including urban heat islands, evapotranspiration-driven humidity contrasts, and wind speed differences across land cover types. Our findings expand the frontier of weather modeling by demonstrating a computationally feasible approach to continental-scale meter-resolution inference. More broadly, they illustrate how conditioning coarse dynamical models on static fine-scale features can reveal previously unresolved components of the Earth system.
Phaedra: Learning High-Fidelity Discrete Tokenization for the Physical Science
Feb 03, 2026Tokens are discrete representations that allow modern deep learning to scale by transforming high-dimensional data into sequences that can be efficiently learned, generated, and generalized to new tasks. These have become foundational for image and video generation and, more recently, physical simulation. As existing tokenizers are designed for the explicit requirements of realistic visual perception of images, it is necessary to ask whether these approaches are optimal for scientific images, which exhibit a large dynamic range and require token embeddings to retain physical and spectral properties. In this work, we investigate the accuracy of a suite of image tokenizers across a range of metrics designed to measure the fidelity of PDE properties in both physical and spectral space. Based on the observation that these struggle to capture both fine details and precise magnitudes, we propose Phaedra, inspired by classical shape-gain quantization and proper orthogonal decomposition. We demonstrate that Phaedra consistently improves reconstruction across a range of PDE datasets. Additionally, our results show strong out-of-distribution generalization capabilities to three tasks of increasing complexity, namely known PDEs with different conditions, unknown PDEs, and real-world Earth observation and weather data.
Task-Agnostic Fusion of Time Series and Imagery for Earth Observation
Oct 27, 2025We propose a task-agnostic framework for multimodal fusion of time series and single timestamp images, enabling cross-modal generation and robust downstream performance. Our approach explores deterministic and learned strategies for time series quantization and then leverages a masked correlation learning objective, aligning discrete image and time series tokens in a unified representation space. Instantiated in the Earth observation domain, the pretrained model generates consistent global temperature profiles from satellite imagery and is validated through counterfactual experiments. Across downstream tasks, our task-agnostic pretraining outperforms task-specific fusion by 6\% in R$^2$ and 2\% in RMSE on average, and exceeds baseline methods by 50\% in R$^2$ and 12\% in RMSE. Finally, we analyze gradient sensitivity across modalities, providing insights into model robustness. Code, data, and weights will be released under a permissive license.
Hyperspectral Vision Transformers for Greenhouse Gas Estimations from Space
Apr 23, 2025Hyperspectral imaging provides detailed spectral information and holds significant potential for monitoring of greenhouse gases (GHGs). However, its application is constrained by limited spatial coverage and infrequent revisit times. In contrast, multispectral imaging offers broader spatial and temporal coverage but often lacks the spectral detail that can enhance GHG detection. To address these challenges, this study proposes a spectral transformer model that synthesizes hyperspectral data from multispectral inputs. The model is pre-trained via a band-wise masked autoencoder and subsequently fine-tuned on spatio-temporally aligned multispectral-hyperspectral image pairs. The resulting synthetic hyperspectral data retain the spatial and temporal benefits of multispectral imagery and improve GHG prediction accuracy relative to using multispectral data alone. This approach effectively bridges the trade-off between spectral resolution and coverage, highlighting its potential to advance atmospheric monitoring by combining the strengths of hyperspectral and multispectral systems with self-supervised deep learning.
TerraMesh: A Planetary Mosaic of Multimodal Earth Observation Data
Apr 15, 2025Large-scale foundation models in Earth Observation can learn versatile, label-efficient representations by leveraging massive amounts of unlabeled data. However, existing public datasets are often limited in scale, geographic coverage, or sensor variety. We introduce TerraMesh, a new globally diverse, multimodal dataset combining optical, synthetic aperture radar, elevation, and land-cover modalities in an Analysis-Ready Data format. TerraMesh includes over 9 million samples with eight spatiotemporal aligned modalities, enabling large-scale pre-training and fostering robust cross-modal correlation learning. We provide detailed data processing steps, comprehensive statistics, and empirical evidence demonstrating improved model performance when pre-trained on TerraMesh. The dataset will be made publicly available with a permissive license.
TerraMind: Large-Scale Generative Multimodality for Earth Observation
Apr 15, 2025



We present TerraMind, the first any-to-any generative, multimodal foundation model for Earth observation (EO). Unlike other multimodal models, TerraMind is pretrained on dual-scale representations combining both token-level and pixel-level data across modalities. On a token level, TerraMind encodes high-level contextual information to learn cross-modal relationships, while on a pixel level, TerraMind leverages fine-grained representations to capture critical spatial nuances. We pretrained TerraMind on nine geospatial modalities of a global, large-scale dataset. In this paper, we demonstrate that (i) TerraMind's dual-scale early fusion approach unlocks a range of zero-shot and few-shot applications for Earth observation, (ii) TerraMind introduces "Thinking-in-Modalities" (TiM) -- the capability of generating additional artificial data during finetuning and inference to improve the model output -- and (iii) TerraMind achieves beyond state-of-the-art performance in community-standard benchmarks for EO like PANGAEA. The pretraining dataset, the model weights, and our code is open-sourced under a permissive license.
Beyond the Visible: Multispectral Vision-Language Learning for Earth Observation
Mar 20, 2025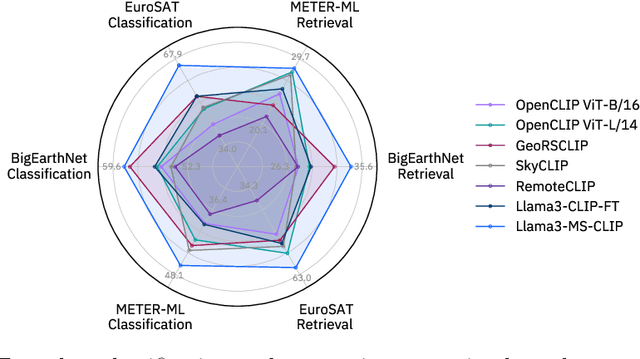
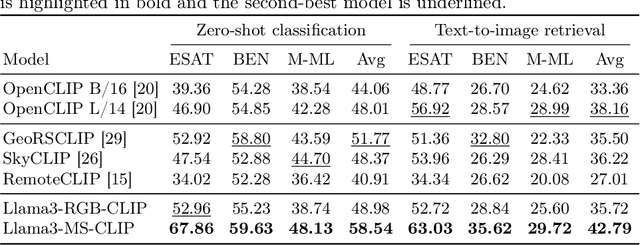
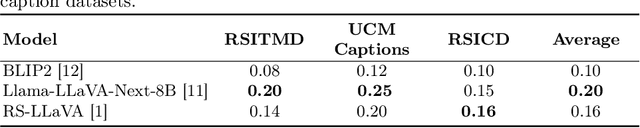

Vision-language models for Earth observation (EO) typically rely on the visual spectrum of data as the only model input, thus failing to leverage the rich spectral information available in the multispectral channels recorded by satellites. Therefore, in this paper, we introduce Llama3-MS-CLIP, the first vision-language model pre-trained with contrastive learning on a large-scale multispectral dataset and report on the performance gains due to the extended spectral range. Furthermore, we present the largest-to-date image-caption dataset for multispectral data, consisting of one million Sentinel-2 samples and corresponding textual descriptions generated with Llama3-LLaVA-Next and Overture Maps data. We develop a scalable captioning pipeline, which is validated by domain experts. We evaluate Llama3-MS-CLIP on multispectral zero-shot image classification and retrieval using three datasets of varying complexity. Our results demonstrate that Llama3-MS-CLIP significantly outperforms other RGB-based approaches, improving classification accuracy by 6.77% on average and retrieval performance by 4.63% mAP compared to the second-best model. Our results emphasize the relevance of multispectral vision-language learning. We release the image-caption dataset, code, and model weights under an open-source license.