 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Model Uncertainty to Human Attention: Localization-Aware Visual Cues for Scalable Annotation Review
May 12, 2026High-quality labeled data is essential for training robust machine learning models, yet obtaining annotations at scale remains expensive. AI-assisted annotation has therefore become standard in large-scale labeling workflows. However, in tasks where model predictions carry two independent components, a class label and spatial boundaries, a model may classify an object with high confidence while mislocalizing it. Existing AI-assisted workflows offer annotators no signal about where spatial errors are most likely. Without such guidance, humans may systematically underinspect subtly misplaced boxes. We address this by studying the effect of visualizing spatial uncertainty via a purpose-built interface. In a controlled study with 120 participants, those receiving uncertainty cues achieve higher label quality while being faster overall. A box-level analysis confirms that the cues redirect annotator effort toward high-uncertainty predictions and away from well-localized boxes. These findings establish localization uncertainty as a lever to improve human-in-the-loop annotation. Code is available at https://mos-ks.github.io/MUHA/.
Data Quality Challenges in Retrieval-Augmented Generation
Oct 01, 2025Organizations increasingly adopt Retrieval-Augmented Generation (RAG) to enhance Large Language Models with enterprise-specific knowledge. However, current data quality (DQ) frameworks have been primarily developed for static datasets, and only inadequately address the dynamic, multi-stage nature of RAG systems. This study aims to develop DQ dimensions for this new type of AI-based systems. We conduct 16 semi-structured interviews with practitioners of leading IT service companies. Through a qualitative content analysis, we inductively derive 15 distinct DQ dimensions across the four processing stages of RAG systems: data extraction, data transformation, prompt & search, and generation. Our findings reveal that (1) new dimensions have to be added to traditional DQ frameworks to also cover RAG contexts; (2) these new dimensions are concentrated in early RAG steps, suggesting the need for front-loaded quality management strategies, and (3) DQ issues transform and propagate through the RAG pipeline, necessitating a dynamic, step-aware approach to quality management.
Honey, I Shrunk the Language Model: Impact of Knowledge Distillation Methods on Performance and Explainability
Apr 22, 2025Artificial Intelligence (AI) has increasingly influenced modern society, recently in particular through significant advancements in Large Language Models (LLMs). However, high computational and storage demands of LLMs still limit their deployment in resource-constrained environments. Knowledge distillation addresses this challenge by training a small student model from a larger teacher model. Previous research has introduced several distillation methods for both generating training data and for training the student model. Despite their relevance, the effects of state-of-the-art distillation methods on model performance and explainability have not been thoroughly investigated and compared. In this work, we enlarge the set of available methods by applying critique-revision prompting to distillation for data generation and by synthesizing existing methods for training. For these methods, we provide a systematic comparison based on the widely used Commonsense Question-Answering (CQA) dataset. While we measure performance via student model accuracy, we employ a human-grounded study to evaluate explainability. We contribute new distillation methods and their comparison in terms of both performance and explainability. This should further advance the distillation of small language models and, thus, contribute to broader applicability and faster diffusion of LLM technology.
Towards Human-Understandable Multi-Dimensional Concept Discovery
Mar 24, 2025Concept-based eXplainable AI (C-XAI) aims to overcome the limitations of traditional saliency maps by converting pixels into human-understandable concepts that are consistent across an entire dataset. A crucial aspect of C-XAI is completeness, which measures how well a set of concepts explains a model's decisions. Among C-XAI methods, Multi-Dimensional Concept Discovery (MCD) effectively improves completeness by breaking down the CNN latent space into distinct and interpretable concept subspaces. However, MCD's explanations can be difficult for humans to understand, raising concerns about their practical utility. To address this, we propose Human-Understandable Multi-dimensional Concept Discovery (HU-MCD). HU-MCD uses the Segment Anything Model for concept identification and implements a CNN-specific input masking technique to reduce noise introduced by traditional masking methods. These changes to MCD, paired with the completeness relation, enable HU-MCD to enhance concept understandability while maintaining explanation faithfulness. Our experiments, including human subject studies, show that HU-MCD provides more precise and reliable explanations than existing C-XAI methods. The code is available at https://github.com/grobruegge/hu-mcd.
Explainability in AI Based Applications: A Framework for Comparing Different Techniques
Oct 28, 2024The integration of artificial intelligence into business processes has significantly enhanced decision-making capabilities across various industries such as finance, healthcare, and retail. However, explaining the decisions made by these AI systems poses a significant challenge due to the opaque nature of recent deep learning models, which typically function as black boxes. To address this opacity, a multitude of explainability techniques have emerged. However, in practical business applications, the challenge lies in selecting an appropriate explainability method that balances comprehensibility with accuracy. This paper addresses the practical need of understanding differences in the output of explainability techniques by proposing a novel method for the assessment of the agreement of different explainability techniques. Based on our proposed methods, we provide a comprehensive comparative analysis of six leading explainability techniques to help guiding the selection of such techniques in practice. Our proposed general-purpose method is evaluated on top of one of the most popular deep learning architectures, the Vision Transformer model, which is frequently employed in business applications. Notably, we propose a novel metric to measure the agreement of explainability techniques that can be interpreted visually. By providing a practical framework for understanding the agreement of diverse explainability techniques, our research aims to facilitate the broader integration of interpretable AI systems in business applications.
Transferring Domain Knowledge with (X)AI-Based Learning Systems
Jun 03, 2024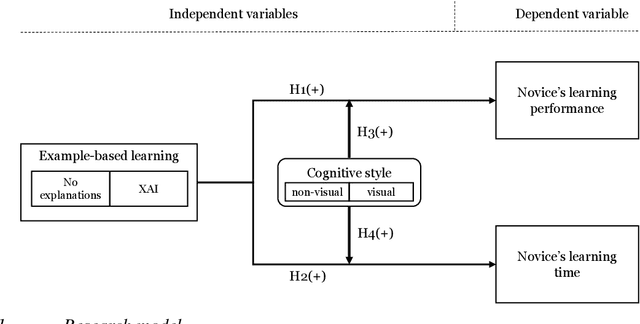
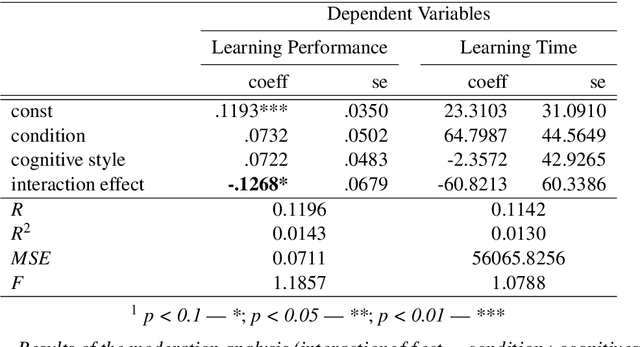

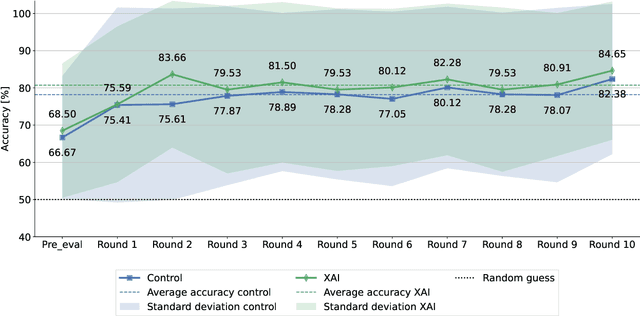
In numerous high-stakes domains, training novices via conventional learning systems does not suffice. To impart tacit knowledge, experts' hands-on guidance is imperative. However, training novices by experts is costly and time-consuming, increasing the need for alternatives. Explainable artificial intelligence (XAI) has conventionally been used to make black-box artificial intelligence systems interpretable. In this work, we utilize XAI as an alternative: An (X)AI system is trained on experts' past decisions and is then employed to teach novices by providing examples coupled with explanations. In a study with 249 participants, we measure the effectiveness of such an approach for a classification task. We show that (X)AI-based learning systems are able to induce learning in novices and that their cognitive styles moderate learning. Thus, we take the first steps to reveal the impact of XAI on human learning and point AI developers to future options to tailor the design of (X)AI-based learning systems.
Improving Label Error Detection and Elimination with Uncertainty Quantification
May 15, 2024

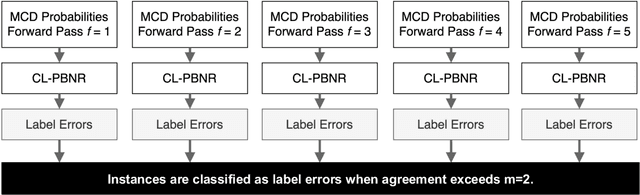
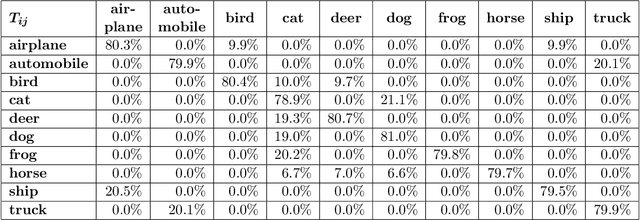
Identifying and handling label errors can significantly enhance the accuracy of supervised machine learning models. Recent approaches for identifying label errors demonstrate that a low self-confidence of models with respect to a certain label represents a good indicator of an erroneous label. However, latest work has built on softmax probabilities to measure self-confidence. In this paper, we argue that -- as softmax probabilities do not reflect a model's predictive uncertainty accurately -- label error detection requires more sophisticated measures of model uncertainty. Therefore, we develop a range of novel, model-agnostic algorithms for Uncertainty Quantification-Based Label Error Detection (UQ-LED), which combine the techniques of confident learning (CL), Monte Carlo Dropout (MCD), model uncertainty measures (e.g., entropy), and ensemble learning to enhance label error detection. We comprehensively evaluate our algorithms on four image classification benchmark datasets in two stages. In the first stage, we demonstrate that our UQ-LED algorithms outperform state-of-the-art confident learning in identifying label errors. In the second stage, we show that removing all identified errors from the training data based on our approach results in higher accuracies than training on all available labeled data. Importantly, besides our contributions to the detection of label errors, we particularly propose a novel approach to generate realistic, class-dependent label errors synthetically. Overall, our study demonstrates that selectively cleaning datasets with UQ-LED algorithms leads to more accurate classifications than using larger, noisier datasets.
On the Effect of Contextual Information on Human Delegation Behavior in Human-AI collaboration
Jan 09, 2024The constantly increasing capabilities of artificial intelligence (AI) open new possibilities for human-AI collaboration. One promising approach to leverage existing complementary capabilities is allowing humans to delegate individual instances to the AI. However, enabling humans to delegate instances effectively requires them to assess both their own and the AI's capabilities in the context of the given task. In this work, we explore the effects of providing contextual information on human decisions to delegate instances to an AI. We find that providing participants with contextual information significantly improves the human-AI team performance. Additionally, we show that the delegation behavior changes significantly when participants receive varying types of contextual information. Overall, this research advances the understanding of human-AI interaction in human delegation and provides actionable insights for designing more effective collaborative systems.
Towards Effective Human-AI Decision-Making: The Role of Human Learning in Appropriate Reliance on AI Advice
Oct 03, 2023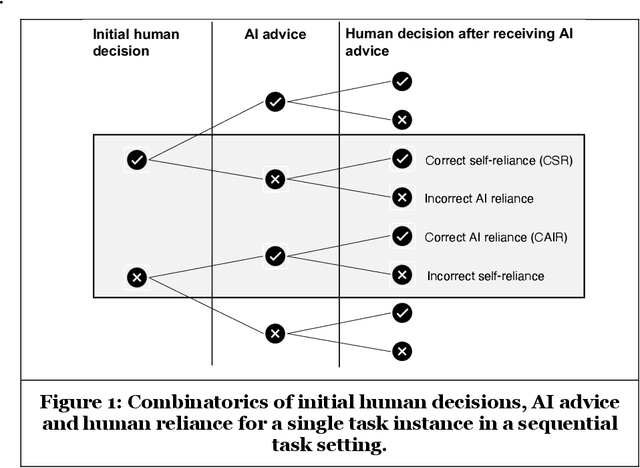

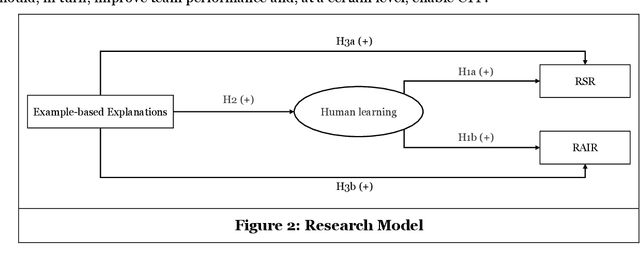

The true potential of human-AI collaboration lies in exploiting the complementary capabilities of humans and AI to achieve a joint performance superior to that of the individual AI or human, i.e., to achieve complementary team performance (CTP). To realize this complementarity potential, humans need to exercise discretion in following AI 's advice, i.e., appropriately relying on the AI's advice. While previous work has focused on building a mental model of the AI to assess AI recommendations, recent research has shown that the mental model alone cannot explain appropriate reliance. We hypothesize that, in addition to the mental model, human learning is a key mediator of appropriate reliance and, thus, CTP. In this study, we demonstrate the relationship between learning and appropriate reliance in an experiment with 100 participants. This work provides fundamental concepts for analyzing reliance and derives implications for the effective design of human-AI decision-making.
Improving the Efficiency of Human-in-the-Loop Systems: Adding Artificial to Human Experts
Jul 07, 2023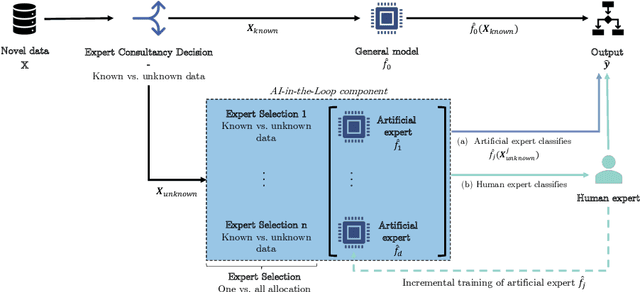


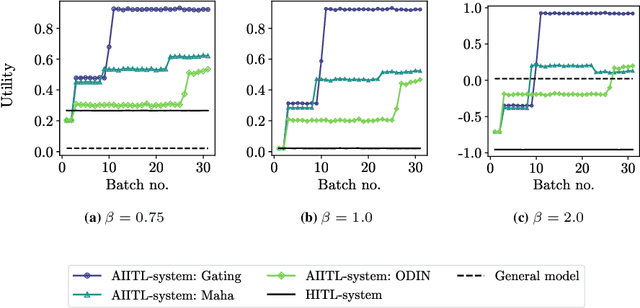
Information systems increasingly leverage artificial intelligence (AI) and machine learning (ML) to generate value from vast amounts of data. However, ML models are imperfect and can generate incorrect classifications. Hence, human-in-the-loop (HITL) extensions to ML models add a human review for instances that are difficult to classify. This study argues that continuously relying on human experts to handle difficult model classifications leads to a strong increase in human effort, which strains limited resources. To address this issue, we propose a hybrid system that creates artificial experts that learn to classify data instances from unknown classes previously reviewed by human experts. Our hybrid system assesses which artificial expert is suitable for classifying an instance from an unknown class and automatically assigns it. Over time, this reduces human effort and increases the efficiency of the system. Our experiments demonstrate that our approach outperforms traditional HITL systems for several benchmarks on image classification.