 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Unknown Objects by Leveraging Human Gaze and Augmented Reality in Human-Robot Interaction
Dec 12, 2023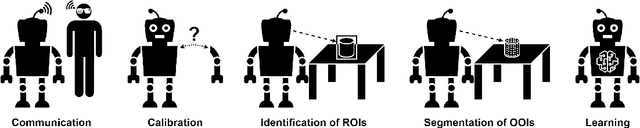


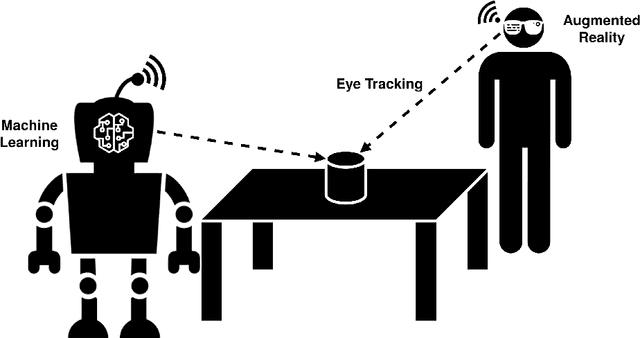
Robots are becoming increasingly popular in a wide range of environments due to their exceptional work capacity, precision, efficiency, and scalability. This development has been further encouraged by advances in Artificial Intelligence, particularly Machine Learning. By employing sophisticated neural networks, robots are given the ability to detect and interact with objects in their vicinity. However, a significant drawback arises from the underlying dependency on extensive datasets and the availability of substantial amounts of training data for these object detection models. This issue becomes particularly problematic when the specific deployment location of the robot and the surroundings, are not known in advance. The vast and ever-expanding array of objects makes it virtually impossible to comprehensively cover the entire spectrum of existing objects using preexisting datasets alone. The goal of this dissertation was to teach a robot unknown objects in the context of Human-Robot Interaction (HRI) in order to liberate it from its data dependency, unleashing it from predefined scenarios. In this context, the combination of eye tracking and Augmented Reality created a powerful synergy that empowered the human teacher to communicate with the robot and effortlessly point out objects by means of human gaze. This holistic approach led to the development of a multimodal HRI system that enabled the robot to identify and visually segment the Objects of Interest in 3D space. Through the class information provided by the human, the robot was able to learn the objects and redetect them at a later stage. Due to the knowledge gained from this HRI based teaching, the robot's object detection capabilities exhibited comparable performance to state-of-the-art object detectors trained on extensive datasets, without being restricted to predefined classes, showcasing its versatility and adaptability.
Improving the Efficiency of Human-in-the-Loop Systems: Adding Artificial to Human Experts
Jul 07, 2023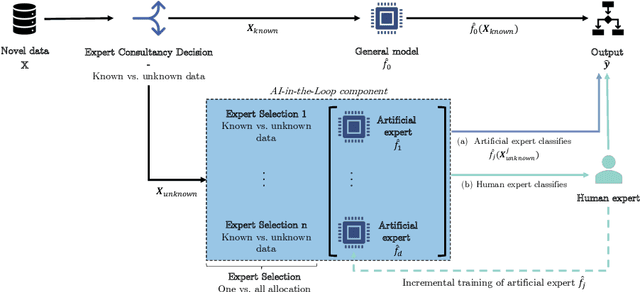


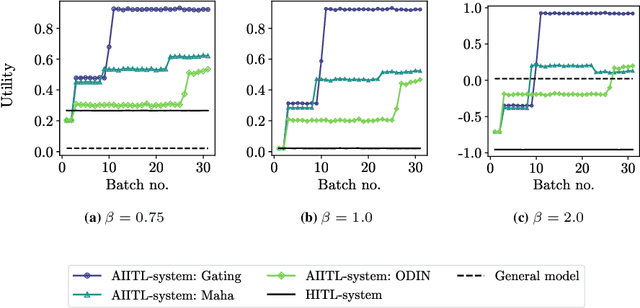
Information systems increasingly leverage artificial intelligence (AI) and machine learning (ML) to generate value from vast amounts of data. However, ML models are imperfect and can generate incorrect classifications. Hence, human-in-the-loop (HITL) extensions to ML models add a human review for instances that are difficult to classify. This study argues that continuously relying on human experts to handle difficult model classifications leads to a strong increase in human effort, which strains limited resources. To address this issue, we propose a hybrid system that creates artificial experts that learn to classify data instances from unknown classes previously reviewed by human experts. Our hybrid system assesses which artificial expert is suitable for classifying an instance from an unknown class and automatically assigns it. Over time, this reduces human effort and increases the efficiency of the system. Our experiments demonstrate that our approach outperforms traditional HITL systems for several benchmarks on image classification.
Multiperspective Teaching of Unknown Objects via Shared-gaze-based Multimodal Human-Robot Interaction
Mar 01, 2023



For successful deployment of robots in multifaceted situations, an understanding of the robot for its environment is indispensable. With advancing performance of state-of-the-art object detectors, the capability of robots to detect objects within their interaction domain is also enhancing. However, it binds the robot to a few trained classes and prevents it from adapting to unfamiliar surroundings beyond predefined scenarios. In such scenarios, humans could assist robots amidst the overwhelming number of interaction entities and impart the requisite expertise by acting as teachers. We propose a novel pipeline that effectively harnesses human gaze and augmented reality in a human-robot collaboration context to teach a robot novel objects in its surrounding environment. By intertwining gaze (to guide the robot's attention to an object of interest) with augmented reality (to convey the respective class information) we enable the robot to quickly acquire a significant amount of automatically labeled training data on its own. Training in a transfer learning fashion, we demonstrate the robot's capability to detect recently learned objects and evaluate the influence of different machine learning models and learning procedures as well as the amount of training data involved. Our multimodal approach proves to be an efficient and natural way to teach the robot novel objects based on a few instances and allows it to detect classes for which no training dataset is available. In addition, we make our dataset publicly available to the research community, which consists of RGB and depth data, intrinsic and extrinsic camera parameters, along with regions of interest.
Gaze-based Object Detection in the Wild
Mar 29, 2022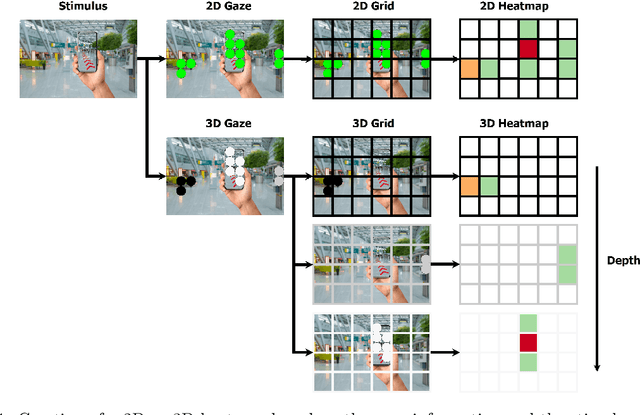
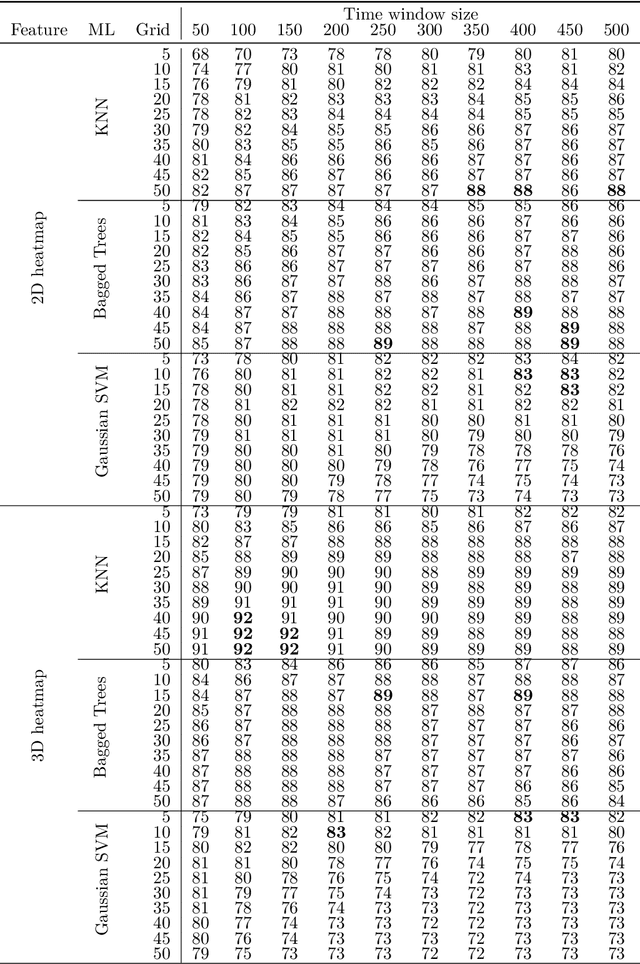
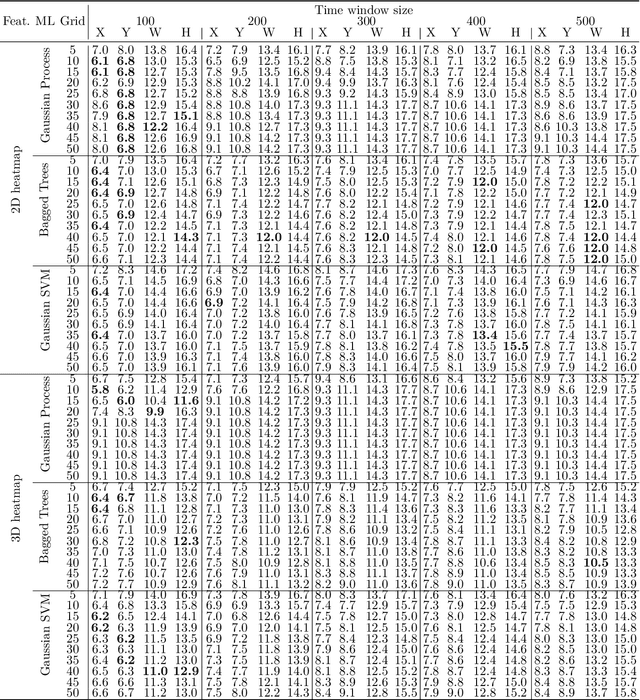
In human-robot collaboration, one challenging task is to teach a robot new yet unknown objects. Thereby, gaze can contain valuable information. We investigate if it is possible to detect objects (object or no object) from gaze data and determine their bounding box parameters. For this purpose, we explore different sizes of temporal windows, which serve as a basis for the computation of heatmaps, i.e., the spatial distribution of the gaze data. Additionally, we analyze different grid sizes of these heatmaps, and various machine learning techniques are applied. To generate the data, we conducted a small study with five subjects who could move freely and thus, turn towards arbitrary objects. This way, we chose a scenario for our data collection that is as realistic as possible. Since the subjects move while facing objects, the heatmaps also contain gaze data trajectories, complicating the detection and parameter regression.
Steady-State Error Compensation in Reference Tracking and Disturbance Rejection Problems for Reinforcement Learning-Based Control
Jan 31, 2022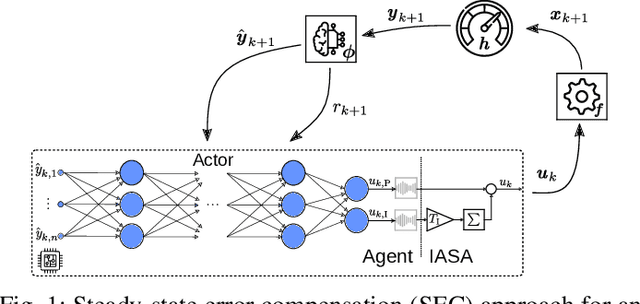
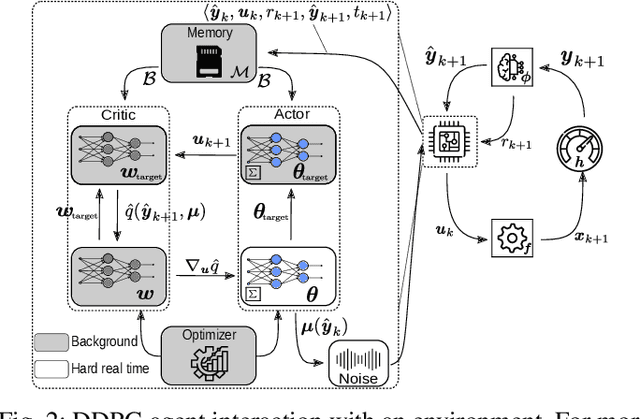

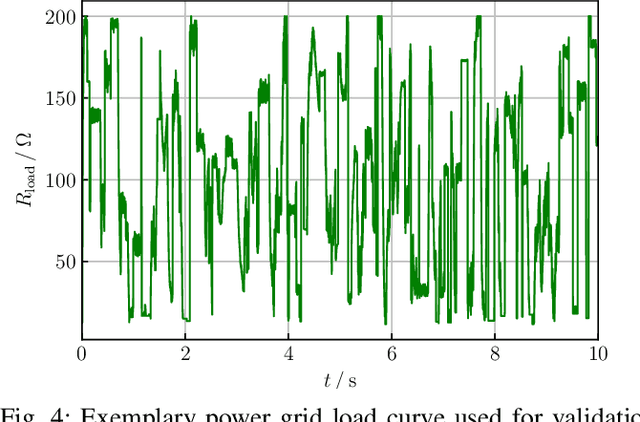
Reinforcement learning (RL) is a promising, upcoming topic in automatic control applications. Where classical control approaches require a priori system knowledge, data-driven control approaches like RL allow a model-free controller design procedure, rendering them emergent techniques for systems with changing plant structures and varying parameters. While it was already shown in various applications that the transient control behavior for complex systems can be sufficiently handled by RL, the challenge of non-vanishing steady-state control errors remains, which arises from the usage of control policy approximations and finite training times. To overcome this issue, an integral action state augmentation (IASA) for actor-critic-based RL controllers is introduced that mimics an integrating feedback, which is inspired by the delta-input formulation within model predictive control. This augmentation does not require any expert knowledge, leaving the approach model free. As a result, the RL controller learns how to suppress steady-state control deviations much more effectively. Two exemplary applications from the domain of electrical energy engineering validate the benefit of the developed method both for reference tracking and disturbance rejection. In comparison to a standard deep deterministic policy gradient (DDPG) setup, the suggested IASA extension allows to reduce the steady-state error by up to 52 $\%$ within the considered validation scenarios.
Pistol: Pupil Invisible Supportive Tool to extract Pupil, Iris, Eye Opening, Eye Movements, Pupil and Iris Gaze Vector, and 2D as well as 3D Gaze
Jan 18, 2022
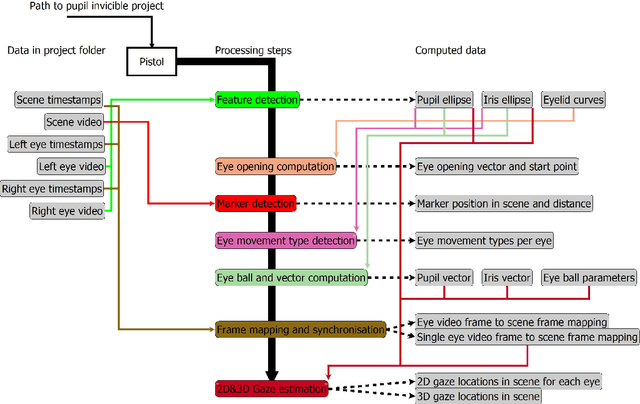

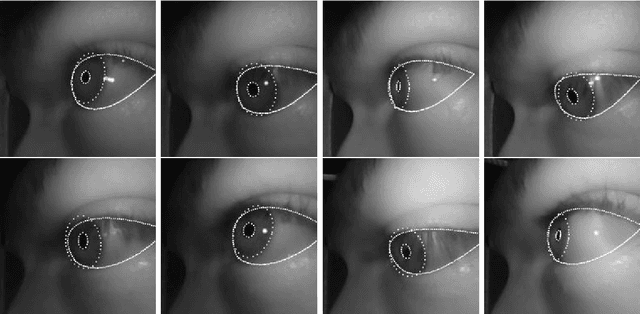
This paper describes a feature extraction and gaze estimation software, named Pistol that can be used with Pupil Invisible projects and other eye trackers in the future. In offline mode, our software extracts multiple features from the eye including, the pupil and iris ellipse, eye aperture, pupil vector, iris vector, eye movement types from pupil and iris velocities, marker detection, marker distance, 2D gaze estimation for the pupil center, iris center, pupil vector, and iris vector using Levenberg Marquart fitting and neural networks. The gaze signal is computed in 2D for each eye and each feature separately and for both eyes in 3D also for each feature separately. We hope this software helps other researchers to extract state-of-the-art features for their research out of their recordings.
Non-Autoregressive vs Autoregressive Neural Networks for System Identification
May 05, 2021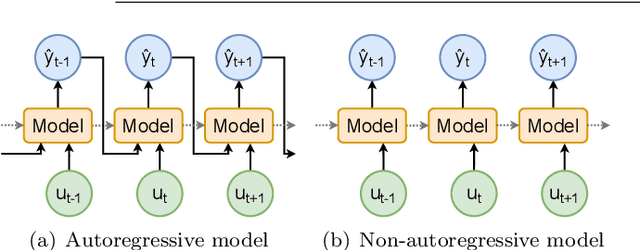
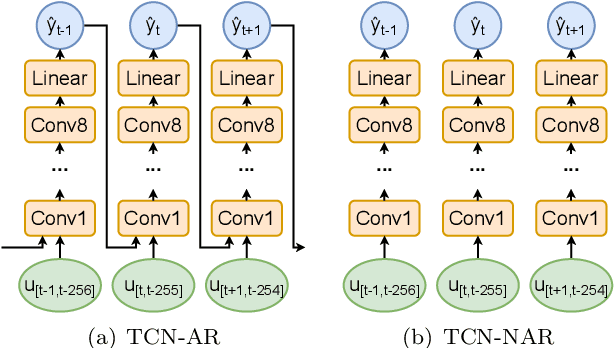

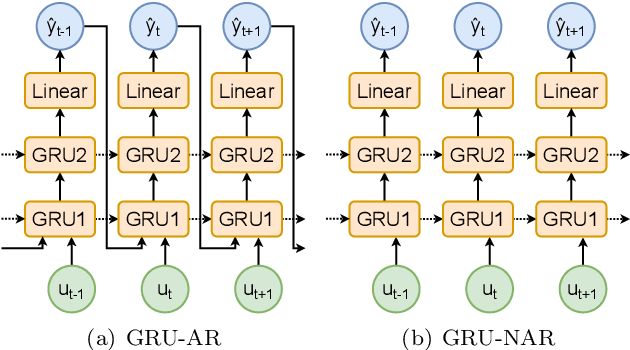
The application of neural networks to non-linear dynamic system identification tasks has a long history, which consists mostly of autoregressive approaches. Autoregression, the usage of the model outputs of previous time steps, is a method of transferring a system state between time steps, which is not necessary for modeling dynamic systems with modern neural network structures, such as gated recurrent units (GRUs) and Temporal Convolutional Networks (TCNs). We compare the accuracy and execution performance of autoregressive and non-autoregressive implementations of a GRU and TCN on the simulation task of three publicly available system identification benchmarks. Our results show, that the non-autoregressive neural networks are significantly faster and at least as accurate as their autoregressive counterparts. Comparisons with other state-of-the-art black-box system identification methods show, that our implementation of the non-autoregressive GRU is the best performing neural network-based system identification method, and in the benchmarks without extrapolation, the best performing black-box method.
RIANN -- A Robust Neural Network Outperforms Attitude Estimation Filters
May 05, 2021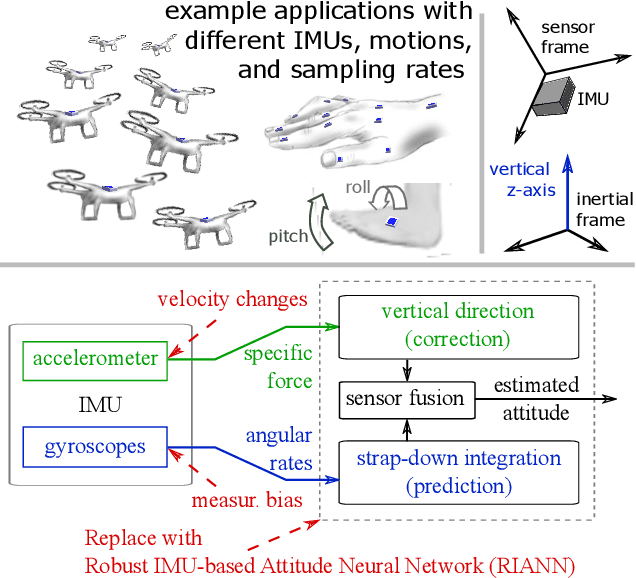
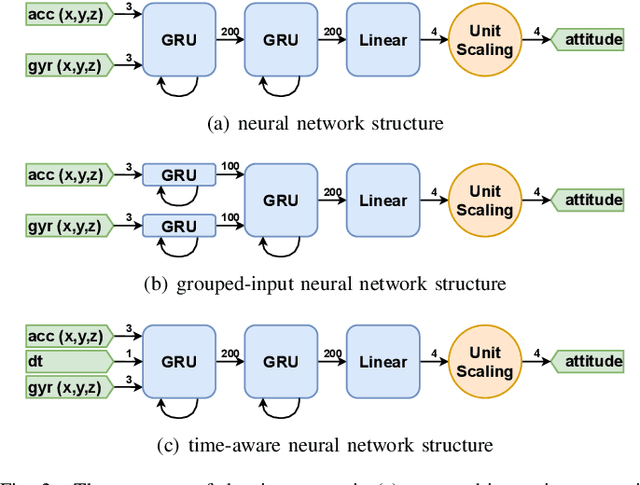
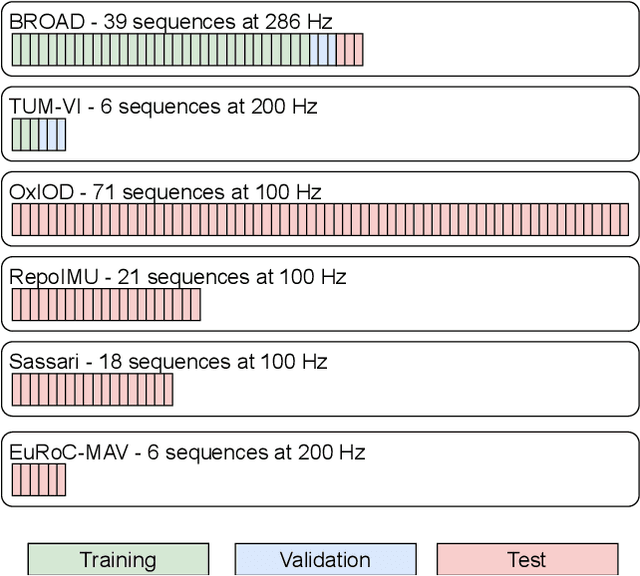
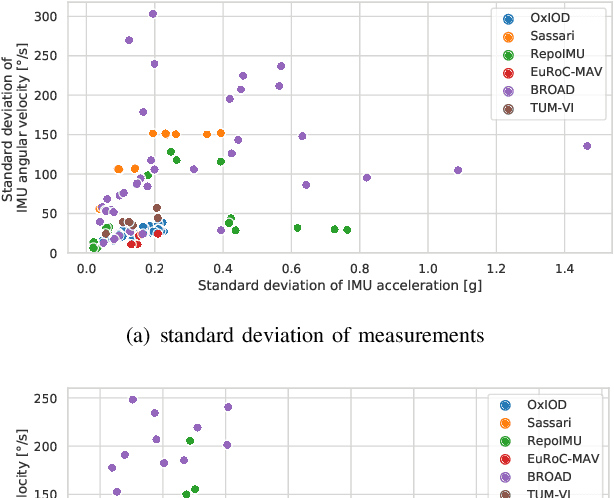
Inertial-sensor-based attitude estimation is a crucial technology in various applications, from human motion tracking to autonomous aerial and ground vehicles. Application scenarios differ in characteristics of the performed motion, presence of disturbances, and environmental conditions. Since state-of-the-art attitude estimators do not generalize well over these characteristics, their parameters must be tuned for the individual motion characteristics and circumstances. We propose RIANN, a real-time-capable neural network for robust IMU-based attitude estimation, which generalizes well across different motion dynamics, environments, and sampling rates, without the need for application-specific adaptations. We exploit two publicly available datasets for the method development and the training, and we add four completely different datasets for evaluation of the trained neural network in three different test scenarios with varying practical relevance. Results show that RIANN performs at least as well as state-of-the-art attitude estimation filters and outperforms them in several cases, even if the filter is tuned on the very same test dataset itself while RIANN has never seen data from that dataset, from the specific application, the same sensor hardware, or the same sampling frequency before. RIANN is expected to enable plug-and-play solutions in numerous applications, especially when accuracy is crucial but no ground-truth data is available for tuning or when motion and disturbance characteristics are uncertain. We made RIANN publicly available.
Neural Networks Versus Conventional Filters for Inertial-Sensor-based Attitude Estimation
Jun 03, 2020
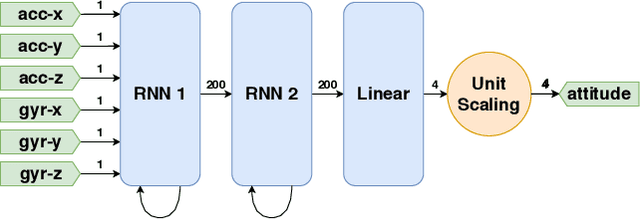
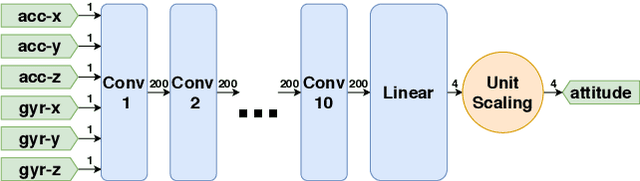
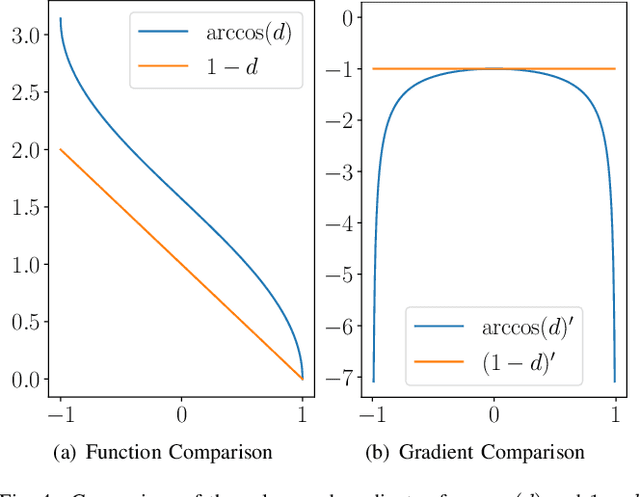
Inertial measurement units are commonly used to estimate the attitude of moving objects. Numerous nonlinear filter approaches have been proposed for solving the inherent sensor fusion problem. However, when a large range of different dynamic and static rotational and translational motions is considered, the attainable accuracy is limited by the need for situation-dependent adjustment of accelerometer and gyroscope fusion weights. We investigate to what extent these limitations can be overcome by means of artificial neural networks and how much domain-specific optimization of the neural network model is required to outperform the conventional filter solution. A diverse set of motion recordings with a marker-based optical ground truth is used for performance evaluation and comparison. The proposed neural networks are found to outperform the conventional filter across all motions only if domain-specific optimizations are introduced. We conclude that they are a promising tool for inertial-sensor-based real-time attitude estimation, but both expert knowledge and rich datasets are required to achieve top performance.