 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Appropriate Reliance: Human-AI Collaboration with a Multi-Step Transparent Decision Workflow for Complex Task Decomposition
Jan 19, 2025In recent years, the rapid development of AI systems has brought about the benefits of intelligent services but also concerns about security and reliability. By fostering appropriate user reliance on an AI system, both complementary team performance and reduced human workload can be achieved. Previous empirical studies have extensively analyzed the impact of factors ranging from task, system, and human behavior on user trust and appropriate reliance in the context of one-step decision making. However, user reliance on AI systems in tasks with complex semantics that require multi-step workflows remains under-explored. Inspired by recent work on task decomposition with large language models, we propose to investigate the impact of a novel Multi-Step Transparent (MST) decision workflow on user reliance behaviors. We conducted an empirical study (N = 233) of AI-assisted decision making in composite fact-checking tasks (i.e., fact-checking tasks that entail multiple sub-fact verification steps). Our findings demonstrate that human-AI collaboration with an MST decision workflow can outperform one-step collaboration in specific contexts (e.g., when advice from an AI system is misleading). Further analysis of the appropriate reliance at fine-grained levels indicates that an MST decision workflow can be effective when users demonstrate a relatively high consideration of the intermediate steps. Our work highlights that there is no one-size-fits-all decision workflow that can help obtain optimal human-AI collaboration. Our insights help deepen the understanding of the role of decision workflows in facilitating appropriate reliance. We synthesize important implications for designing effective means to facilitate appropriate reliance on AI systems in composite tasks, positioning opportunities for the human-centered AI and broader HCI communities.
Improving Label Error Detection and Elimination with Uncertainty Quantification
May 15, 2024

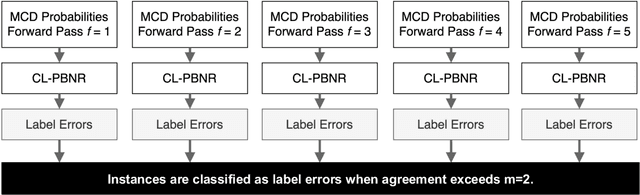
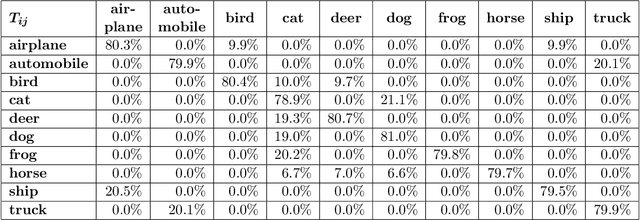
Identifying and handling label errors can significantly enhance the accuracy of supervised machine learning models. Recent approaches for identifying label errors demonstrate that a low self-confidence of models with respect to a certain label represents a good indicator of an erroneous label. However, latest work has built on softmax probabilities to measure self-confidence. In this paper, we argue that -- as softmax probabilities do not reflect a model's predictive uncertainty accurately -- label error detection requires more sophisticated measures of model uncertainty. Therefore, we develop a range of novel, model-agnostic algorithms for Uncertainty Quantification-Based Label Error Detection (UQ-LED), which combine the techniques of confident learning (CL), Monte Carlo Dropout (MCD), model uncertainty measures (e.g., entropy), and ensemble learning to enhance label error detection. We comprehensively evaluate our algorithms on four image classification benchmark datasets in two stages. In the first stage, we demonstrate that our UQ-LED algorithms outperform state-of-the-art confident learning in identifying label errors. In the second stage, we show that removing all identified errors from the training data based on our approach results in higher accuracies than training on all available labeled data. Importantly, besides our contributions to the detection of label errors, we particularly propose a novel approach to generate realistic, class-dependent label errors synthetically. Overall, our study demonstrates that selectively cleaning datasets with UQ-LED algorithms leads to more accurate classifications than using larger, noisier datasets.
On the Effect of Contextual Information on Human Delegation Behavior in Human-AI collaboration
Jan 09, 2024The constantly increasing capabilities of artificial intelligence (AI) open new possibilities for human-AI collaboration. One promising approach to leverage existing complementary capabilities is allowing humans to delegate individual instances to the AI. However, enabling humans to delegate instances effectively requires them to assess both their own and the AI's capabilities in the context of the given task. In this work, we explore the effects of providing contextual information on human decisions to delegate instances to an AI. We find that providing participants with contextual information significantly improves the human-AI team performance. Additionally, we show that the delegation behavior changes significantly when participants receive varying types of contextual information. Overall, this research advances the understanding of human-AI interaction in human delegation and provides actionable insights for designing more effective collaborative systems.
Navigating the Synthetic Realm: Harnessing Diffusion-based Models for Laparoscopic Text-to-Image Generation
Dec 05, 2023

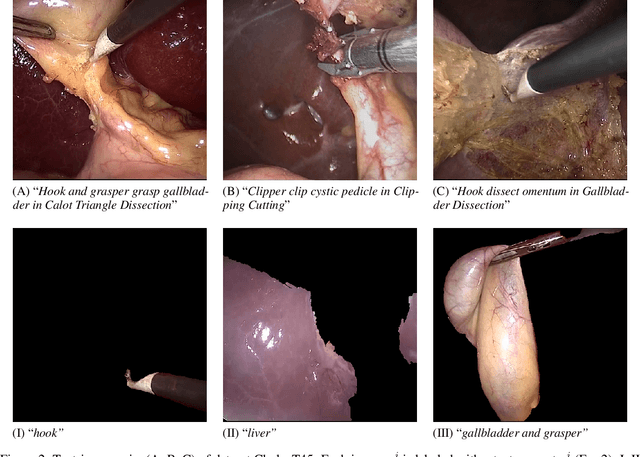

Recent advances in synthetic imaging open up opportunities for obtaining additional data in the field of surgical imaging. This data can provide reliable supplements supporting surgical applications and decision-making through computer vision. Particularly the field of image-guided surgery, such as laparoscopic and robotic-assisted surgery, benefits strongly from synthetic image datasets and virtual surgical training methods. Our study presents an intuitive approach for generating synthetic laparoscopic images from short text prompts using diffusion-based generative models. We demonstrate the usage of state-of-the-art text-to-image architectures in the context of laparoscopic imaging with regard to the surgical removal of the gallbladder as an example. Results on fidelity and diversity demonstrate that diffusion-based models can acquire knowledge about the style and semantics in the field of image-guided surgery. A validation study with a human assessment survey underlines the realistic nature of our synthetic data, as medical personnel detects actual images in a pool with generated images causing a false-positive rate of 66%. In addition, the investigation of a state-of-the-art machine learning model to recognize surgical actions indicates enhanced results when trained with additional generated images of up to 5.20%. Overall, the achieved image quality contributes to the usage of computer-generated images in surgical applications and enhances its path to maturity.
Redefining the Laparoscopic Spatial Sense: AI-based Intra- and Postoperative Measurement from Stereoimages
Nov 16, 2023



A significant challenge in image-guided surgery is the accurate measurement task of relevant structures such as vessel segments, resection margins, or bowel lengths. While this task is an essential component of many surgeries, it involves substantial human effort and is prone to inaccuracies. In this paper, we develop a novel human-AI-based method for laparoscopic measurements utilizing stereo vision that has been guided by practicing surgeons. Based on a holistic qualitative requirements analysis, this work proposes a comprehensive measurement method, which comprises state-of-the-art machine learning architectures, such as RAFT-Stereo and YOLOv8. The developed method is assessed in various realistic experimental evaluation environments. Our results outline the potential of our method achieving high accuracies in distance measurements with errors below 1 mm. Furthermore, on-surface measurements demonstrate robustness when applied in challenging environments with textureless regions. Overall, by addressing the inherent challenges of image-guided surgery, we lay the foundation for a more robust and accurate solution for intra- and postoperative measurements, enabling more precise, safe, and efficient surgical procedures.
Improving the Efficiency of Human-in-the-Loop Systems: Adding Artificial to Human Experts
Jul 07, 2023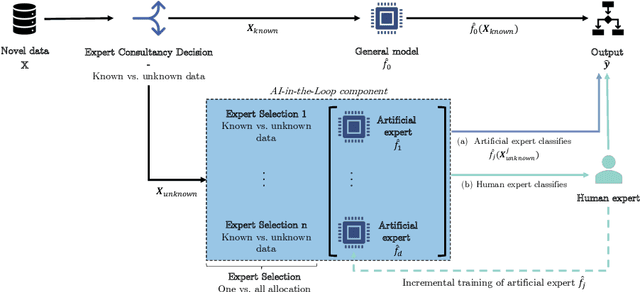


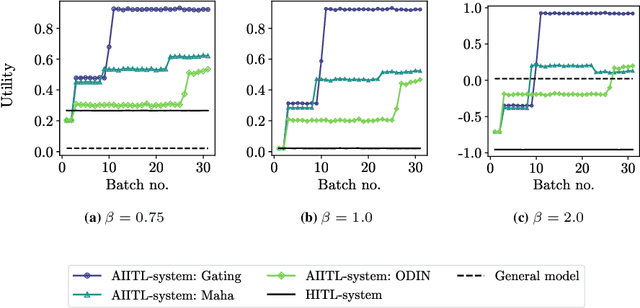
Information systems increasingly leverage artificial intelligence (AI) and machine learning (ML) to generate value from vast amounts of data. However, ML models are imperfect and can generate incorrect classifications. Hence, human-in-the-loop (HITL) extensions to ML models add a human review for instances that are difficult to classify. This study argues that continuously relying on human experts to handle difficult model classifications leads to a strong increase in human effort, which strains limited resources. To address this issue, we propose a hybrid system that creates artificial experts that learn to classify data instances from unknown classes previously reviewed by human experts. Our hybrid system assesses which artificial expert is suitable for classifying an instance from an unknown class and automatically assigns it. Over time, this reduces human effort and increases the efficiency of the system. Our experiments demonstrate that our approach outperforms traditional HITL systems for several benchmarks on image classification.
What a MESS: Multi-Domain Evaluation of Zero-Shot Semantic Segmentation
Jun 27, 2023



While semantic segmentation has seen tremendous improvements in the past, there is still significant labeling efforts necessary and the problem of limited generalization to classes that have not been present during training. To address this problem, zero-shot semantic segmentation makes use of large self-supervised vision-language models, allowing zero-shot transfer to unseen classes. In this work, we build a benchmark for Multi-domain Evaluation of Semantic Segmentation (MESS), which allows a holistic analysis of performance across a wide range of domain-specific datasets such as medicine, engineering, earth monitoring, biology, and agriculture. To do this, we reviewed 120 datasets, developed a taxonomy, and classified the datasets according to the developed taxonomy. We select a representative subset consisting of 22 datasets and propose it as the MESS benchmark. We evaluate eight recently published models on the proposed MESS benchmark and analyze characteristics for the performance of zero-shot transfer models. The toolkit is available at https://github.com/blumenstiel/MESS.
On the Perception of Difficulty: Differences between Humans and AI
Apr 19, 2023

With the increased adoption of artificial intelligence (AI) in industry and society, effective human-AI interaction systems are becoming increasingly important. A central challenge in the interaction of humans with AI is the estimation of difficulty for human and AI agents for single task instances.These estimations are crucial to evaluate each agent's capabilities and, thus, required to facilitate effective collaboration. So far, research in the field of human-AI interaction estimates the perceived difficulty of humans and AI independently from each other. However, the effective interaction of human and AI agents depends on metrics that accurately reflect each agent's perceived difficulty in achieving valuable outcomes. Research to date has not yet adequately examined the differences in the perceived difficulty of humans and AI. Thus, this work reviews recent research on the perceived difficulty in human-AI interaction and contributing factors to consistently compare each agent's perceived difficulty, e.g., creating the same prerequisites. Furthermore, we present an experimental design to thoroughly examine the perceived difficulty of both agents and contribute to a better understanding of the design of such systems.
Learning to Defer with Limited Expert Predictions
Apr 14, 2023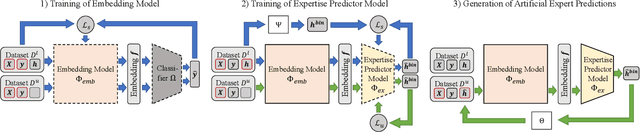
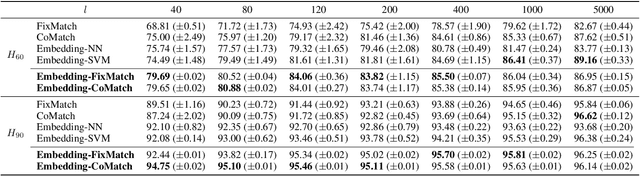
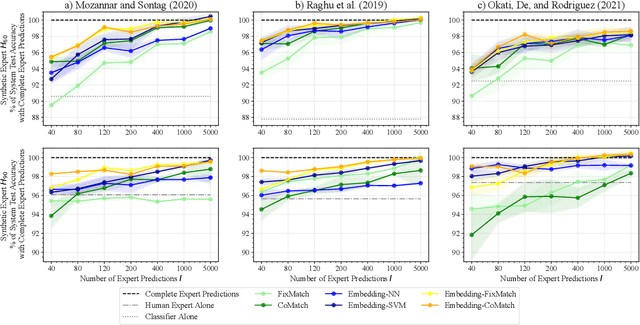

Recent research suggests that combining AI models with a human expert can exceed the performance of either alone. The combination of their capabilities is often realized by learning to defer algorithms that enable the AI to learn to decide whether to make a prediction for a particular instance or defer it to the human expert. However, to accurately learn which instances should be deferred to the human expert, a large number of expert predictions that accurately reflect the expert's capabilities are required -- in addition to the ground truth labels needed to train the AI. This requirement shared by many learning to defer algorithms hinders their adoption in scenarios where the responsible expert regularly changes or where acquiring a sufficient number of expert predictions is costly. In this paper, we propose a three-step approach to reduce the number of expert predictions required to train learning to defer algorithms. It encompasses (1) the training of an embedding model with ground truth labels to generate feature representations that serve as a basis for (2) the training of an expertise predictor model to approximate the expert's capabilities. (3) The expertise predictor generates artificial expert predictions for instances not yet labeled by the expert, which are required by the learning to defer algorithms. We evaluate our approach on two public datasets. One with "synthetically" generated human experts and another from the medical domain containing real-world radiologists' predictions. Our experiments show that the approach allows the training of various learning to defer algorithms with a minimal number of human expert predictions. Furthermore, we demonstrate that even a small number of expert predictions per class is sufficient for these algorithms to exceed the performance the AI and the human expert can achieve individually.
Human-AI Collaboration: The Effect of AI Delegation on Human Task Performance and Task Satisfaction
Mar 16, 2023Recent work has proposed artificial intelligence (AI) models that can learn to decide whether to make a prediction for an instance of a task or to delegate it to a human by considering both parties' capabilities. In simulations with synthetically generated or context-independent human predictions, delegation can help improve the performance of human-AI teams -- compared to humans or the AI model completing the task alone. However, so far, it remains unclear how humans perform and how they perceive the task when they are aware that an AI model delegated task instances to them. In an experimental study with 196 participants, we show that task performance and task satisfaction improve through AI delegation, regardless of whether humans are aware of the delegation. Additionally, we identify humans' increased levels of self-efficacy as the underlying mechanism for these improvements in performance and satisfaction. Our findings provide initial evidence that allowing AI models to take over more management responsibilities can be an effective form of human-AI collaboration in workplaces.