 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Label Error Detection and Elimination with Uncertainty Quantification
Paper and Code
May 15, 2024

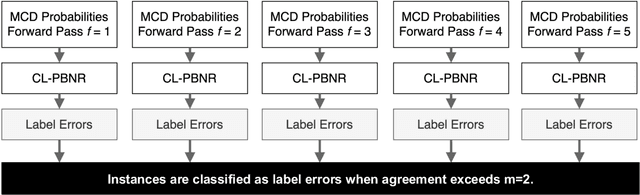
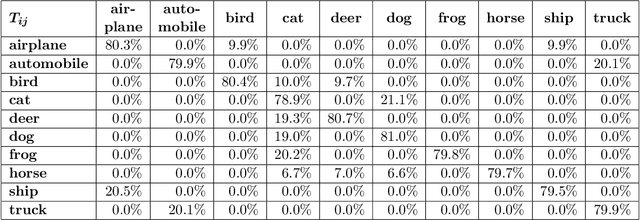
Identifying and handling label errors can significantly enhance the accuracy of supervised machine learning models. Recent approaches for identifying label errors demonstrate that a low self-confidence of models with respect to a certain label represents a good indicator of an erroneous label. However, latest work has built on softmax probabilities to measure self-confidence. In this paper, we argue that -- as softmax probabilities do not reflect a model's predictive uncertainty accurately -- label error detection requires more sophisticated measures of model uncertainty. Therefore, we develop a range of novel, model-agnostic algorithms for Uncertainty Quantification-Based Label Error Detection (UQ-LED), which combine the techniques of confident learning (CL), Monte Carlo Dropout (MCD), model uncertainty measures (e.g., entropy), and ensemble learning to enhance label error detection. We comprehensively evaluate our algorithms on four image classification benchmark datasets in two stages. In the first stage, we demonstrate that our UQ-LED algorithms outperform state-of-the-art confident learning in identifying label errors. In the second stage, we show that removing all identified errors from the training data based on our approach results in higher accuracies than training on all available labeled data. Importantly, besides our contributions to the detection of label errors, we particularly propose a novel approach to generate realistic, class-dependent label errors synthetically. Overall, our study demonstrates that selectively cleaning datasets with UQ-LED algorithms leads to more accurate classifications than using larger, noisier datasets.