 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEO-Bench-2: From Performance to Capability, Rethinking Evaluation in Geospatial AI
Nov 19, 2025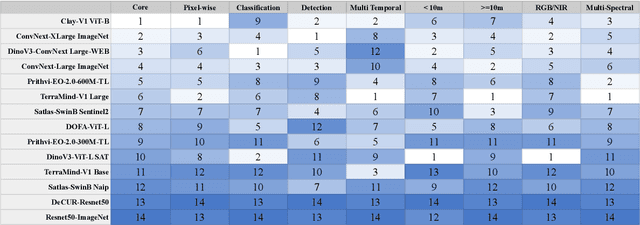
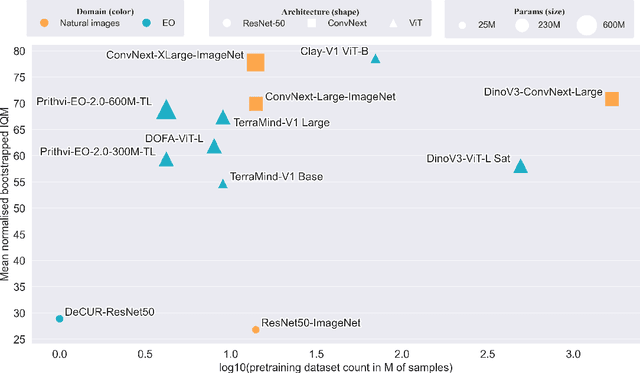
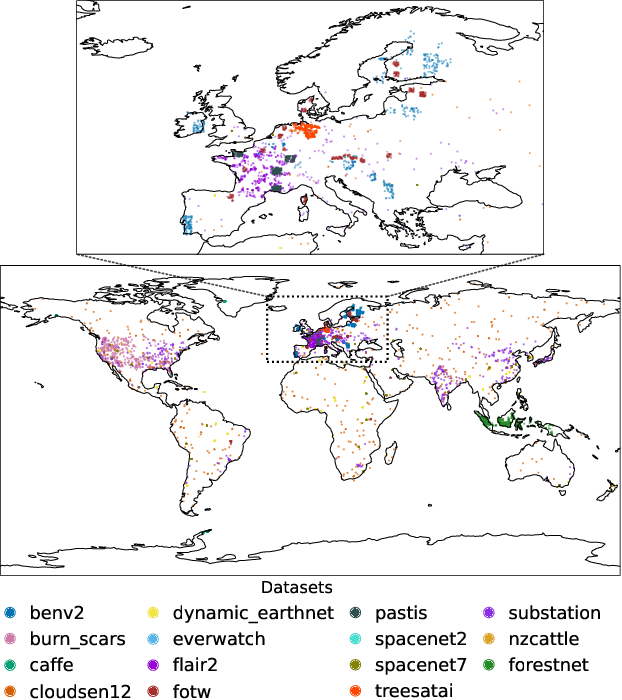
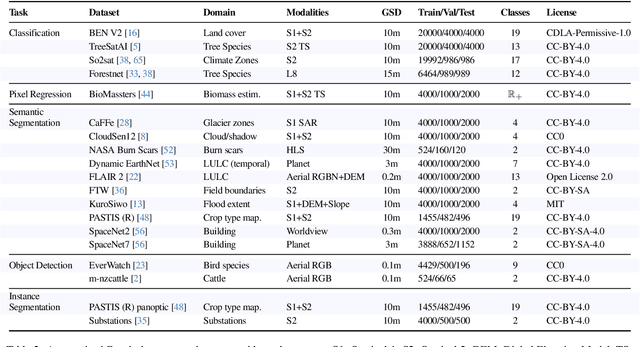
Geospatial Foundation Models (GeoFMs) are transforming Earth Observation (EO), but evaluation lacks standardized protocols. GEO-Bench-2 addresses this with a comprehensive framework spanning classification, segmentation, regression, object detection, and instance segmentation across 19 permissively-licensed datasets. We introduce ''capability'' groups to rank models on datasets that share common characteristics (e.g., resolution, bands, temporality). This enables users to identify which models excel in each capability and determine which areas need improvement in future work. To support both fair comparison and methodological innovation, we define a prescriptive yet flexible evaluation protocol. This not only ensures consistency in benchmarking but also facilitates research into model adaptation strategies, a key and open challenge in advancing GeoFMs for downstream tasks. Our experiments show that no single model dominates across all tasks, confirming the specificity of the choices made during architecture design and pretraining. While models pretrained on natural images (ConvNext ImageNet, DINO V3) excel on high-resolution tasks, EO-specific models (TerraMind, Prithvi, and Clay) outperform them on multispectral applications such as agriculture and disaster response. These findings demonstrate that optimal model choice depends on task requirements, data modalities, and constraints. This shows that the goal of a single GeoFM model that performs well across all tasks remains open for future research. GEO-Bench-2 enables informed, reproducible GeoFM evaluation tailored to specific use cases. Code, data, and leaderboard for GEO-Bench-2 are publicly released under a permissive license.
Finetuning AI Foundation Models to Develop Subgrid-Scale Parameterizations: A Case Study on Atmospheric Gravity Waves
Sep 04, 2025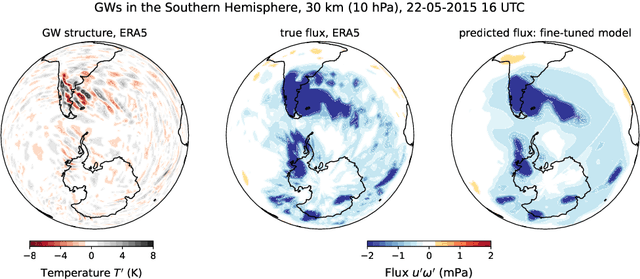



Global climate models parameterize a range of atmospheric-oceanic processes like gravity waves, clouds, moist convection, and turbulence that cannot be sufficiently resolved. These subgrid-scale closures for unresolved processes are a leading source of model uncertainty. Here, we present a new approach to developing machine learning parameterizations of small-scale climate processes by fine-tuning a pre-trained AI foundation model (FM). FMs are largely unexplored in climate research. A pre-trained encoder-decoder from a 2.3 billion parameter FM (NASA and IBM Research's Prithvi WxC) -- which contains a latent probabilistic representation of atmospheric evolution -- is fine-tuned (or reused) to create a deep learning parameterization for atmospheric gravity waves (GWs). The parameterization captures GW effects for a coarse-resolution climate model by learning the fluxes from an atmospheric reanalysis with 10 times finer resolution. A comparison of monthly averages and instantaneous evolution with a machine learning model baseline (an Attention U-Net) reveals superior predictive performance of the FM parameterization throughout the atmosphere, even in regions excluded from pre-training. This performance boost is quantified using the Hellinger distance, which is 0.11 for the baseline and 0.06 for the fine-tuned model. Our findings emphasize the versatility and reusability of FMs, which could be used to accomplish a range of atmosphere- and climate-related applications, leading the way for the creation of observations-driven and physically accurate parameterizations for more earth-system processes.
WxC-Bench: A Novel Dataset for Weather and Climate Downstream Tasks
Dec 03, 2024



High-quality machine learning (ML)-ready datasets play a foundational role in developing new artificial intelligence (AI) models or fine-tuning existing models for scientific applications such as weather and climate analysis. Unfortunately, despite the growing development of new deep learning models for weather and climate, there is a scarcity of curated, pre-processed machine learning (ML)-ready datasets. Curating such high-quality datasets for developing new models is challenging particularly because the modality of the input data varies significantly for different downstream tasks addressing different atmospheric scales (spatial and temporal). Here we introduce WxC-Bench (Weather and Climate Bench), a multi-modal dataset designed to support the development of generalizable AI models for downstream use-cases in weather and climate research. WxC-Bench is designed as a dataset of datasets for developing ML-models for a complex weather and climate system, addressing selected downstream tasks as machine learning phenomenon. WxC-Bench encompasses several atmospheric processes from meso-$\beta$ (20 - 200 km) scale to synoptic scales (2500 km), such as aviation turbulence, hurricane intensity and track monitoring, weather analog search, gravity wave parameterization, and natural language report generation. We provide a comprehensive description of the dataset and also present a technical validation for baseline analysis. The dataset and code to prepare the ML-ready data have been made publicly available on Hugging Face -- https://huggingface.co/datasets/nasa-impact/WxC-Bench
Prithvi-EO-2.0: A Versatile Multi-Temporal Foundation Model for Earth Observation Applications
Dec 03, 2024
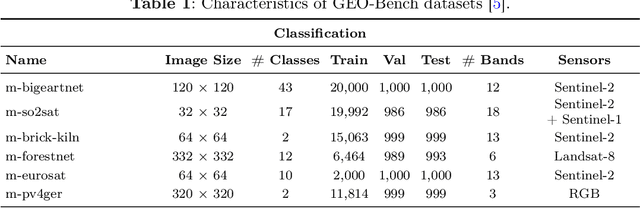
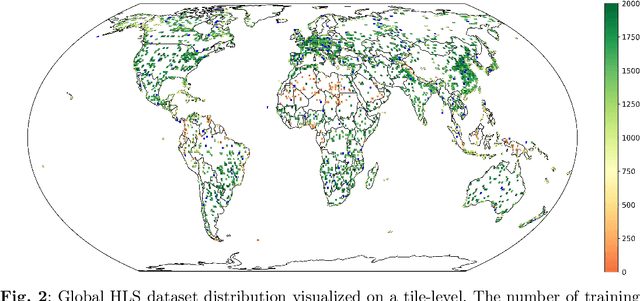
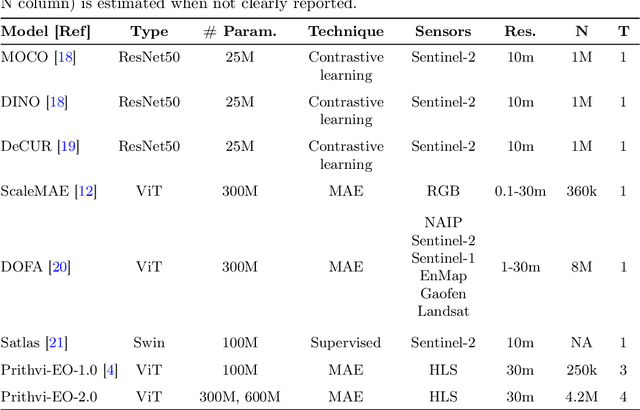
This technical report presents Prithvi-EO-2.0, a new geospatial foundation model that offers significant improvements over its predecessor, Prithvi-EO-1.0. Trained on 4.2M global time series samples from NASA's Harmonized Landsat and Sentinel-2 data archive at 30m resolution, the new 300M and 600M parameter models incorporate temporal and location embeddings for enhanced performance across various geospatial tasks. Through extensive benchmarking with GEO-Bench, the 600M version outperforms the previous Prithvi-EO model by 8\% across a range of tasks. It also outperforms six other geospatial foundation models when benchmarked on remote sensing tasks from different domains and resolutions (i.e. from 0.1m to 15m). The results demonstrate the versatility of the model in both classical earth observation and high-resolution applications. Early involvement of end-users and subject matter experts (SMEs) are among the key factors that contributed to the project's success. In particular, SME involvement allowed for constant feedback on model and dataset design, as well as successful customization for diverse SME-led applications in disaster response, land use and crop mapping, and ecosystem dynamics monitoring. Prithvi-EO-2.0 is available on Hugging Face and IBM terratorch, with additional resources on GitHub. The project exemplifies the Trusted Open Science approach embraced by all involved organizations.
Challenges in Guardrailing Large Language Models for Science
Nov 12, 2024The rapid development in large language models (LLMs) has transformed the landscape of natural language processing and understanding (NLP/NLU), offering significant benefits across various domains. However, when applied to scientific research, these powerful models exhibit critical failure modes related to scientific integrity and trustworthiness. Existing general-purpose LLM guardrails are insufficient to address these unique challenges in the scientific domain. We provide comprehensive guidelines for deploying LLM guardrails in the scientific domain. We identify specific challenges -- including time sensitivity, knowledge contextualization, conflict resolution, and intellectual property concerns -- and propose a guideline framework for the guardrails that can align with scientific needs. These guardrail dimensions include trustworthiness, ethics & bias, safety, and legal aspects. We also outline in detail the implementation strategies that employ white-box, black-box, and gray-box methodologies that can be enforced within scientific contexts.
Machine Learning Global Simulation of Nonlocal Gravity Wave Propagation
Jun 20, 2024Global climate models typically operate at a grid resolution of hundreds of kilometers and fail to resolve atmospheric mesoscale processes, e.g., clouds, precipitation, and gravity waves (GWs). Model representation of these processes and their sources is essential to the global circulation and planetary energy budget, but subgrid scale contributions from these processes are often only approximately represented in models using parameterizations. These parameterizations are subject to approximations and idealizations, which limit their capability and accuracy. The most drastic of these approximations is the "single-column approximation" which completely neglects the horizontal evolution of these processes, resulting in key biases in current climate models. With a focus on atmospheric GWs, we present the first-ever global simulation of atmospheric GW fluxes using machine learning (ML) models trained on the WINDSET dataset to emulate global GW emulation in the atmosphere, as an alternative to traditional single-column parameterizations. Using an Attention U-Net-based architecture trained on globally resolved GW momentum fluxes, we illustrate the importance and effectiveness of global nonlocality, when simulating GWs using data-driven schemes.
INDUS: Effective and Efficient Language Models for Scientific Applications
May 17, 2024
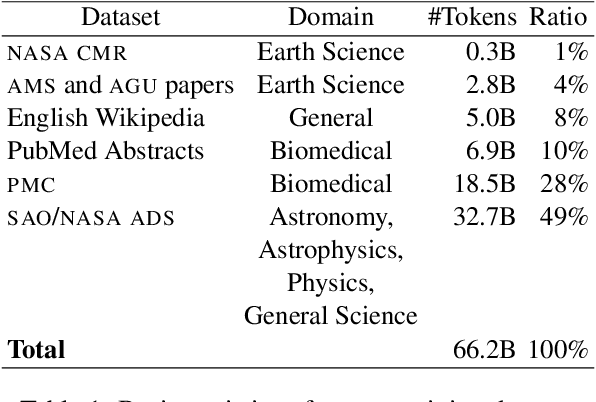
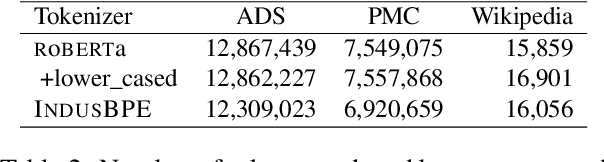

Large language models (LLMs) trained on general domain corpora showed remarkable results on natural language processing (NLP) tasks. However, previous research demonstrated LLMs trained using domain-focused corpora perform better on specialized tasks. Inspired by this pivotal insight, we developed INDUS, a comprehensive suite of LLMs tailored for the Earth science, biology, physics, heliophysics, planetary sciences and astrophysics domains and trained using curated scientific corpora drawn from diverse data sources. The suite of models include: (1) an encoder model trained using domain-specific vocabulary and corpora to address natural language understanding tasks, (2) a contrastive-learning-based general text embedding model trained using a diverse set of datasets drawn from multiple sources to address information retrieval tasks and (3) smaller versions of these models created using knowledge distillation techniques to address applications which have latency or resource constraints. We also created three new scientific benchmark datasets namely, CLIMATE-CHANGE-NER (entity-recognition), NASA-QA (extractive QA) and NASA-IR (IR) to accelerate research in these multi-disciplinary fields. Finally, we show that our models outperform both general-purpose encoders (RoBERTa) and existing domain-specific encoders (SciBERT) on these new tasks as well as existing benchmark tasks in the domains of interest.
Improving Label Error Detection and Elimination with Uncertainty Quantification
May 15, 2024

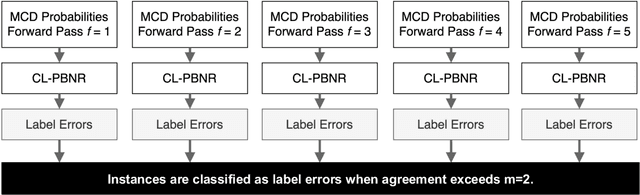
Identifying and handling label errors can significantly enhance the accuracy of supervised machine learning models. Recent approaches for identifying label errors demonstrate that a low self-confidence of models with respect to a certain label represents a good indicator of an erroneous label. However, latest work has built on softmax probabilities to measure self-confidence. In this paper, we argue that -- as softmax probabilities do not reflect a model's predictive uncertainty accurately -- label error detection requires more sophisticated measures of model uncertainty. Therefore, we develop a range of novel, model-agnostic algorithms for Uncertainty Quantification-Based Label Error Detection (UQ-LED), which combine the techniques of confident learning (CL), Monte Carlo Dropout (MCD), model uncertainty measures (e.g., entropy), and ensemble learning to enhance label error detection. We comprehensively evaluate our algorithms on four image classification benchmark datasets in two stages. In the first stage, we demonstrate that our UQ-LED algorithms outperform state-of-the-art confident learning in identifying label errors. In the second stage, we show that removing all identified errors from the training data based on our approach results in higher accuracies than training on all available labeled data. Importantly, besides our contributions to the detection of label errors, we particularly propose a novel approach to generate realistic, class-dependent label errors synthetically. Overall, our study demonstrates that selectively cleaning datasets with UQ-LED algorithms leads to more accurate classifications than using larger, noisier datasets.
Croissant: A Metadata Format for ML-Ready Datasets
Mar 28, 2024Data is a critical resource for Machine Learning (ML), yet working with data remains a key friction point. This paper introduces Croissant, a metadata format for datasets that simplifies how data is used by ML tools and frameworks. Croissant makes datasets more discoverable, portable and interoperable, thereby addressing significant challenges in ML data management and responsible AI. Croissant is already supported by several popular dataset repositories, spanning hundreds of thousands of datasets, ready to be loaded into the most popular ML frameworks.
DMLR: Data-centric Machine Learning Research -- Past, Present and Future
Nov 21, 2023


Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.