 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias Analysis and Mitigation through Protected Attribute Detection and Regard Classification
Apr 19, 2025



Large language models (LLMs) acquire general linguistic knowledge from massive-scale pretraining. However, pretraining data mainly comprised of web-crawled texts contain undesirable social biases which can be perpetuated or even amplified by LLMs. In this study, we propose an efficient yet effective annotation pipeline to investigate social biases in the pretraining corpora. Our pipeline consists of protected attribute detection to identify diverse demographics, followed by regard classification to analyze the language polarity towards each attribute. Through our experiments, we demonstrate the effect of our bias analysis and mitigation measures, focusing on Common Crawl as the most representative pretraining corpus.
Robust ASR Error Correction with Conservative Data Filtering
Jul 18, 2024
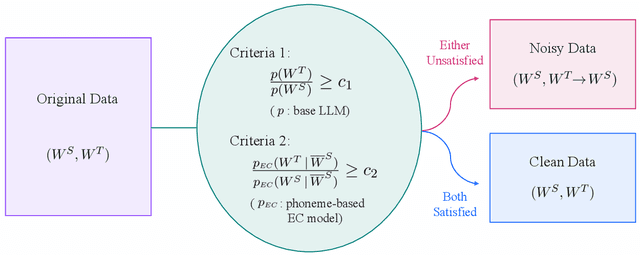

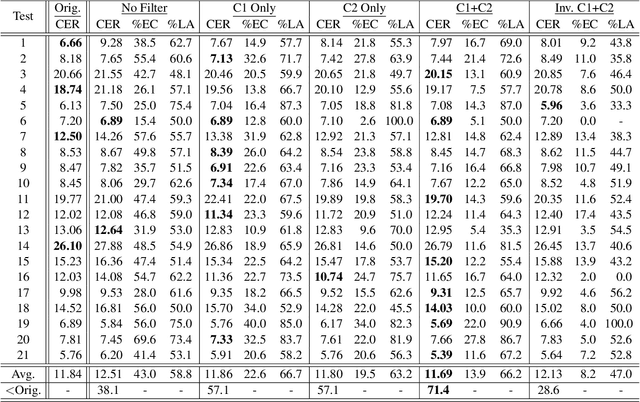
Error correction (EC) based on large language models is an emerging technology to enhance the performance of automatic speech recognition (ASR) systems. Generally, training data for EC are collected by automatically pairing a large set of ASR hypotheses (as sources) and their gold references (as targets). However, the quality of such pairs is not guaranteed, and we observed various types of noise which can make the EC models brittle, e.g. inducing overcorrection in out-of-domain (OOD) settings. In this work, we propose two fundamental criteria that EC training data should satisfy: namely, EC targets should (1) improve linguistic acceptability over sources and (2) be inferable from the available context (e.g. source phonemes). Through these criteria, we identify low-quality EC pairs and train the models not to make any correction in such cases, the process we refer to as conservative data filtering. In our experiments, we focus on Japanese ASR using a strong Conformer-CTC as the baseline and finetune Japanese LLMs for EC. Through our evaluation on a suite of 21 internal benchmarks, we demonstrate that our approach can significantly reduce overcorrection and improve both the accuracy and quality of ASR results in the challenging OOD settings.
INDUS: Effective and Efficient Language Models for Scientific Applications
May 17, 2024
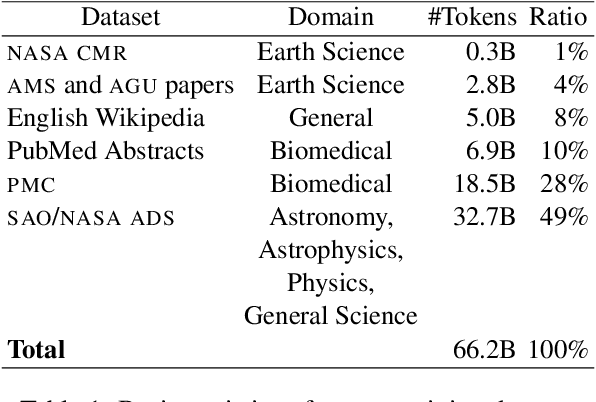
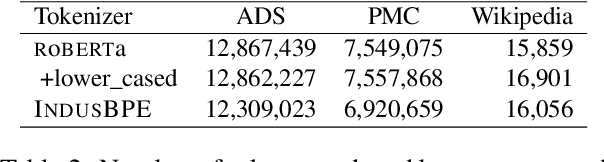

Large language models (LLMs) trained on general domain corpora showed remarkable results on natural language processing (NLP) tasks. However, previous research demonstrated LLMs trained using domain-focused corpora perform better on specialized tasks. Inspired by this pivotal insight, we developed INDUS, a comprehensive suite of LLMs tailored for the Earth science, biology, physics, heliophysics, planetary sciences and astrophysics domains and trained using curated scientific corpora drawn from diverse data sources. The suite of models include: (1) an encoder model trained using domain-specific vocabulary and corpora to address natural language understanding tasks, (2) a contrastive-learning-based general text embedding model trained using a diverse set of datasets drawn from multiple sources to address information retrieval tasks and (3) smaller versions of these models created using knowledge distillation techniques to address applications which have latency or resource constraints. We also created three new scientific benchmark datasets namely, CLIMATE-CHANGE-NER (entity-recognition), NASA-QA (extractive QA) and NASA-IR (IR) to accelerate research in these multi-disciplinary fields. Finally, we show that our models outperform both general-purpose encoders (RoBERTa) and existing domain-specific encoders (SciBERT) on these new tasks as well as existing benchmark tasks in the domains of interest.
A Comparative Analysis of Task-Agnostic Distillation Methods for Compressing Transformer Language Models
Oct 13, 2023Large language models have become a vital component in modern NLP, achieving state of the art performance in a variety of tasks. However, they are often inefficient for real-world deployment due to their expensive inference costs. Knowledge distillation is a promising technique to improve their efficiency while retaining most of their effectiveness. In this paper, we reproduce, compare and analyze several representative methods for task-agnostic (general-purpose) distillation of Transformer language models. Our target of study includes Output Distribution (OD) transfer, Hidden State (HS) transfer with various layer mapping strategies, and Multi-Head Attention (MHA) transfer based on MiniLMv2. Through our extensive experiments, we study the effectiveness of each method for various student architectures in both monolingual (English) and multilingual settings. Overall, we show that MHA transfer based on MiniLMv2 is generally the best option for distillation and explain the potential reasons behind its success. Moreover, we show that HS transfer remains as a competitive baseline, especially under a sophisticated layer mapping strategy, while OD transfer consistently lags behind other approaches. Findings from this study helped us deploy efficient yet effective student models for latency-critical applications.
Multiple Representation Transfer from Large Language Models to End-to-End ASR Systems
Sep 07, 2023



Transferring the knowledge of large language models (LLMs) is a promising technique to incorporate linguistic knowledge into end-to-end automatic speech recognition (ASR) systems. However, existing works only transfer a single representation of LLM (e.g. the last layer of pretrained BERT), while the representation of a text is inherently non-unique and can be obtained variously from different layers, contexts and models. In this work, we explore a wide range of techniques to obtain and transfer multiple representations of LLMs into a transducer-based ASR system. While being conceptually simple, we show that transferring multiple representations of LLMs can be an effective alternative to transferring only a single representation.
Neural Architecture Search for Effective Teacher-Student Knowledge Transfer in Language Models
Mar 16, 2023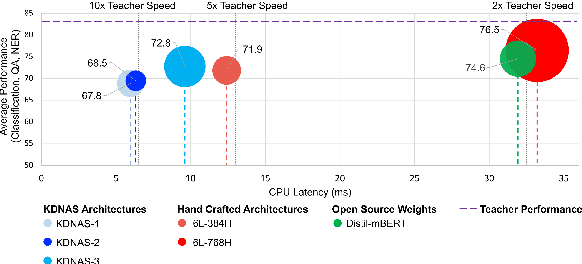

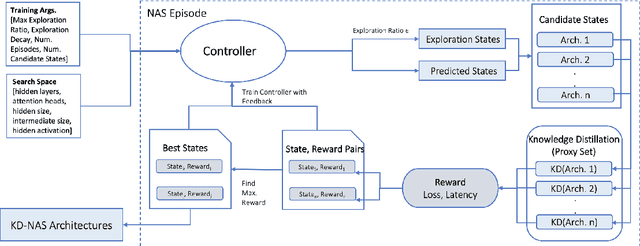
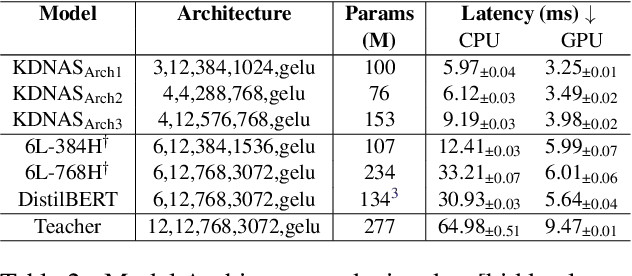
Large pre-trained language models have achieved state-of-the-art results on a variety of downstream tasks. Knowledge Distillation (KD) of a smaller student model addresses their inefficiency, allowing for deployment in resource-constraint environments. KD however remains ineffective, as the student is manually selected from a set of existing options already pre-trained on large corpora, a sub-optimal choice within the space of all possible student architectures. This paper proposes KD-NAS, the use of Neural Architecture Search (NAS) guided by the Knowledge Distillation process to find the optimal student model for distillation from a teacher, for a given natural language task. In each episode of the search process, a NAS controller predicts a reward based on a combination of accuracy on the downstream task and latency of inference. The top candidate architectures are then distilled from the teacher on a small proxy set. Finally the architecture(s) with the highest reward is selected, and distilled on the full downstream task training set. When distilling on the MNLI task, our KD-NAS model produces a 2 point improvement in accuracy on GLUE tasks with equivalent GPU latency with respect to a hand-crafted student architecture available in the literature. Using Knowledge Distillation, this model also achieves a 1.4x speedup in GPU Latency (3.2x speedup on CPU) with respect to a BERT-Base Teacher, while maintaining 97% performance on GLUE Tasks (without CoLA). We also obtain an architecture with equivalent performance as the hand-crafted student model on the GLUE benchmark, but with a 15% speedup in GPU latency (20% speedup in CPU latency) and 0.8 times the number of parameters
Sentence Identification with BOS and EOS Label Combinations
Jan 31, 2023The sentence is a fundamental unit in many NLP applications. Sentence segmentation is widely used as the first preprocessing task, where an input text is split into consecutive sentences considering the end of the sentence (EOS) as their boundaries. This task formulation relies on a strong assumption that the input text consists only of sentences, or what we call the sentential units (SUs). However, real-world texts often contain non-sentential units (NSUs) such as metadata, sentence fragments, nonlinguistic markers, etc. which are unreasonable or undesirable to be treated as a part of an SU. To tackle this issue, we formulate a novel task of sentence identification, where the goal is to identify SUs while excluding NSUs in a given text. To conduct sentence identification, we propose a simple yet effective method which combines the beginning of the sentence (BOS) and EOS labels to determine the most probable SUs and NSUs based on dynamic programming. To evaluate this task, we design an automatic, language-independent procedure to convert the Universal Dependencies corpora into sentence identification benchmarks. Finally, our experiments on the sentence identification task demonstrate that our proposed method generally outperforms sentence segmentation baselines which only utilize EOS labels.
Policy-Adaptive Estimator Selection for Off-Policy Evaluation
Nov 25, 2022



Off-policy evaluation (OPE) aims to accurately evaluate the performance of counterfactual policies using only offline logged data. Although many estimators have been developed, there is no single estimator that dominates the others, because the estimators' accuracy can vary greatly depending on a given OPE task such as the evaluation policy, number of actions, and noise level. Thus, the data-driven estimator selection problem is becoming increasingly important and can have a significant impact on the accuracy of OPE. However, identifying the most accurate estimator using only the logged data is quite challenging because the ground-truth estimation accuracy of estimators is generally unavailable. This paper studies this challenging problem of estimator selection for OPE for the first time. In particular, we enable an estimator selection that is adaptive to a given OPE task, by appropriately subsampling available logged data and constructing pseudo policies useful for the underlying estimator selection task. Comprehensive experiments on both synthetic and real-world company data demonstrate that the proposed procedure substantially improves the estimator selection compared to a non-adaptive heuristic.
Effect and Analysis of Large-scale Language Model Rescoring on Competitive ASR Systems
Apr 01, 2022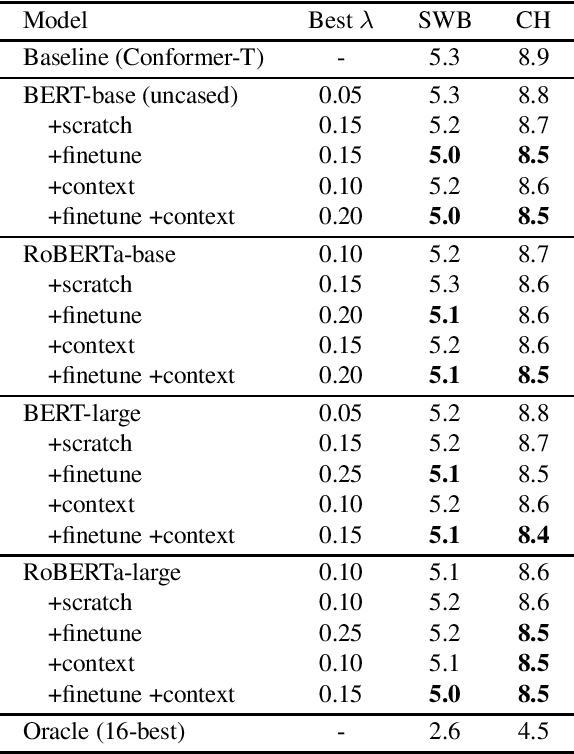
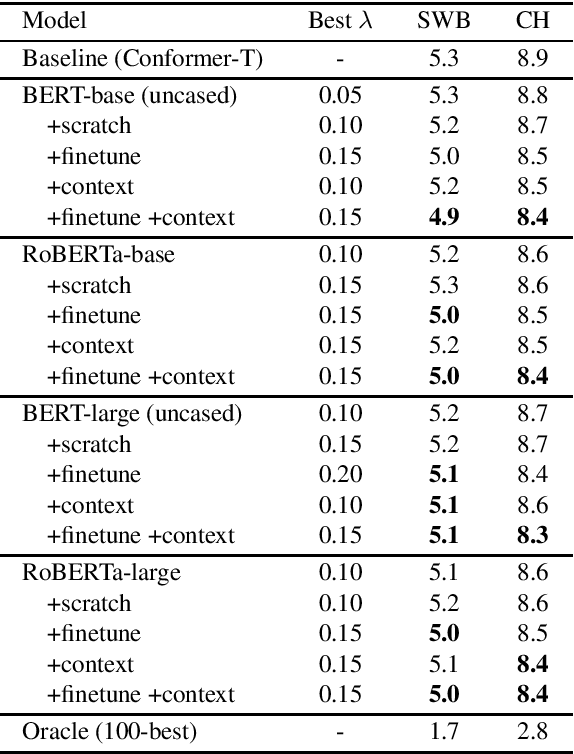
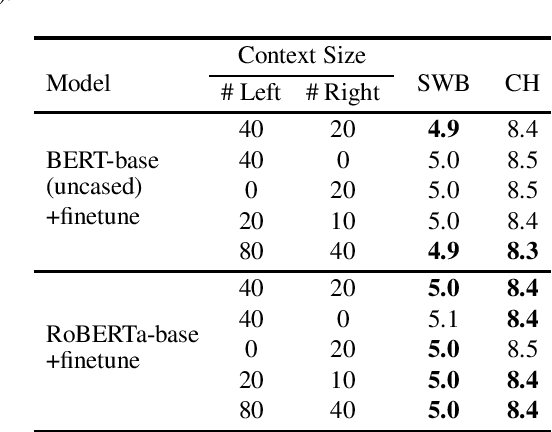
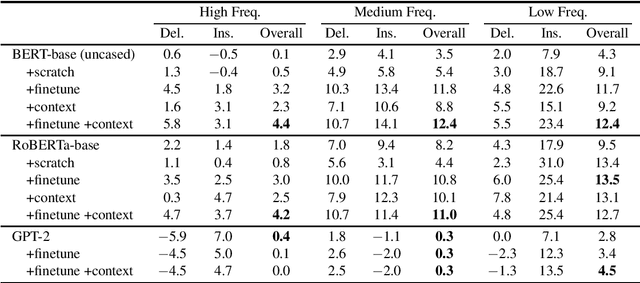
Large-scale language models (LLMs) such as GPT-2, BERT and RoBERTa have been successfully applied to ASR N-best rescoring. However, whether or how they can benefit competitive, near state-of-the-art ASR systems remains unexplored. In this study, we incorporate LLM rescoring into one of the most competitive ASR baselines: the Conformer-Transducer model. We demonstrate that consistent improvement is achieved by the LLM's bidirectionality, pretraining, in-domain finetuning and context augmentation. Furthermore, our lexical analysis sheds light on how each of these components may be contributing to the ASR performance.
Data-Driven Off-Policy Estimator Selection: An Application in User Marketing on An Online Content Delivery Service
Sep 17, 2021
Off-policy evaluation (OPE) is the method that attempts to estimate the performance of decision making policies using historical data generated by different policies without conducting costly online A/B tests. Accurate OPE is essential in domains such as healthcare, marketing or recommender systems to avoid deploying poor performing policies, as such policies may hart human lives or destroy the user experience. Thus, many OPE methods with theoretical backgrounds have been proposed. One emerging challenge with this trend is that a suitable estimator can be different for each application setting. It is often unknown for practitioners which estimator to use for their specific applications and purposes. To find out a suitable estimator among many candidates, we use a data-driven estimator selection procedure for off-policy policy performance estimators as a practical solution. As proof of concept, we use our procedure to select the best estimator to evaluate coupon treatment policies on a real-world online content delivery service. In the experiment, we first observe that a suitable estimator might change with different definitions of the outcome variable, and thus the accurate estimator selection is critical in real-world applications of OPE. Then, we demonstrate that, by utilizing the estimator selection procedure, we can easily find out suitable estimators for each purpose.