 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Contextual Bandits in the Presence of New Actions
May 18, 2026Automated decision-making algorithms drive applications such as recommendation systems and search engines. These algorithms often rely on off-policy contextual bandits or off-policy learning (OPL). Conventionally, OPL selects actions that maximize the expected reward from an existing action set. However, in many real-world scenarios, actions, such as news articles or video content, change continuously, and the action space evolves over time after data collection. We define actions introduced after deploying the logging policy as new actions and focus on OPL with new actions. Existing OPL methods identify optimal actions from the existing set effectively but cannot learn and select new actions because no relevant data are logged. To address this limitation, we propose a new OPL method that leverages action features. We first introduce the Local Combination PseudoInverse (LCPI) estimator for the policy gradient, generalizing the PseudoInverse estimator initially proposed for off-policy evaluation of slate bandits. LCPI controls the trade-off between reward-modeling condition and the condition for data collection regarding the action features, capturing the interaction effects among different dimensions of action features. Furthermore, we propose a generalized algorithm called Policy Optimization for Effective New Actions (PONA), which integrates LCPI, a component specialized for new action selection, with Doubly Robust (DR), which excels at learning within existing actions. We define PONA as a weighted sum of the LCPI and DR estimators, optimizing both the selection of existing and new actions, and allowing the proportion of new action selections to be adjusted by the weight parameter. Through extensive experiments, we demonstrate that PONA efficiently selects new actions while maintaining the overall policy performance as opposed to most existing methods that cannot select new actions.
Off-Policy Evaluation for Ranking Policies under Deterministic Logging Policies
Mar 23, 2026Off-Policy Evaluation (OPE) is an important practical problem in algorithmic ranking systems, where the goal is to estimate the expected performance of a new ranking policy using only offline logged data collected under a different, logging policy. Existing estimators, such as the ranking-wise and position-wise inverse propensity score (IPS) estimators, require the data collection policy to be sufficiently stochastic and suffer from severe bias when the logging policy is fully deterministic. In this paper, we propose novel estimators, Click-based Inverse Propensity Score (CIPS), exploiting the intrinsic stochasticity of user click behavior to address this challenge. Unlike existing methods that rely on the stochasticity of the logging policy, our approach uses click probability as a new form of importance weighting, enabling low-bias OPE even under deterministic logging policies where existing methods incur substantial bias. We provide theoretical analyses of the bias and variance properties of the proposed estimators and show, through synthetic and real-world experiments, that our estimators achieve significantly lower bias compared to strong baselines, for a range of experimental settings with completely deterministic logging policies.
LoopLens: Supporting Search as Creation in Loop-Based Music Composition
Mar 09, 2026Creativity support tools (CSTs) typically frame search as information retrieval, yet in practices like electronic dance music production, search serves as a creative medium for collage-style composition. To address this gap, we present LoopLens, a research probe for loop-based music composition that visualizes audio search results to support creative foraging and assembling. We evaluated LoopLens in a within-subject user study with 16 participants of diverse musical domain expertise, performing both open-ended (divergent) and goal-directed (convergent) tasks. Our results reveal a clear behavioral split: participants with domain expertise leveraged multimodal cues to quickly exploit a narrow set of loops, while those without domain knowledge relied primarily on audio impressions, engaging in broad exploration often constrained by limited musical vocabulary for query formulation. This behavioral dichotomy provides a new lens for understanding the balance between exploration and exploitation in creative search and offers clear design implications for supporting vocabulary-independent discovery in future CSTs.
Policy-Adaptive Estimator Selection for Off-Policy Evaluation
Nov 25, 2022



Off-policy evaluation (OPE) aims to accurately evaluate the performance of counterfactual policies using only offline logged data. Although many estimators have been developed, there is no single estimator that dominates the others, because the estimators' accuracy can vary greatly depending on a given OPE task such as the evaluation policy, number of actions, and noise level. Thus, the data-driven estimator selection problem is becoming increasingly important and can have a significant impact on the accuracy of OPE. However, identifying the most accurate estimator using only the logged data is quite challenging because the ground-truth estimation accuracy of estimators is generally unavailable. This paper studies this challenging problem of estimator selection for OPE for the first time. In particular, we enable an estimator selection that is adaptive to a given OPE task, by appropriately subsampling available logged data and constructing pseudo policies useful for the underlying estimator selection task. Comprehensive experiments on both synthetic and real-world company data demonstrate that the proposed procedure substantially improves the estimator selection compared to a non-adaptive heuristic.
Data-Driven Off-Policy Estimator Selection: An Application in User Marketing on An Online Content Delivery Service
Sep 17, 2021
Off-policy evaluation (OPE) is the method that attempts to estimate the performance of decision making policies using historical data generated by different policies without conducting costly online A/B tests. Accurate OPE is essential in domains such as healthcare, marketing or recommender systems to avoid deploying poor performing policies, as such policies may hart human lives or destroy the user experience. Thus, many OPE methods with theoretical backgrounds have been proposed. One emerging challenge with this trend is that a suitable estimator can be different for each application setting. It is often unknown for practitioners which estimator to use for their specific applications and purposes. To find out a suitable estimator among many candidates, we use a data-driven estimator selection procedure for off-policy policy performance estimators as a practical solution. As proof of concept, we use our procedure to select the best estimator to evaluate coupon treatment policies on a real-world online content delivery service. In the experiment, we first observe that a suitable estimator might change with different definitions of the outcome variable, and thus the accurate estimator selection is critical in real-world applications of OPE. Then, we demonstrate that, by utilizing the estimator selection procedure, we can easily find out suitable estimators for each purpose.
Evaluating the Robustness of Off-Policy Evaluation
Aug 31, 2021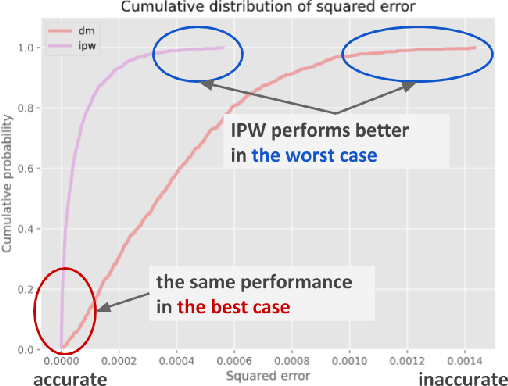


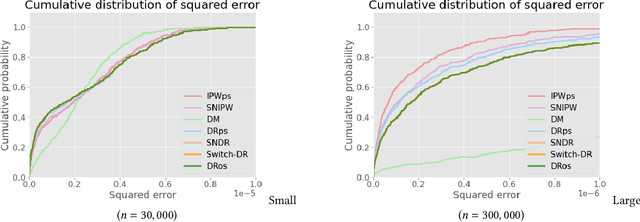
Off-policy Evaluation (OPE), or offline evaluation in general, evaluates the performance of hypothetical policies leveraging only offline log data. It is particularly useful in applications where the online interaction involves high stakes and expensive setting such as precision medicine and recommender systems. Since many OPE estimators have been proposed and some of them have hyperparameters to be tuned, there is an emerging challenge for practitioners to select and tune OPE estimators for their specific application. Unfortunately, identifying a reliable estimator from results reported in research papers is often difficult because the current experimental procedure evaluates and compares the estimators' performance on a narrow set of hyperparameters and evaluation policies. Therefore, it is difficult to know which estimator is safe and reliable to use. In this work, we develop Interpretable Evaluation for Offline Evaluation (IEOE), an experimental procedure to evaluate OPE estimators' robustness to changes in hyperparameters and/or evaluation policies in an interpretable manner. Then, using the IEOE procedure, we perform extensive evaluation of a wide variety of existing estimators on Open Bandit Dataset, a large-scale public real-world dataset for OPE. We demonstrate that our procedure can evaluate the estimators' robustness to the hyperparamter choice, helping us avoid using unsafe estimators. Finally, we apply IEOE to real-world e-commerce platform data and demonstrate how to use our protocol in practice.