 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Evaluation of Ranking Policies under Diverse User Behavior
Jun 26, 2023Ranking interfaces are everywhere in online platforms. There is thus an ever growing interest in their Off-Policy Evaluation (OPE), aiming towards an accurate performance evaluation of ranking policies using logged data. A de-facto approach for OPE is Inverse Propensity Scoring (IPS), which provides an unbiased and consistent value estimate. However, it becomes extremely inaccurate in the ranking setup due to its high variance under large action spaces. To deal with this problem, previous studies assume either independent or cascade user behavior, resulting in some ranking versions of IPS. While these estimators are somewhat effective in reducing the variance, all existing estimators apply a single universal assumption to every user, causing excessive bias and variance. Therefore, this work explores a far more general formulation where user behavior is diverse and can vary depending on the user context. We show that the resulting estimator, which we call Adaptive IPS (AIPS), can be unbiased under any complex user behavior. Moreover, AIPS achieves the minimum variance among all unbiased estimators based on IPS. We further develop a procedure to identify the appropriate user behavior model to minimize the mean squared error (MSE) of AIPS in a data-driven fashion. Extensive experiments demonstrate that the empirical accuracy improvement can be significant, enabling effective OPE of ranking systems even under diverse user behavior.
Counterfactual Learning with General Data-generating Policies
Dec 04, 2022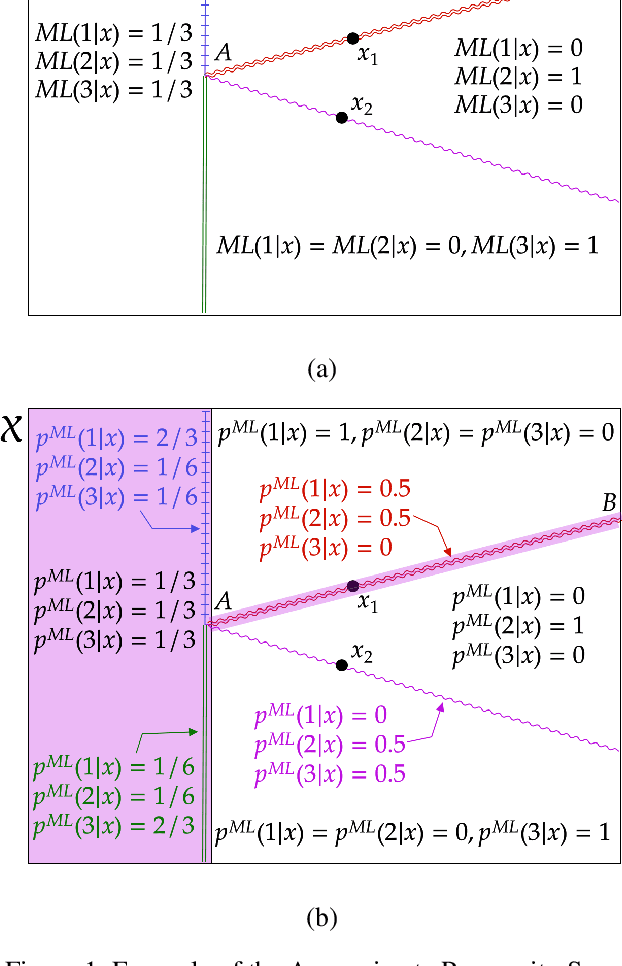
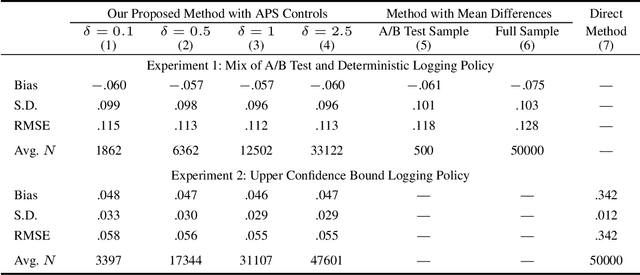
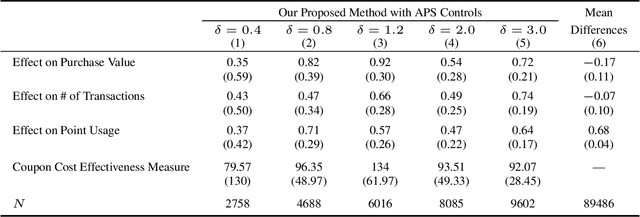
Off-policy evaluation (OPE) attempts to predict the performance of counterfactual policies using log data from a different policy. We extend its applicability by developing an OPE method for a class of both full support and deficient support logging policies in contextual-bandit settings. This class includes deterministic bandit (such as Upper Confidence Bound) as well as deterministic decision-making based on supervised and unsupervised learning. We prove that our method's prediction converges in probability to the true performance of a counterfactual policy as the sample size increases. We validate our method with experiments on partly and entirely deterministic logging policies. Finally, we apply it to evaluate coupon targeting policies by a major online platform and show how to improve the existing policy.
Policy-Adaptive Estimator Selection for Off-Policy Evaluation
Nov 25, 2022



Off-policy evaluation (OPE) aims to accurately evaluate the performance of counterfactual policies using only offline logged data. Although many estimators have been developed, there is no single estimator that dominates the others, because the estimators' accuracy can vary greatly depending on a given OPE task such as the evaluation policy, number of actions, and noise level. Thus, the data-driven estimator selection problem is becoming increasingly important and can have a significant impact on the accuracy of OPE. However, identifying the most accurate estimator using only the logged data is quite challenging because the ground-truth estimation accuracy of estimators is generally unavailable. This paper studies this challenging problem of estimator selection for OPE for the first time. In particular, we enable an estimator selection that is adaptive to a given OPE task, by appropriately subsampling available logged data and constructing pseudo policies useful for the underlying estimator selection task. Comprehensive experiments on both synthetic and real-world company data demonstrate that the proposed procedure substantially improves the estimator selection compared to a non-adaptive heuristic.
Doubly Robust Off-Policy Evaluation for Ranking Policies under the Cascade Behavior Model
Feb 03, 2022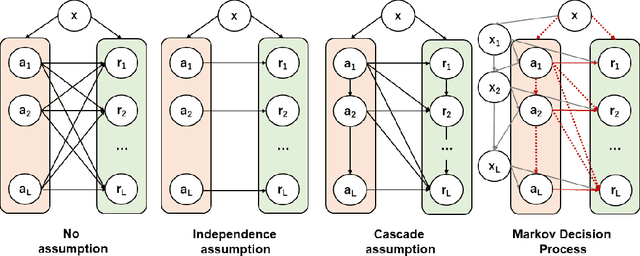
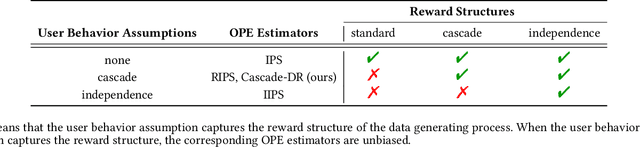

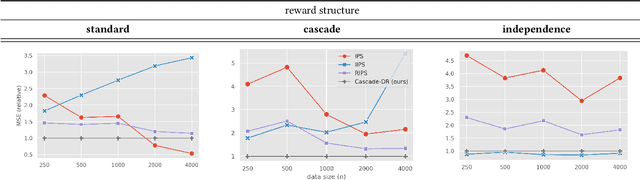
In real-world recommender systems and search engines, optimizing ranking decisions to present a ranked list of relevant items is critical. Off-policy evaluation (OPE) for ranking policies is thus gaining a growing interest because it enables performance estimation of new ranking policies using only logged data. Although OPE in contextual bandits has been studied extensively, its naive application to the ranking setting faces a critical variance issue due to the huge item space. To tackle this problem, previous studies introduce some assumptions on user behavior to make the combinatorial item space tractable. However, an unrealistic assumption may, in turn, cause serious bias. Therefore, appropriately controlling the bias-variance tradeoff by imposing a reasonable assumption is the key for success in OPE of ranking policies. To achieve a well-balanced bias-variance tradeoff, we propose the Cascade Doubly Robust estimator building on the cascade assumption, which assumes that a user interacts with items sequentially from the top position in a ranking. We show that the proposed estimator is unbiased in more cases compared to existing estimators that make stronger assumptions. Furthermore, compared to a previous estimator based on the same cascade assumption, the proposed estimator reduces the variance by leveraging a control variate. Comprehensive experiments on both synthetic and real-world data demonstrate that our estimator leads to more accurate OPE than existing estimators in a variety of settings.
Evaluating the Robustness of Off-Policy Evaluation
Aug 31, 2021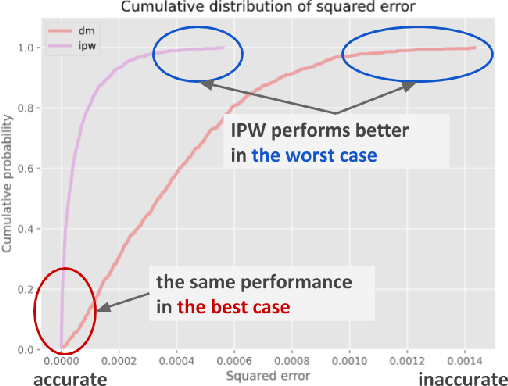


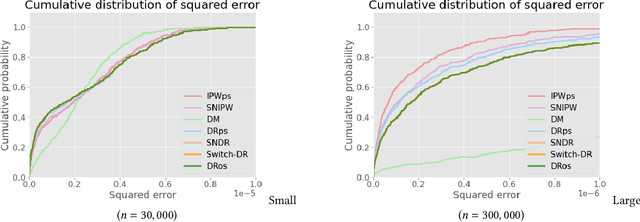
Off-policy Evaluation (OPE), or offline evaluation in general, evaluates the performance of hypothetical policies leveraging only offline log data. It is particularly useful in applications where the online interaction involves high stakes and expensive setting such as precision medicine and recommender systems. Since many OPE estimators have been proposed and some of them have hyperparameters to be tuned, there is an emerging challenge for practitioners to select and tune OPE estimators for their specific application. Unfortunately, identifying a reliable estimator from results reported in research papers is often difficult because the current experimental procedure evaluates and compares the estimators' performance on a narrow set of hyperparameters and evaluation policies. Therefore, it is difficult to know which estimator is safe and reliable to use. In this work, we develop Interpretable Evaluation for Offline Evaluation (IEOE), an experimental procedure to evaluate OPE estimators' robustness to changes in hyperparameters and/or evaluation policies in an interpretable manner. Then, using the IEOE procedure, we perform extensive evaluation of a wide variety of existing estimators on Open Bandit Dataset, a large-scale public real-world dataset for OPE. We demonstrate that our procedure can evaluate the estimators' robustness to the hyperparamter choice, helping us avoid using unsafe estimators. Finally, we apply IEOE to real-world e-commerce platform data and demonstrate how to use our protocol in practice.
Algorithm is Experiment: Machine Learning, Market Design, and Policy Eligibility Rules
Apr 26, 2021


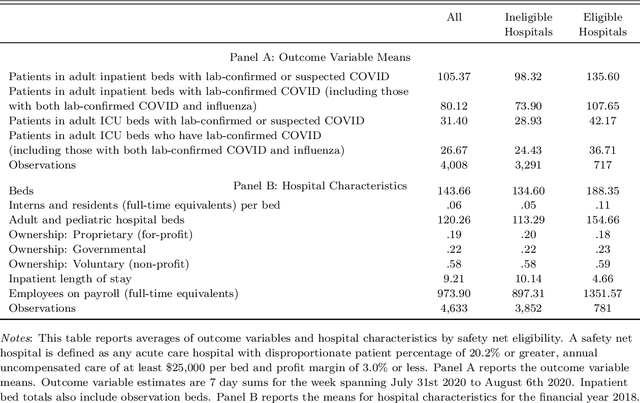
Algorithms produce a growing portion of decisions and recommendations both in policy and business. Such algorithmic decisions are natural experiments (conditionally quasi-randomly assigned instruments) since the algorithms make decisions based only on observable input variables. We use this observation to develop a treatment-effect estimator for a class of stochastic and deterministic algorithms. Our estimator is shown to be consistent and asymptotically normal for well-defined causal effects. A key special case of our estimator is a high-dimensional regression discontinuity design. The proofs use tools from differential geometry and geometric measure theory, which may be of independent interest. The practical performance of our method is first demonstrated in a high-dimensional simulation resembling decision-making by machine learning algorithms. Our estimator has smaller mean squared errors compared to alternative estimators. We finally apply our estimator to evaluate the effect of Coronavirus Aid, Relief, and Economic Security (CARES) Act, where more than \$10 billion worth of relief funding is allocated to hospitals via an algorithmic rule. The estimates suggest that the relief funding has little effects on COVID-19-related hospital activity levels. Naive OLS and IV estimates exhibit substantial selection bias.
A Large-scale Open Dataset for Bandit Algorithms
Aug 17, 2020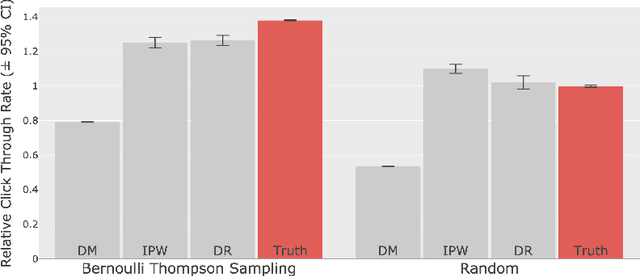

We build and publicize the Open Bandit Dataset and Pipeline to facilitate scalable and reproducible research on bandit algorithms. They are especially suitable for off-policy evaluation (OPE), which attempts to predict the performance of hypothetical algorithms using data generated by a different algorithm. We construct the dataset based on experiments and implementations on a large-scale fashion e-commerce platform, ZOZOTOWN. The data contain the ground-truth about the performance of several bandit policies and enable the fair comparisons of different OPE estimators. We also provide a pipeline to make its implementation easy and consistent. As a proof of concept, we use the dataset and pipeline to implement and evaluate OPE estimators. First, we find that a well-established estimator fails, suggesting that it is critical to choose an appropriate estimator. We then select a well-performing estimator and use it to improve the platform's fashion item recommendation. Our analysis succeeds in finding a counterfactual policy that significantly outperforms the historical ones. Our open data and pipeline will allow researchers and practitioners to easily evaluate and compare their bandit algorithms and OPE estimators with others in a large, real-world setting.
Safe Counterfactual Reinforcement Learning
Feb 20, 2020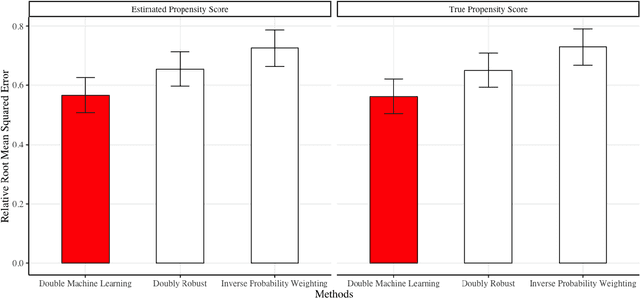


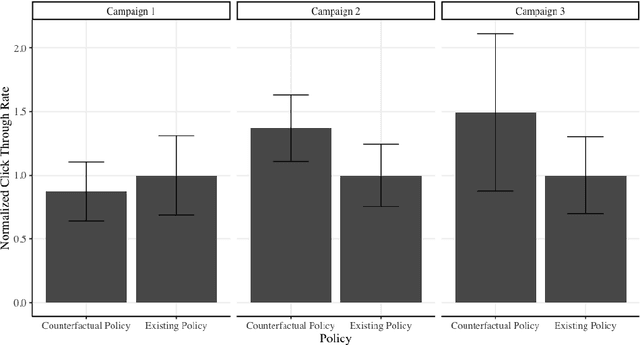
We develop a method for predicting the performance of reinforcement learning and bandit algorithms, given historical data that may have been generated by a different algorithm. Our estimator has the property that its prediction converges in probability to the true performance of a counterfactual algorithm at the fast $\sqrt{N}$ rate, as the sample size $N$ increases. We also show a correct way to estimate the variance of our prediction, thus allowing the analyst to quantify the uncertainty in the prediction. These properties hold even when the analyst does not know which among a large number of potentially important state variables are really important. These theoretical guarantees make our estimator safe to use. We finally apply it to improve advertisement design by a major advertisement company. We find that our method produces smaller mean squared errors than state-of-the-art methods.
Adaptive Experimental Design for Efficient Treatment Effect Estimation: Randomized Allocation via Contextual Bandit Algorithm
Feb 13, 2020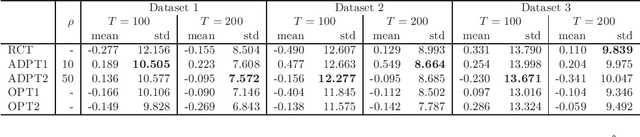
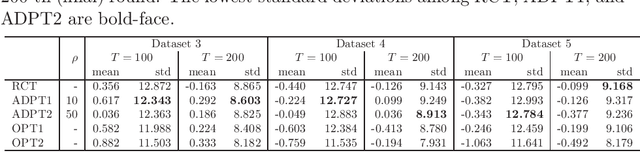


Many scientific experiments have an interest in the estimation of the average treatment effect (ATE), which is defined as the difference between the expected outcomes of two or more treatments. In this paper, we consider a situation called adaptive experimental design where research subjects sequentially visit a researcher, and the researcher assigns a treatment. For estimating the ATE efficiently, we consider changing the probability of assigning a treatment at a period by using past information obtained until the period. However, in this approach, it is difficult to apply the standard statistical method to construct an estimator because the observations are not independent and identically distributed. In this paper, to construct an efficient estimator, we overcome this conventional problem by using an algorithm of the multi-armed bandit problem and the theory of martingale. In the proposed method, we use the probability of assigning a treatment that minimizes the asymptotic variance of an estimator of the ATE. We also elucidate the theoretical properties of an estimator obtained from the proposed algorithm for both infinite and finite samples. Finally, we experimentally show that the proposed algorithm outperforms the standard RCT in some cases.
Efficient Counterfactual Learning from Bandit Feedback
Sep 10, 2018

What is the most statistically efficient way to do off-policy evaluation and optimization with batch data from bandit feedback? For log data generated by contextual bandit algorithms, we consider offline estimators for the expected reward from a counterfactual policy. Our estimators are shown to have lowest variance in a wide class of estimators, achieving variance reduction relative to standard estimators. We also apply our estimators to improve online advertisement design by a major advertisement company. Consistent with the theoretical result, our estimators allow us to improve on the existing bandit algorithm with more statistical confidence compared to a state-of-the-art benchmark.