 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-scale Open Dataset for Bandit Algorithms
Aug 17, 2020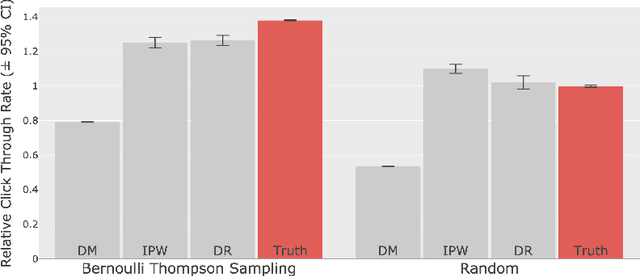

We build and publicize the Open Bandit Dataset and Pipeline to facilitate scalable and reproducible research on bandit algorithms. They are especially suitable for off-policy evaluation (OPE), which attempts to predict the performance of hypothetical algorithms using data generated by a different algorithm. We construct the dataset based on experiments and implementations on a large-scale fashion e-commerce platform, ZOZOTOWN. The data contain the ground-truth about the performance of several bandit policies and enable the fair comparisons of different OPE estimators. We also provide a pipeline to make its implementation easy and consistent. As a proof of concept, we use the dataset and pipeline to implement and evaluate OPE estimators. First, we find that a well-established estimator fails, suggesting that it is critical to choose an appropriate estimator. We then select a well-performing estimator and use it to improve the platform's fashion item recommendation. Our analysis succeeds in finding a counterfactual policy that significantly outperforms the historical ones. Our open data and pipeline will allow researchers and practitioners to easily evaluate and compare their bandit algorithms and OPE estimators with others in a large, real-world setting.
Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention
Oct 24, 2017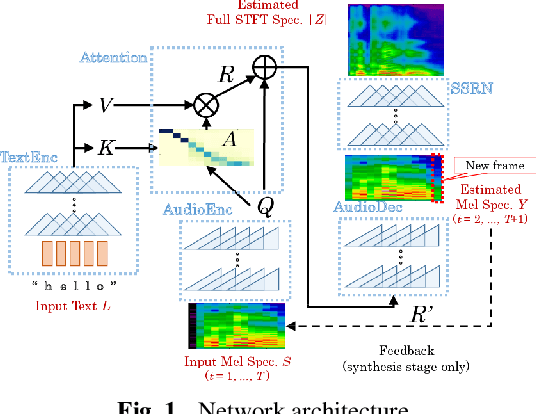
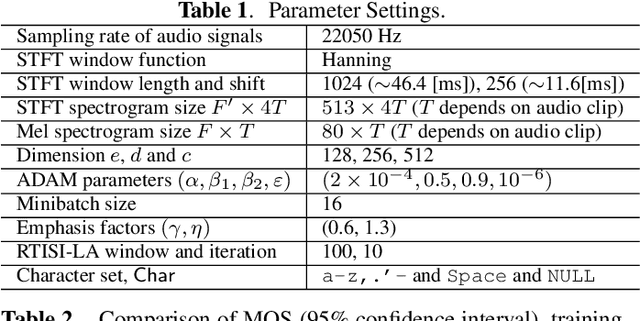

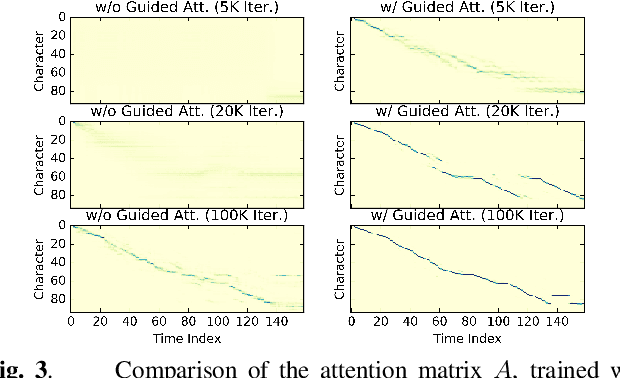
This paper describes a novel text-to-speech (TTS) technique based on deep convolutional neural networks (CNN), without any recurrent units. Recurrent neural network (RNN) has been a standard technique to model sequential data recently, and this technique has been used in some cutting-edge neural TTS techniques. However, training RNN component often requires a very powerful computer, or very long time typically several days or weeks. Recent other studies, on the other hand, have shown that CNN-based sequence synthesis can be much faster than RNN-based techniques, because of high parallelizability. The objective of this paper is to show an alternative neural TTS system, based only on CNN, that can alleviate these economic costs of training. In our experiment, the proposed Deep Convolutional TTS can be sufficiently trained only in a night (15 hours), using an ordinary gaming PC equipped with two GPUs, while the quality of the synthesized speech was almost acceptable.