 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention
Oct 24, 2017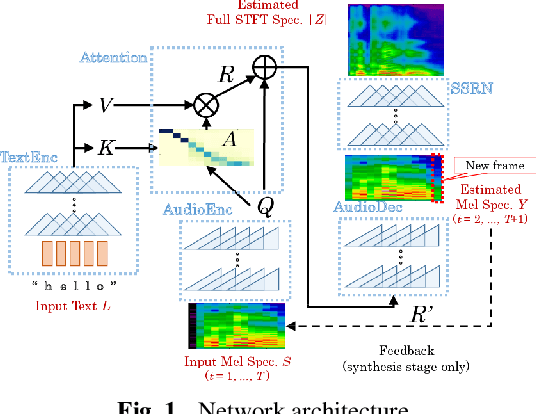
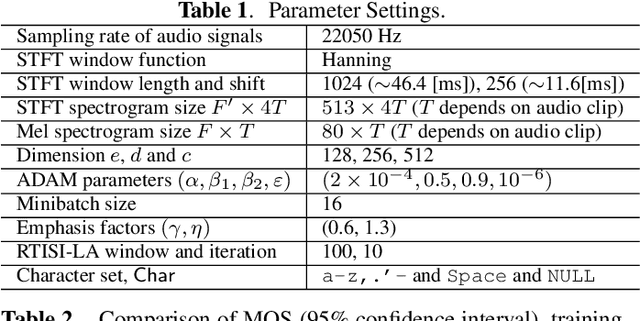

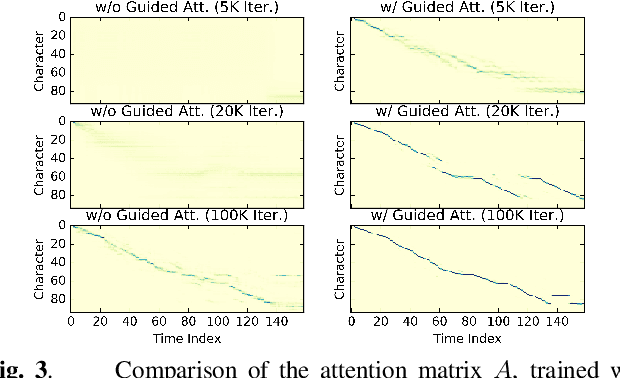
This paper describes a novel text-to-speech (TTS) technique based on deep convolutional neural networks (CNN), without any recurrent units. Recurrent neural network (RNN) has been a standard technique to model sequential data recently, and this technique has been used in some cutting-edge neural TTS techniques. However, training RNN component often requires a very powerful computer, or very long time typically several days or weeks. Recent other studies, on the other hand, have shown that CNN-based sequence synthesis can be much faster than RNN-based techniques, because of high parallelizability. The objective of this paper is to show an alternative neural TTS system, based only on CNN, that can alleviate these economic costs of training. In our experiment, the proposed Deep Convolutional TTS can be sufficiently trained only in a night (15 hours), using an ordinary gaming PC equipped with two GPUs, while the quality of the synthesized speech was almost acceptable.