 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIS Reasoning 1.0: The First Large-Scale Japanese Benchmark for Belief-Inconsistent Syllogistic Reasoning
Jun 08, 2025We present BIS Reasoning 1.0, the first large-scale Japanese dataset of syllogistic reasoning problems explicitly designed to evaluate belief-inconsistent reasoning in large language models (LLMs). Unlike prior datasets such as NeuBAROCO and JFLD, which focus on general or belief-aligned reasoning, BIS Reasoning 1.0 introduces logically valid yet belief-inconsistent syllogisms to uncover reasoning biases in LLMs trained on human-aligned corpora. We benchmark state-of-the-art models - including GPT models, Claude models, and leading Japanese LLMs - revealing significant variance in performance, with GPT-4o achieving 79.54% accuracy. Our analysis identifies critical weaknesses in current LLMs when handling logically valid but belief-conflicting inputs. These findings have important implications for deploying LLMs in high-stakes domains such as law, healthcare, and scientific literature, where truth must override intuitive belief to ensure integrity and safety.
RAD: Redundancy-Aware Distillation for Hybrid Models via Self-Speculative Decoding
May 28, 2025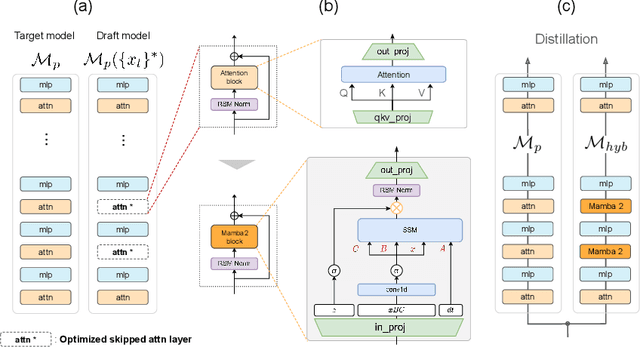
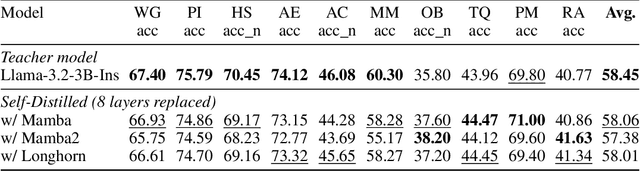
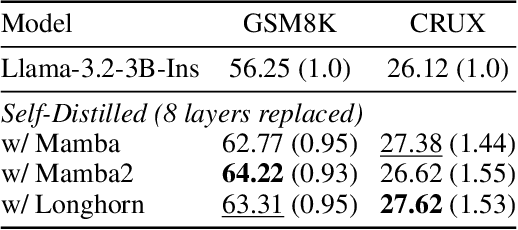
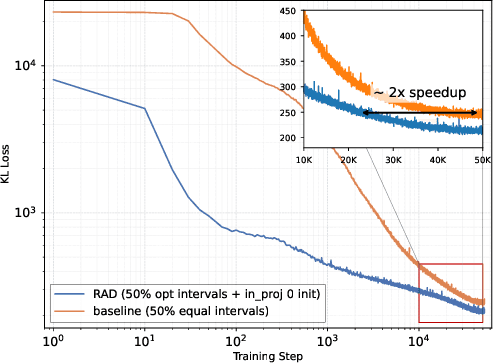
Hybrid models combining Transformers and State Space Models (SSMs) are promising for balancing performance and efficiency. However, optimizing these hybrid models, particularly by addressing the potential redundancy inherent within the Transformer components, remains a significant challenge. In this paper, we propose RAD (Redundancy-Aware Distillation), a novel framework that uses self-speculative decoding as a diagnostic tool to identify redundant attention layers within the model. These identified layers are then selectively replaced with SSM components, followed by targeted (self-)distillation. Specifically, RAD focuses knowledge transfer on the components identified as redundant, considering architectural changes and specific weight initialization strategies. We experimentally demonstrate that self-distillation using RAD significantly surpasses the performance of the original base model on mathematical and coding tasks. Furthermore, RAD is also effective in standard knowledge distillation settings, achieving up to approximately 2x faster convergence compared to baseline methods. Notably, while a baseline model distilled from a Llama-3.1 70B teacher achieves scores of 46.17 on GSM8K and 22.75 on CRUX, RAD achieves significantly higher scores of 71.27 on GSM8K and 28.25 on CRUX, even when using a much smaller Llama-3.1 8B teacher. RAD offers a new pathway for efficient optimization and performance enhancement in the distillation of hybrid models.
Multilingual Sentence-T5: Scalable Sentence Encoders for Multilingual Applications
Mar 26, 2024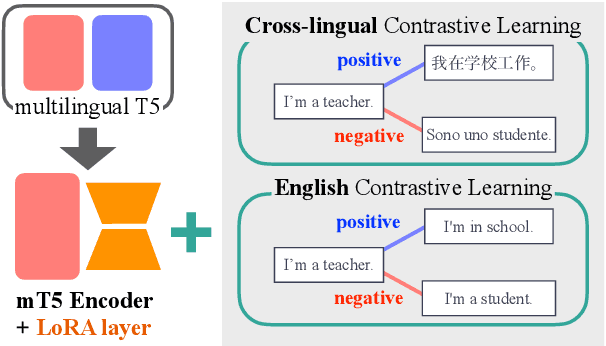
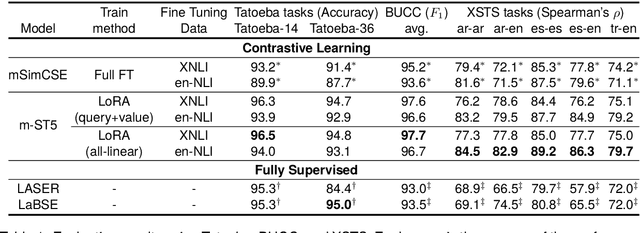
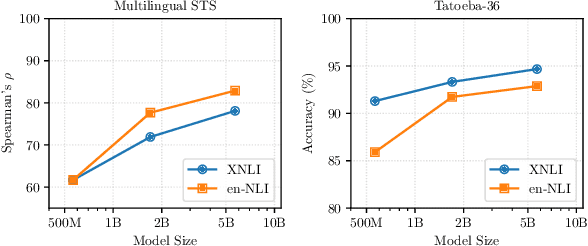
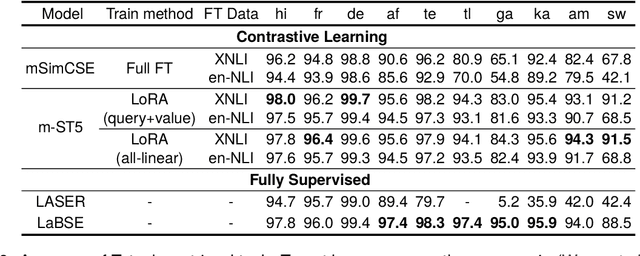
Prior work on multilingual sentence embedding has demonstrated that the efficient use of natural language inference (NLI) data to build high-performance models can outperform conventional methods. However, the potential benefits from the recent ``exponential'' growth of language models with billions of parameters have not yet been fully explored. In this paper, we introduce Multilingual Sentence T5 (m-ST5), as a larger model of NLI-based multilingual sentence embedding, by extending Sentence T5, an existing monolingual model. By employing the low-rank adaptation (LoRA) technique, we have achieved a successful scaling of the model's size to 5.7 billion parameters. We conducted experiments to evaluate the performance of sentence embedding and verified that the method outperforms the NLI-based prior approach. Furthermore, we also have confirmed a positive correlation between the size of the model and its performance. It was particularly noteworthy that languages with fewer resources or those with less linguistic similarity to English benefited more from the parameter increase. Our model is available at https://huggingface.co/pkshatech/m-ST5.
gSwin: Gated MLP Vision Model with Hierarchical Structure of Shifted Window
Aug 24, 2022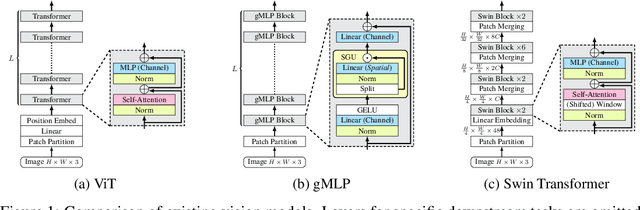
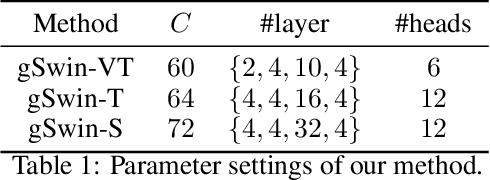

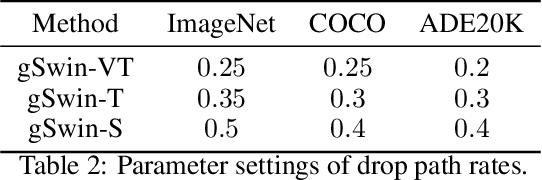
Following the success in language domain, the self-attention mechanism (transformer) is adopted in the vision domain and achieving great success recently. Additionally, as another stream, multi-layer perceptron (MLP) is also explored in the vision domain. These architectures, other than traditional CNNs, have been attracting attention recently, and many methods have been proposed. As one that combines parameter efficiency and performance with locality and hierarchy in image recognition, we propose gSwin, which merges the two streams; Swin Transformer and (multi-head) gMLP. We showed that our gSwin can achieve better accuracy on three vision tasks, image classification, object detection and semantic segmentation, than Swin Transformer, with smaller model size.
Itô-Taylor Sampling Scheme for Denoising Diffusion Probabilistic Models using Ideal Derivatives
Dec 26, 2021


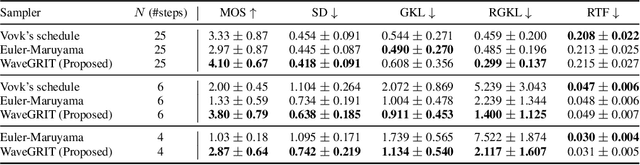
Denoising Diffusion Probabilistic Models (DDPMs) have been attracting attention recently as a new challenger to popular deep neural generative models including GAN, VAE, etc. However, DDPMs have a disadvantage that they often require a huge number of refinement steps during the synthesis. To address this problem, this paper proposes a new DDPM sampler based on a second-order numerical scheme for stochastic differential equations (SDEs), while the conventional sampler is based on a first-order numerical scheme. In general, it is not easy to compute the derivatives that are required in higher-order numerical schemes. However, in the case of DDPM, this difficulty is alleviated by the trick which the authors call "ideal derivative substitution". The newly derived higher-order sampler was applied to both image and speech generation tasks, and it is experimentally observed that the proposed sampler could synthesize plausible images and audio signals in relatively smaller number of refinement steps.
Towards Listening to 10 People Simultaneously: An Efficient Permutation Invariant Training of Audio Source Separation Using Sinkhorn's Algorithm
Oct 22, 2020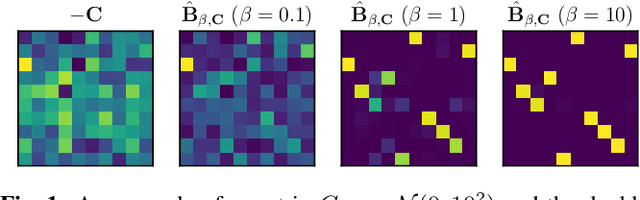

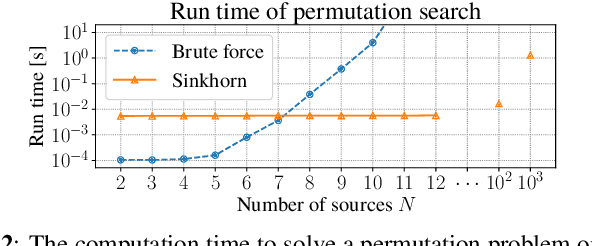
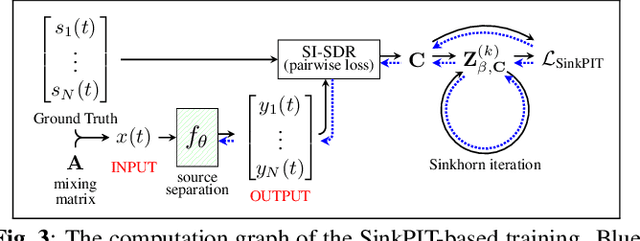
In neural network-based monaural speech separation techniques, it has been recently common to evaluate the loss using the permutation invariant training (PIT) loss. However, the ordinary PIT requires to try all $N!$ permutations between $N$ ground truths and $N$ estimates. Since the factorial complexity explodes very rapidly as $N$ increases, a PIT-based training works only when the number of source signals is small, such as $N = 2$ or $3$. To overcome this limitation, this paper proposes a SinkPIT, a novel variant of the PIT losses, which is much more efficient than the ordinary PIT loss when $N$ is large. The SinkPIT is based on Sinkhorn's matrix balancing algorithm, which efficiently finds a doubly stochastic matrix which approximates the best permutation in a differentiable manner. The author conducted an experiment to train a neural network model to decompose a single-channel mixture into 10 sources using the SinkPIT, and obtained promising results.
Accent Estimation of Japanese Words from Their Surfaces and Romanizations for Building Large Vocabulary Accent Dictionaries
Sep 21, 2020

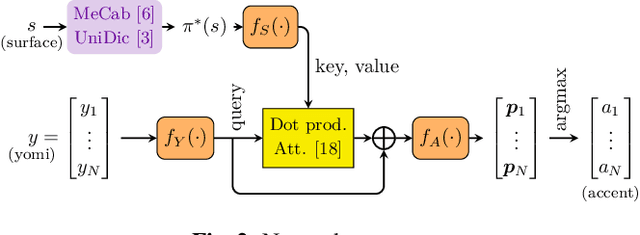
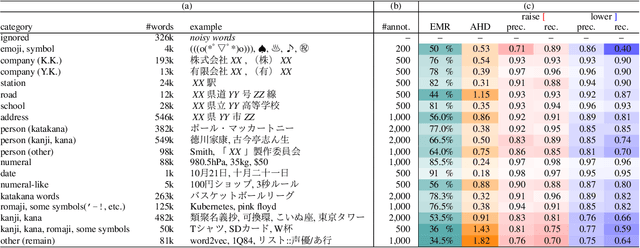
In Japanese text-to-speech (TTS), it is necessary to add accent information to the input sentence. However, there are a limited number of publicly available accent dictionaries, and those dictionaries e.g. UniDic, do not contain many compound words, proper nouns, etc., which are required in a practical TTS system. In order to build a large scale accent dictionary that contains those words, the authors developed an accent estimation technique that predicts the accent of a word from its limited information, namely the surface (e.g. kanji) and the yomi (simplified phonetic information). It is experimentally shown that the technique can estimate accents with high accuracies, especially for some categories of words. The authors applied this technique to an existing large vocabulary Japanese dictionary NEologd, and obtained a large vocabulary Japanese accent dictionary. Many cases have been observed in which the use of this dictionary yields more appropriate phonetic information than UniDic.
* 7 pages, 2 figures. IEEE ICASSP 2020
Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention
Oct 24, 2017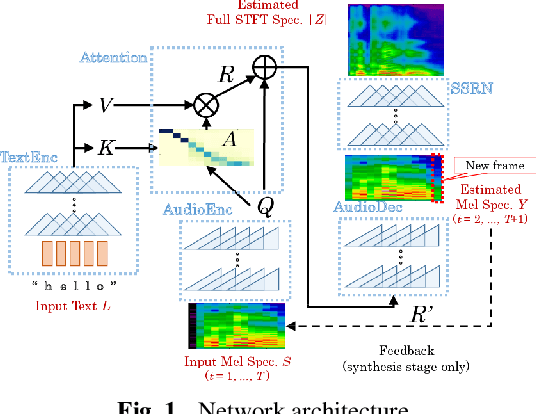
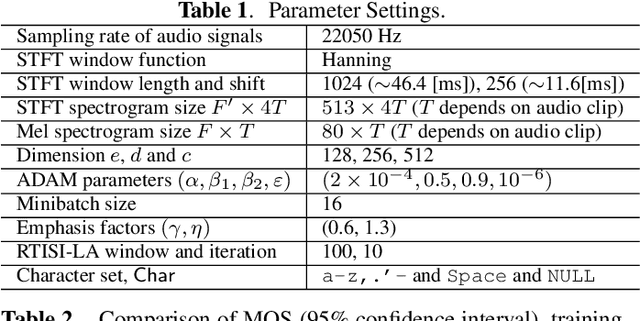

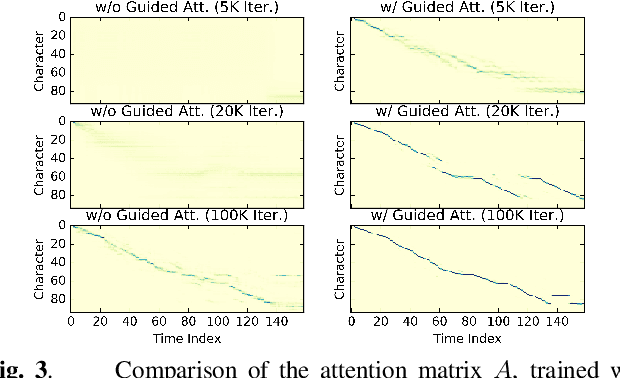
This paper describes a novel text-to-speech (TTS) technique based on deep convolutional neural networks (CNN), without any recurrent units. Recurrent neural network (RNN) has been a standard technique to model sequential data recently, and this technique has been used in some cutting-edge neural TTS techniques. However, training RNN component often requires a very powerful computer, or very long time typically several days or weeks. Recent other studies, on the other hand, have shown that CNN-based sequence synthesis can be much faster than RNN-based techniques, because of high parallelizability. The objective of this paper is to show an alternative neural TTS system, based only on CNN, that can alleviate these economic costs of training. In our experiment, the proposed Deep Convolutional TTS can be sufficiently trained only in a night (15 hours), using an ordinary gaming PC equipped with two GPUs, while the quality of the synthesized speech was almost acceptable.