 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccent Estimation of Japanese Words from Their Surfaces and Romanizations for Building Large Vocabulary Accent Dictionaries
Paper and Code


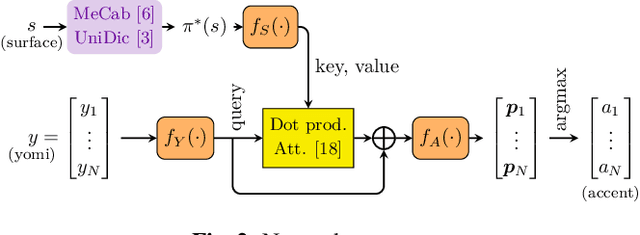
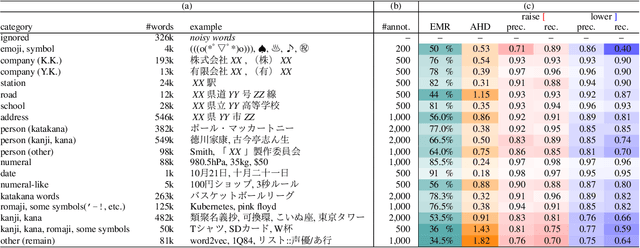
In Japanese text-to-speech (TTS), it is necessary to add accent information to the input sentence. However, there are a limited number of publicly available accent dictionaries, and those dictionaries e.g. UniDic, do not contain many compound words, proper nouns, etc., which are required in a practical TTS system. In order to build a large scale accent dictionary that contains those words, the authors developed an accent estimation technique that predicts the accent of a word from its limited information, namely the surface (e.g. kanji) and the yomi (simplified phonetic information). It is experimentally shown that the technique can estimate accents with high accuracies, especially for some categories of words. The authors applied this technique to an existing large vocabulary Japanese dictionary NEologd, and obtained a large vocabulary Japanese accent dictionary. Many cases have been observed in which the use of this dictionary yields more appropriate phonetic information than UniDic.