 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeItô-Taylor Sampling Scheme for Denoising Diffusion Probabilistic Models using Ideal Derivatives
Dec 26, 2021


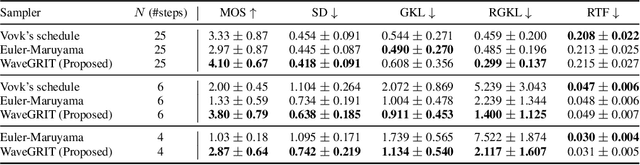
Denoising Diffusion Probabilistic Models (DDPMs) have been attracting attention recently as a new challenger to popular deep neural generative models including GAN, VAE, etc. However, DDPMs have a disadvantage that they often require a huge number of refinement steps during the synthesis. To address this problem, this paper proposes a new DDPM sampler based on a second-order numerical scheme for stochastic differential equations (SDEs), while the conventional sampler is based on a first-order numerical scheme. In general, it is not easy to compute the derivatives that are required in higher-order numerical schemes. However, in the case of DDPM, this difficulty is alleviated by the trick which the authors call "ideal derivative substitution". The newly derived higher-order sampler was applied to both image and speech generation tasks, and it is experimentally observed that the proposed sampler could synthesize plausible images and audio signals in relatively smaller number of refinement steps.
Accent Estimation of Japanese Words from Their Surfaces and Romanizations for Building Large Vocabulary Accent Dictionaries
Sep 21, 2020

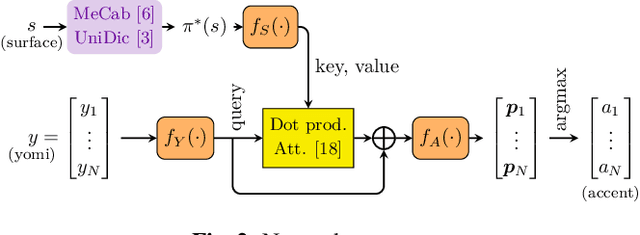
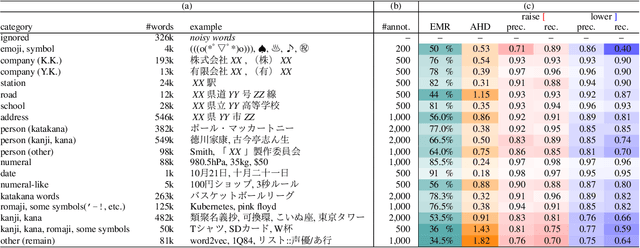
In Japanese text-to-speech (TTS), it is necessary to add accent information to the input sentence. However, there are a limited number of publicly available accent dictionaries, and those dictionaries e.g. UniDic, do not contain many compound words, proper nouns, etc., which are required in a practical TTS system. In order to build a large scale accent dictionary that contains those words, the authors developed an accent estimation technique that predicts the accent of a word from its limited information, namely the surface (e.g. kanji) and the yomi (simplified phonetic information). It is experimentally shown that the technique can estimate accents with high accuracies, especially for some categories of words. The authors applied this technique to an existing large vocabulary Japanese dictionary NEologd, and obtained a large vocabulary Japanese accent dictionary. Many cases have been observed in which the use of this dictionary yields more appropriate phonetic information than UniDic.
* 7 pages, 2 figures. IEEE ICASSP 2020