 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Sentence-T5: Scalable Sentence Encoders for Multilingual Applications
Mar 26, 2024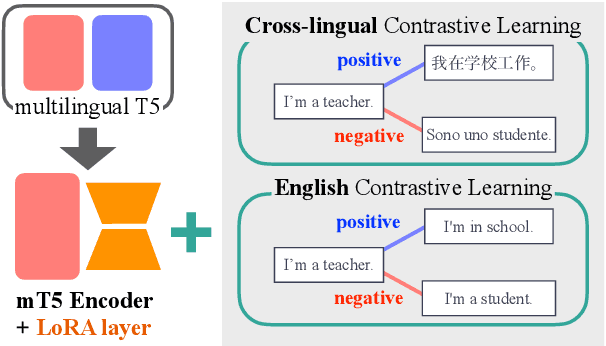
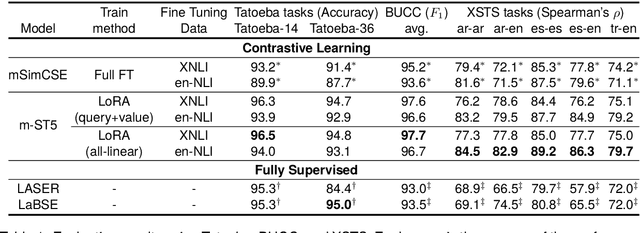
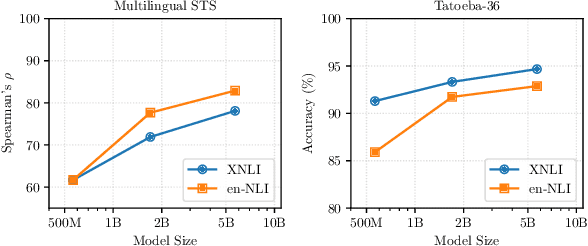
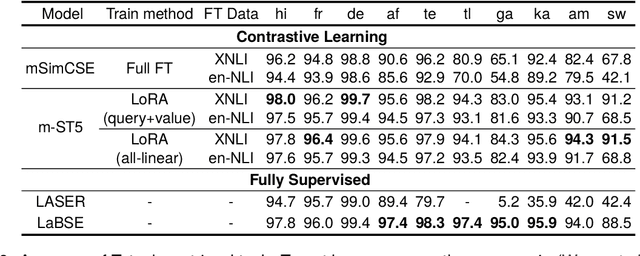
Prior work on multilingual sentence embedding has demonstrated that the efficient use of natural language inference (NLI) data to build high-performance models can outperform conventional methods. However, the potential benefits from the recent ``exponential'' growth of language models with billions of parameters have not yet been fully explored. In this paper, we introduce Multilingual Sentence T5 (m-ST5), as a larger model of NLI-based multilingual sentence embedding, by extending Sentence T5, an existing monolingual model. By employing the low-rank adaptation (LoRA) technique, we have achieved a successful scaling of the model's size to 5.7 billion parameters. We conducted experiments to evaluate the performance of sentence embedding and verified that the method outperforms the NLI-based prior approach. Furthermore, we also have confirmed a positive correlation between the size of the model and its performance. It was particularly noteworthy that languages with fewer resources or those with less linguistic similarity to English benefited more from the parameter increase. Our model is available at https://huggingface.co/pkshatech/m-ST5.
Itô-Taylor Sampling Scheme for Denoising Diffusion Probabilistic Models using Ideal Derivatives
Dec 26, 2021


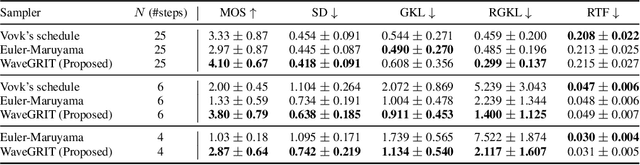
Denoising Diffusion Probabilistic Models (DDPMs) have been attracting attention recently as a new challenger to popular deep neural generative models including GAN, VAE, etc. However, DDPMs have a disadvantage that they often require a huge number of refinement steps during the synthesis. To address this problem, this paper proposes a new DDPM sampler based on a second-order numerical scheme for stochastic differential equations (SDEs), while the conventional sampler is based on a first-order numerical scheme. In general, it is not easy to compute the derivatives that are required in higher-order numerical schemes. However, in the case of DDPM, this difficulty is alleviated by the trick which the authors call "ideal derivative substitution". The newly derived higher-order sampler was applied to both image and speech generation tasks, and it is experimentally observed that the proposed sampler could synthesize plausible images and audio signals in relatively smaller number of refinement steps.
Deep Reinforcement Learning for Inquiry Dialog Policies with Logical Formula Embeddings
Aug 02, 2017
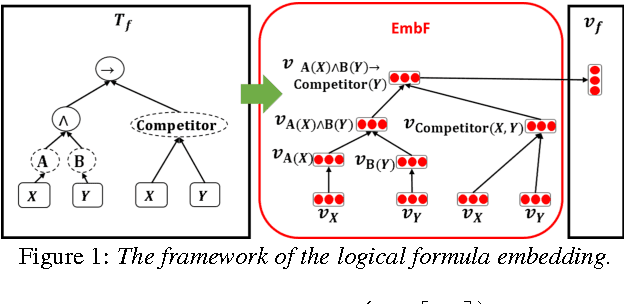
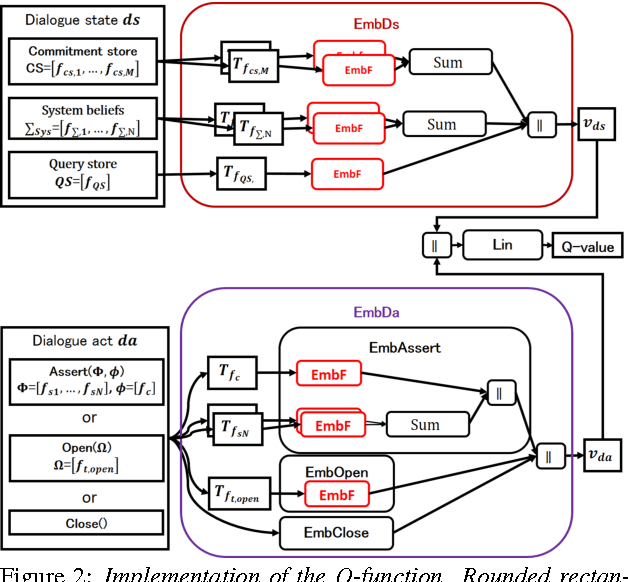
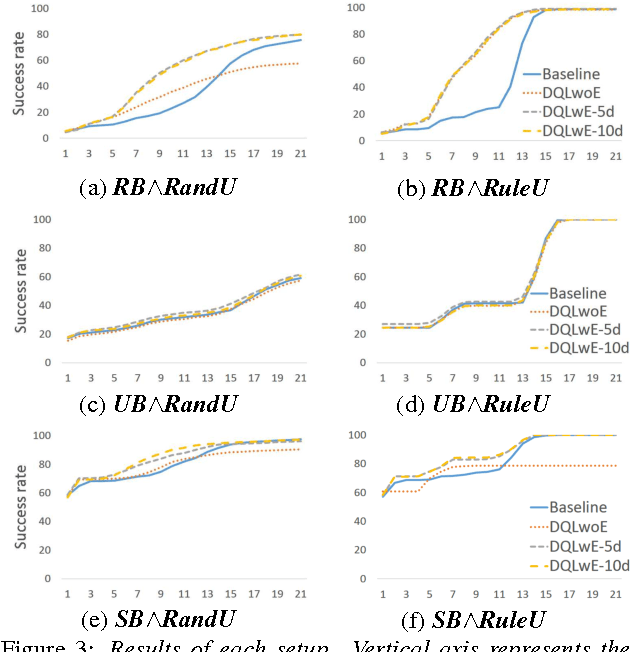
This paper is the first attempt to learn the policy of an inquiry dialog system (IDS) by using deep reinforcement learning (DRL). Most IDS frameworks represent dialog states and dialog acts with logical formulae. In order to make learning inquiry dialog policies more effective, we introduce a logical formula embedding framework based on a recursive neural network. The results of experiments to evaluate the effect of 1) the DRL and 2) the logical formula embedding framework show that the combination of the two are as effective or even better than existing rule-based methods for inquiry dialog policies.