 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePYTHEN: A Flexible Framework for Legal Reasoning in Python
Mar 16, 2026This paper introduces PYTHEN, a novel Python-based framework for defeasible legal reasoning. PYTHEN is designed to model the inherently defeasible nature of legal argumentation, providing a flexible and intuitive syntax for representing legal rules, conditions, and exceptions. Inspired by PROLEG (PROlog-based LEGal reasoning support system) and guided by the philosophy of The Zen of Python, PYTHEN leverages Python's built-in any() and all() functions to offer enhanced flexibility by natively supporting both conjunctive (ALL) and disjunctive (ANY) conditions within a single rule, as well as a more expressive exception-handling mechanism. This paper details the architecture of PYTHEN, provides a comparative analysis with PROLEG, and discusses its potential applications in autoformalization and the development of next-generation legal AI systems. By bridging the gap between symbolic reasoning and the accessibility of Python, PYTHEN aims to democratize formal legal reasoning for young researchers, legal tech developers, and professionals without extensive logic programming expertise. We position PYTHEN as a practical bridge between the powerful symbolic reasoning capabilities of logic programming and the rich, ubiquitous ecosystem of Python, making formal legal reasoning accessible to a broader range of developers and legal professionals.
Data Augmented Pipeline for Legal Information Extraction and Reasoning
Jan 09, 2026In this paper, we propose a pipeline leveraging Large Language Models (LLMs) for data augmentation in Information Extraction tasks within the legal domain. The proposed method is both simple and effective, significantly reducing the manual effort required for data annotation while enhancing the robustness of Information Extraction systems. Furthermore, the method is generalizable, making it applicable to various Natural Language Processing (NLP) tasks beyond the legal domain.
FC-CONAN: An Exhaustively Paired Dataset for Robust Evaluation of Retrieval Systems
Jan 04, 2026Hate speech (HS) is a critical issue in online discourse, and one promising strategy to counter it is through the use of counter-narratives (CNs). Datasets linking HS with CNs are essential for advancing counterspeech research. However, even flagship resources like CONAN (Chung et al., 2019) annotate only a sparse subset of all possible HS-CN pairs, limiting evaluation. We introduce FC-CONAN (Fully Connected CONAN), the first dataset created by exhaustively considering all combinations of 45 English HS messages and 129 CNs. A two-stage annotation process involving nine annotators and four validators produces four partitions-Diamond, Gold, Silver, and Bronze-that balance reliability and scale. None of the labeled pairs overlap with CONAN, uncovering hundreds of previously unlabelled positives. FC-CONAN enables more faithful evaluation of counterspeech retrieval systems and facilitates detailed error analysis. The dataset is publicly available.
Can Legislation Be Made Machine-Readable in PROLEG?
Jan 04, 2026The anticipated positive social impact of regulatory processes requires both the accuracy and efficiency of their application. Modern artificial intelligence technologies, including natural language processing and machine-assisted reasoning, hold great promise for addressing this challenge. We present a framework to address the challenge of tools for regulatory application, based on current state-of-the-art (SOTA) methods for natural language processing (large language models or LLMs) and formalization of legal reasoning (the legal representation system PROLEG). As an example, we focus on Article 6 of the European General Data Protection Regulation (GDPR). In our framework, a single LLM prompt simultaneously transforms legal text into if-then rules and a corresponding PROLEG encoding, which are then validated and refined by legal domain experts. The final output is an executable PROLEG program that can produce human-readable explanations for instances of GDPR decisions. We describe processes to support the end-to-end transformation of a segment of a regulatory document (Article 6 from GDPR), including the prompting frame to guide an LLM to "compile" natural language text to if-then rules, then to further "compile" the vetted if-then rules to PROLEG. Finally, we produce an instance that shows the PROLEG execution. We conclude by summarizing the value of this approach and note observed limitations with suggestions to further develop such technologies for capturing and deploying regulatory frameworks.
Multi-Agent Legal Verifier Systems for Data Transfer Planning
Nov 14, 2025Legal compliance in AI-driven data transfer planning is becoming increasingly critical under stringent privacy regulations such as the Japanese Act on the Protection of Personal Information (APPI). We propose a multi-agent legal verifier that decomposes compliance checking into specialized agents for statutory interpretation, business context evaluation, and risk assessment, coordinated through a structured synthesis protocol. Evaluated on a stratified dataset of 200 Amended APPI Article 16 cases with clearly defined ground truth labels and multiple performance metrics, the system achieves 72% accuracy, which is 21 percentage points higher than a single-agent baseline, including 90% accuracy on clear compliance cases (vs. 16% for the baseline) while maintaining perfect detection of clear violations. While challenges remain in ambiguous scenarios, these results show that domain specialization and coordinated reasoning can meaningfully improve legal AI performance, providing a scalable and regulation-aware framework for trustworthy and interpretable automated compliance verification.
NOWJ@COLIEE 2025: A Multi-stage Framework Integrating Embedding Models and Large Language Models for Legal Retrieval and Entailment
Sep 09, 2025This paper presents the methodologies and results of the NOWJ team's participation across all five tasks at the COLIEE 2025 competition, emphasizing advancements in the Legal Case Entailment task (Task 2). Our comprehensive approach systematically integrates pre-ranking models (BM25, BERT, monoT5), embedding-based semantic representations (BGE-m3, LLM2Vec), and advanced Large Language Models (Qwen-2, QwQ-32B, DeepSeek-V3) for summarization, relevance scoring, and contextual re-ranking. Specifically, in Task 2, our two-stage retrieval system combined lexical-semantic filtering with contextualized LLM analysis, achieving first place with an F1 score of 0.3195. Additionally, in other tasks--including Legal Case Retrieval, Statute Law Retrieval, Legal Textual Entailment, and Legal Judgment Prediction--we demonstrated robust performance through carefully engineered ensembles and effective prompt-based reasoning strategies. Our findings highlight the potential of hybrid models integrating traditional IR techniques with contemporary generative models, providing a valuable reference for future advancements in legal information processing.
BIS Reasoning 1.0: The First Large-Scale Japanese Benchmark for Belief-Inconsistent Syllogistic Reasoning
Jun 08, 2025We present BIS Reasoning 1.0, the first large-scale Japanese dataset of syllogistic reasoning problems explicitly designed to evaluate belief-inconsistent reasoning in large language models (LLMs). Unlike prior datasets such as NeuBAROCO and JFLD, which focus on general or belief-aligned reasoning, BIS Reasoning 1.0 introduces logically valid yet belief-inconsistent syllogisms to uncover reasoning biases in LLMs trained on human-aligned corpora. We benchmark state-of-the-art models - including GPT models, Claude models, and leading Japanese LLMs - revealing significant variance in performance, with GPT-4o achieving 79.54% accuracy. Our analysis identifies critical weaknesses in current LLMs when handling logically valid but belief-conflicting inputs. These findings have important implications for deploying LLMs in high-stakes domains such as law, healthcare, and scientific literature, where truth must override intuitive belief to ensure integrity and safety.
Exploiting LLMs' Reasoning Capability to Infer Implicit Concepts in Legal Information Retrieval
Oct 16, 2024



Statutory law retrieval is a typical problem in legal language processing, that has various practical applications in law engineering. Modern deep learning-based retrieval methods have achieved significant results for this problem. However, retrieval systems relying on semantic and lexical correlations often exhibit limitations, particularly when handling queries that involve real-life scenarios, or use the vocabulary that is not specific to the legal domain. In this work, we focus on overcoming this weaknesses by utilizing the logical reasoning capabilities of large language models (LLMs) to identify relevant legal terms and facts related to the situation mentioned in the query. The proposed retrieval system integrates additional information from the term--based expansion and query reformulation to improve the retrieval accuracy. The experiments on COLIEE 2022 and COLIEE 2023 datasets show that extra knowledge from LLMs helps to improve the retrieval result of both lexical and semantic ranking models. The final ensemble retrieval system outperformed the highest results among all participating teams in the COLIEE 2022 and 2023 competitions.
Detection of ransomware attacks using federated learning based on the CNN model
May 01, 2024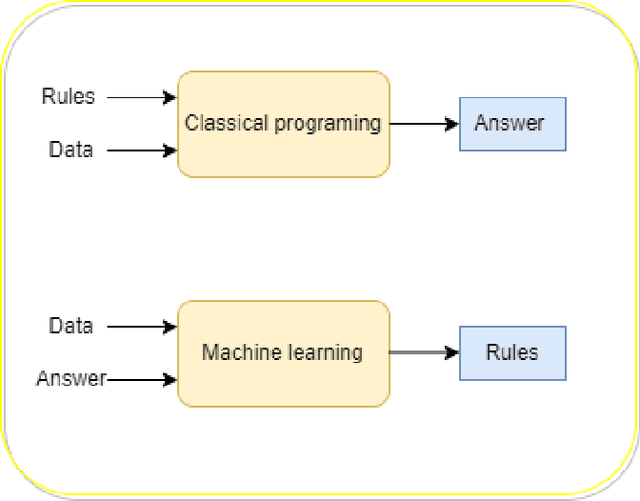

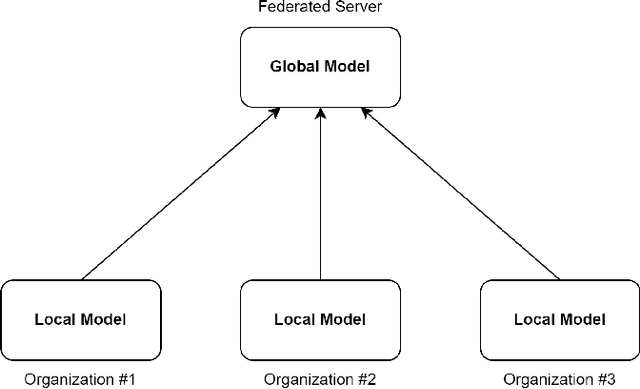
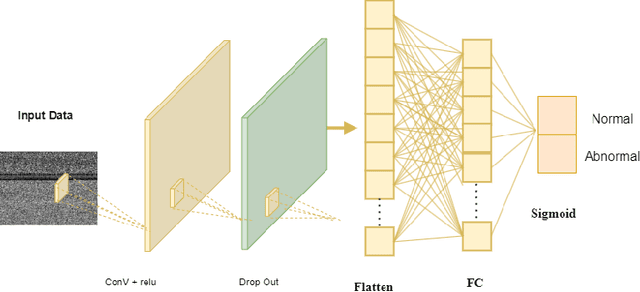
Computing is still under a significant threat from ransomware, which necessitates prompt action to prevent it. Ransomware attacks can have a negative impact on how smart grids, particularly digital substations. In addition to examining a ransomware detection method using artificial intelligence (AI), this paper offers a ransomware attack modeling technique that targets the disrupted operation of a digital substation. The first, binary data is transformed into image data and fed into the convolution neural network model using federated learning. The experimental findings demonstrate that the suggested technique detects ransomware with a high accuracy rate.
Enhancing Legal Document Retrieval: A Multi-Phase Approach with Large Language Models
Mar 26, 2024



Large language models with billions of parameters, such as GPT-3.5, GPT-4, and LLaMA, are increasingly prevalent. Numerous studies have explored effective prompting techniques to harness the power of these LLMs for various research problems. Retrieval, specifically in the legal data domain, poses a challenging task for the direct application of Prompting techniques due to the large number and substantial length of legal articles. This research focuses on maximizing the potential of prompting by placing it as the final phase of the retrieval system, preceded by the support of two phases: BM25 Pre-ranking and BERT-based Re-ranking. Experiments on the COLIEE 2023 dataset demonstrate that integrating prompting techniques on LLMs into the retrieval system significantly improves retrieval accuracy. However, error analysis reveals several existing issues in the retrieval system that still need resolution.