 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDPR Auto-Formalization with AI Agents and Human Verification
Apr 16, 2026We study the overall process of automatic formalization of GDPR provisions using large language models, within a human-in-the-loop verification framework. Rather than aiming for full autonomy, we adopt a role-specialized workflow in which LLM-based AI components, operating in a multi-agent setting with iterative feedback, generate legal scenarios, formal rules, and atomic facts. This is coupled with independent verification modules which include human reviewers' assessment of representational, logical, and legal correctness. Using this approach, we construct a high-quality dataset to be used for GDPR auto-formalization, and analyze both successful and problematic cases. Our results show that structured verification and targeted human oversight are essential for reliable legal formalization, especially in the presence of legal nuance and context-sensitive reasoning.
Legal2LogicICL: Improving Generalization in Transforming Legal Cases to Logical Formulas via Diverse Few-Shot Learning
Apr 13, 2026This work aims to improve the generalization of logic-based legal reasoning systems by integrating recent advances in NLP with legal-domain adaptive few-shot learning techniques using LLMs. Existing logic-based legal reasoning pipelines typically rely on fine-tuned models to map natural-language legal cases into logical formulas before forwarding them to a symbolic reasoner. However, such approaches are heavily constrained by the scarcity of high-quality annotated training data. To address this limitation, we propose a novel LLM-based legal reasoning framework that enables effective in-context learning through retrieval-augmented generation. Specifically, we introduce Legal2LogicICL, a few-shot retrieval framework that balances diversity and similarity of exemplars at both the latent semantic representation level and the legal text structure level. In addition, our method explicitly accounts for legal structure by mitigating entity-induced retrieval bias in legal texts, where lengthy and highly specific entity mentions often dominate semantic representations and obscure legally meaningful reasoning patterns. Our Legal2LogicICL constructs informative and robust few-shot demonstrations, leading to accurate and stable logical rule generation without requiring additional training. In addition, we construct a new dataset, named Legal2Proleg, which is annotated with alignments between legal cases and PROLEG logical formulas to support the evaluation of legal semantic parsing. Experimental results on both open-source and proprietary LLMs demonstrate that our approach significantly improves accuracy, stability, and generalization in transforming natural-language legal case descriptions into logical representations, highlighting its effectiveness for interpretable and reliable legal reasoning. Our code is available at https://github.com/yingjie7/Legal2LogicICL.
PYTHEN: A Flexible Framework for Legal Reasoning in Python
Mar 16, 2026This paper introduces PYTHEN, a novel Python-based framework for defeasible legal reasoning. PYTHEN is designed to model the inherently defeasible nature of legal argumentation, providing a flexible and intuitive syntax for representing legal rules, conditions, and exceptions. Inspired by PROLEG (PROlog-based LEGal reasoning support system) and guided by the philosophy of The Zen of Python, PYTHEN leverages Python's built-in any() and all() functions to offer enhanced flexibility by natively supporting both conjunctive (ALL) and disjunctive (ANY) conditions within a single rule, as well as a more expressive exception-handling mechanism. This paper details the architecture of PYTHEN, provides a comparative analysis with PROLEG, and discusses its potential applications in autoformalization and the development of next-generation legal AI systems. By bridging the gap between symbolic reasoning and the accessibility of Python, PYTHEN aims to democratize formal legal reasoning for young researchers, legal tech developers, and professionals without extensive logic programming expertise. We position PYTHEN as a practical bridge between the powerful symbolic reasoning capabilities of logic programming and the rich, ubiquitous ecosystem of Python, making formal legal reasoning accessible to a broader range of developers and legal professionals.
Data Augmented Pipeline for Legal Information Extraction and Reasoning
Jan 09, 2026In this paper, we propose a pipeline leveraging Large Language Models (LLMs) for data augmentation in Information Extraction tasks within the legal domain. The proposed method is both simple and effective, significantly reducing the manual effort required for data annotation while enhancing the robustness of Information Extraction systems. Furthermore, the method is generalizable, making it applicable to various Natural Language Processing (NLP) tasks beyond the legal domain.
Can Legislation Be Made Machine-Readable in PROLEG?
Jan 04, 2026The anticipated positive social impact of regulatory processes requires both the accuracy and efficiency of their application. Modern artificial intelligence technologies, including natural language processing and machine-assisted reasoning, hold great promise for addressing this challenge. We present a framework to address the challenge of tools for regulatory application, based on current state-of-the-art (SOTA) methods for natural language processing (large language models or LLMs) and formalization of legal reasoning (the legal representation system PROLEG). As an example, we focus on Article 6 of the European General Data Protection Regulation (GDPR). In our framework, a single LLM prompt simultaneously transforms legal text into if-then rules and a corresponding PROLEG encoding, which are then validated and refined by legal domain experts. The final output is an executable PROLEG program that can produce human-readable explanations for instances of GDPR decisions. We describe processes to support the end-to-end transformation of a segment of a regulatory document (Article 6 from GDPR), including the prompting frame to guide an LLM to "compile" natural language text to if-then rules, then to further "compile" the vetted if-then rules to PROLEG. Finally, we produce an instance that shows the PROLEG execution. We conclude by summarizing the value of this approach and note observed limitations with suggestions to further develop such technologies for capturing and deploying regulatory frameworks.
FC-CONAN: An Exhaustively Paired Dataset for Robust Evaluation of Retrieval Systems
Jan 04, 2026Hate speech (HS) is a critical issue in online discourse, and one promising strategy to counter it is through the use of counter-narratives (CNs). Datasets linking HS with CNs are essential for advancing counterspeech research. However, even flagship resources like CONAN (Chung et al., 2019) annotate only a sparse subset of all possible HS-CN pairs, limiting evaluation. We introduce FC-CONAN (Fully Connected CONAN), the first dataset created by exhaustively considering all combinations of 45 English HS messages and 129 CNs. A two-stage annotation process involving nine annotators and four validators produces four partitions-Diamond, Gold, Silver, and Bronze-that balance reliability and scale. None of the labeled pairs overlap with CONAN, uncovering hundreds of previously unlabelled positives. FC-CONAN enables more faithful evaluation of counterspeech retrieval systems and facilitates detailed error analysis. The dataset is publicly available.
Multi-Agent Legal Verifier Systems for Data Transfer Planning
Nov 14, 2025Legal compliance in AI-driven data transfer planning is becoming increasingly critical under stringent privacy regulations such as the Japanese Act on the Protection of Personal Information (APPI). We propose a multi-agent legal verifier that decomposes compliance checking into specialized agents for statutory interpretation, business context evaluation, and risk assessment, coordinated through a structured synthesis protocol. Evaluated on a stratified dataset of 200 Amended APPI Article 16 cases with clearly defined ground truth labels and multiple performance metrics, the system achieves 72% accuracy, which is 21 percentage points higher than a single-agent baseline, including 90% accuracy on clear compliance cases (vs. 16% for the baseline) while maintaining perfect detection of clear violations. While challenges remain in ambiguous scenarios, these results show that domain specialization and coordinated reasoning can meaningfully improve legal AI performance, providing a scalable and regulation-aware framework for trustworthy and interpretable automated compliance verification.
An Argumentative Explanation Framework for Generalized Reason Model with Inconsistent Precedents
Oct 22, 2025Precedential constraint is one foundation of case-based reasoning in AI and Law. It generally assumes that the underlying set of precedents must be consistent. To relax this assumption, a generalized notion of the reason model has been introduced. While several argumentative explanation approaches exist for reasoning with precedents based on the traditional consistent reason model, there has been no corresponding argumentative explanation method developed for this generalized reasoning framework accommodating inconsistent precedents. To address this question, this paper examines an extension of the derivation state argumentation framework (DSA-framework) to explain the reasoning according to the generalized notion of the reason model.
Anonymous Public Announcements
Apr 21, 2025



We formalise the notion of an anonymous public announcement in the tradition of public announcement logic. Such announcements can be seen as in-between a public announcement from ``the outside" (an announcement of $\phi$) and a public announcement by one of the agents (an announcement of $K_a\phi$): we get more information than just $\phi$, but not (necessarily) about exactly who made it. Even if such an announcement is prima facie anonymous, depending on the background knowledge of the agents it might reveal the identity of the announcer: if I post something on a message board, the information might reveal who I am even if I don't sign my name. Furthermore, like in the Russian Cards puzzle, if we assume that the announcer's intention was to stay anonymous, that in fact might reveal more information. In this paper we first look at the case when no assumption about intentions are made, in which case the logic with an anonymous public announcement operator is reducible to epistemic logic. We then look at the case when we assume common knowledge of the intention to stay anonymous, which is both more complex and more interesting: in several ways it boils down to the notion of a ``safe" announcement (again, similarly to Russian Cards). Main results include formal expressivity results and axiomatic completeness for key logical languages.
Layer-of-Thoughts Prompting (LoT): Leveraging LLM-Based Retrieval with Constraint Hierarchies
Oct 16, 2024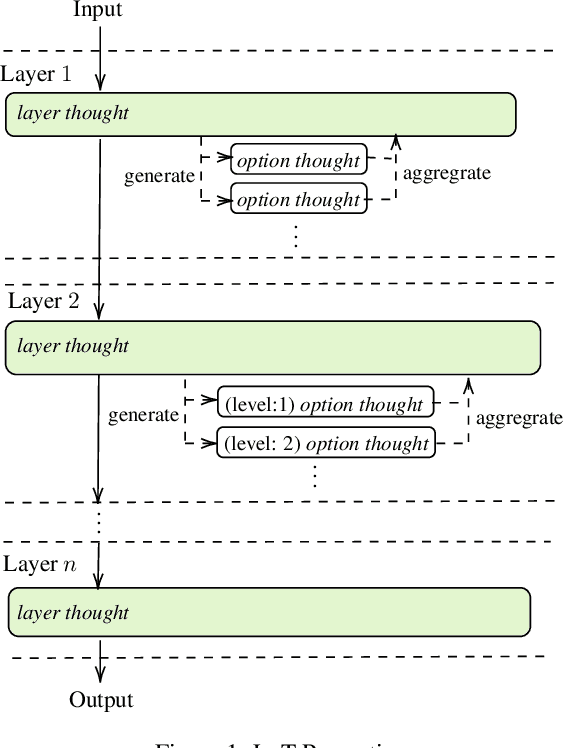
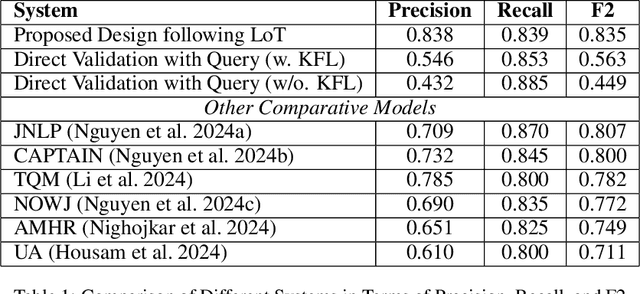
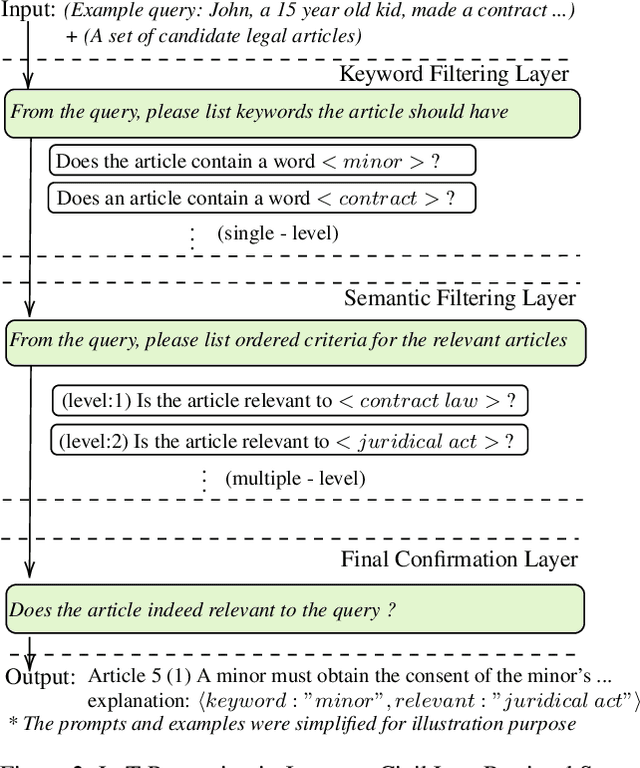
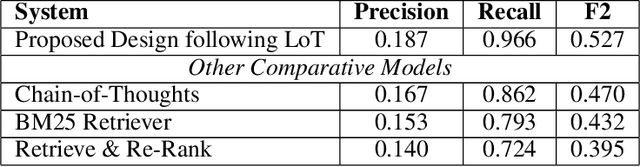
This paper presents a novel approach termed Layer-of-Thoughts Prompting (LoT), which utilizes constraint hierarchies to filter and refine candidate responses to a given query. By integrating these constraints, our method enables a structured retrieval process that enhances explainability and automation. Existing methods have explored various prompting techniques but often present overly generalized frameworks without delving into the nuances of prompts in multi-turn interactions. Our work addresses this gap by focusing on the hierarchical relationships among prompts. We demonstrate that the efficacy of thought hierarchy plays a critical role in developing efficient and interpretable retrieval algorithms. Leveraging Large Language Models (LLMs), LoT significantly improves the accuracy and comprehensibility of information retrieval tasks.