 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing and Mitigating Semantic Inconsistencies in Wikidata's Classification Hierarchy
Nov 07, 2025Wikidata is currently the largest open knowledge graph on the web, encompassing over 120 million entities. It integrates data from various domain-specific databases and imports a substantial amount of content from Wikipedia, while also allowing users to freely edit its content. This openness has positioned Wikidata as a central resource in knowledge graph research and has enabled convenient knowledge access for users worldwide. However, its relatively loose editorial policy has also led to a degree of taxonomic inconsistency. Building on prior work, this study proposes and applies a novel validation method to confirm the presence of classification errors, over-generalized subclass links, and redundant connections in specific domains of Wikidata. We further introduce a new evaluation criterion for determining whether such issues warrant correction and develop a system that allows users to inspect the taxonomic relationships of arbitrary Wikidata entities-leveraging the platform's crowdsourced nature to its full potential.
An Argumentative Approach for Explaining Preemption in Soft-Constraint Based Norms
Sep 06, 2024



Although various aspects of soft-constraint based norms have been explored, it is still challenging to understand preemption. Preemption is a situation where higher-level norms override lower-level norms when new information emerges. To address this, we propose a derivation state argumentation framework (DSA-framework). DSA-framework incorporates derivation states to explain how preemption arises based on evolving situational knowledge. Based on DSA-framework, we present an argumentative approach for explaining preemption. We formally prove that, under local optimality, DSA-framework can provide explanations why one consequence is obligatory or forbidden by soft-constraint based norms represented as logical constraint hierarchies.
SPARQL Generation with Entity Pre-trained GPT for KG Question Answering
Feb 01, 2024Knowledge Graphs popularity has been rapidly growing in last years. All that knowledge is available for people to query it through the many online databases on the internet. Though, it would be a great achievement if non-programmer users could access whatever information they want to know. There has been a lot of effort oriented to solve this task using natural language processing tools and creativity encouragement by way of many challenges. Our approach focuses on assuming a correct entity linking on the natural language questions and training a GPT model to create SPARQL queries from them. We managed to isolate which property of the task can be the most difficult to solve at few or zero-shot and we proposed pre-training on all entities (under CWA) to improve the performance. We obtained a 62.703% accuracy of exact SPARQL matches on testing at 3-shots, a F1 of 0.809 on the entity linking challenge and a F1 of 0.009 on the question answering challenge.
TabIQA: Table Questions Answering on Business Document Images
Mar 27, 2023



Table answering questions from business documents has many challenges that require understanding tabular structures, cross-document referencing, and additional numeric computations beyond simple search queries. This paper introduces a novel pipeline, named TabIQA, to answer questions about business document images. TabIQA combines state-of-the-art deep learning techniques 1) to extract table content and structural information from images and 2) to answer various questions related to numerical data, text-based information, and complex queries from structured tables. The evaluation results on VQAonBD 2023 dataset demonstrate the effectiveness of TabIQA in achieving promising performance in answering table-related questions. The TabIQA repository is available at https://github.com/phucty/itabqa.
Rethinking Image-based Table Recognition Using Weakly Supervised Methods
Mar 14, 2023



Most of the previous methods for table recognition rely on training datasets containing many richly annotated table images. Detailed table image annotation, e.g., cell or text bounding box annotation, however, is costly and often subjective. In this paper, we propose a weakly supervised model named WSTabNet for table recognition that relies only on HTML (or LaTeX) code-level annotations of table images. The proposed model consists of three main parts: an encoder for feature extraction, a structure decoder for generating table structure, and a cell decoder for predicting the content of each cell in the table. Our system is trained end-to-end by stochastic gradient descent algorithms, requiring only table images and their ground-truth HTML (or LaTeX) representations. To facilitate table recognition with deep learning, we create and release WikiTableSet, the largest publicly available image-based table recognition dataset built from Wikipedia. WikiTableSet contains nearly 4 million English table images, 590K Japanese table images, and 640k French table images with corresponding HTML representation and cell bounding boxes. The extensive experiments on WikiTableSet and two large-scale datasets: FinTabNet and PubTabNet demonstrate that the proposed weakly supervised model achieves better, or similar accuracies compared to the state-of-the-art models on all benchmark datasets.
* 10 pages, ICPRAM2023
TabEAno: Table to Knowledge Graph Entity Annotation
Oct 05, 2020
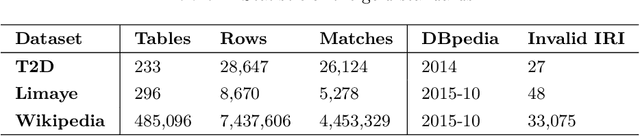
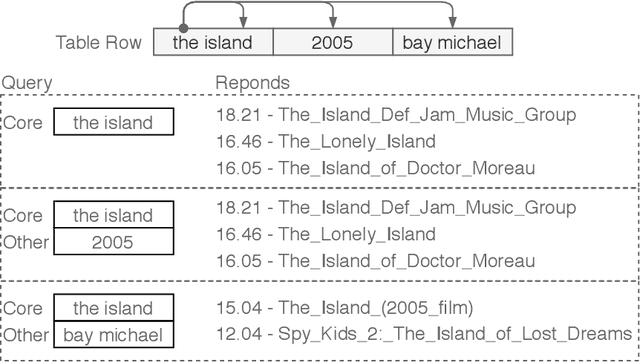
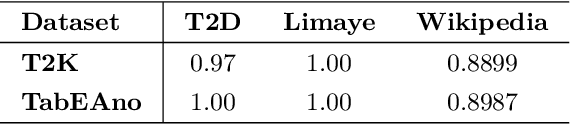
In the Open Data era, a large number of table resources have been made available on the Web and data portals. However, it is difficult to directly utilize such data due to the ambiguity of entities, name variations, heterogeneous schema, missing, or incomplete metadata. To address these issues, we propose a novel approach, namely TabEAno, to semantically annotate table rows toward knowledge graph entities. Specifically, we introduce a "two-cells" lookup strategy bases on the assumption that there is an existing logical relation occurring in the knowledge graph between the two closed cells in the same row of the table. Despite the simplicity of the approach, TabEAno outperforms the state of the art approaches in the two standard datasets e.g, T2D, Limaye with, and in the large-scale Wikipedia tables dataset.
LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention
Oct 02, 2020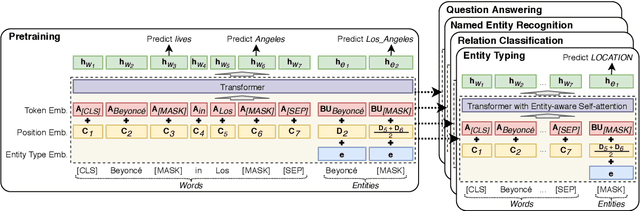
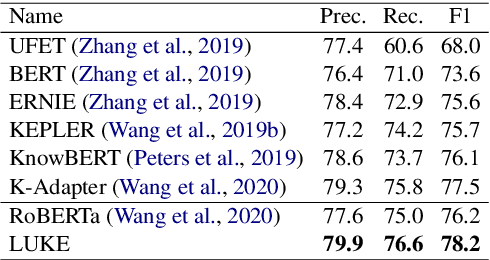
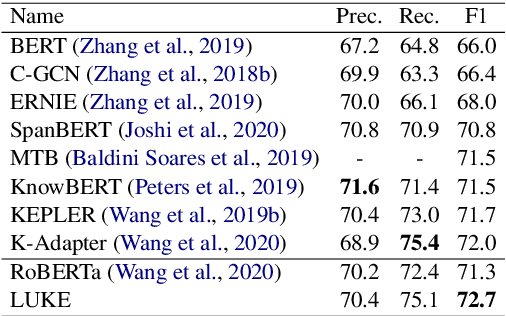
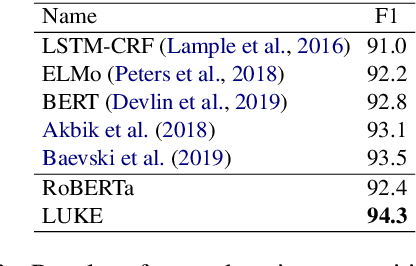
Entity representations are useful in natural language tasks involving entities. In this paper, we propose new pretrained contextualized representations of words and entities based on the bidirectional transformer. The proposed model treats words and entities in a given text as independent tokens, and outputs contextualized representations of them. Our model is trained using a new pretraining task based on the masked language model of BERT. The task involves predicting randomly masked words and entities in a large entity-annotated corpus retrieved from Wikipedia. We also propose an entity-aware self-attention mechanism that is an extension of the self-attention mechanism of the transformer, and considers the types of tokens (words or entities) when computing attention scores. The proposed model achieves impressive empirical performance on a wide range of entity-related tasks. In particular, it obtains state-of-the-art results on five well-known datasets: Open Entity (entity typing), TACRED (relation classification), CoNLL-2003 (named entity recognition), ReCoRD (cloze-style question answering), and SQuAD 1.1 (extractive question answering). Our source code and pretrained representations are available at https://github.com/studio-ousia/luke.
MTab: Matching Tabular Data to Knowledge Graph using Probability Models
Oct 01, 2019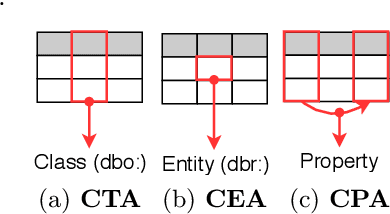
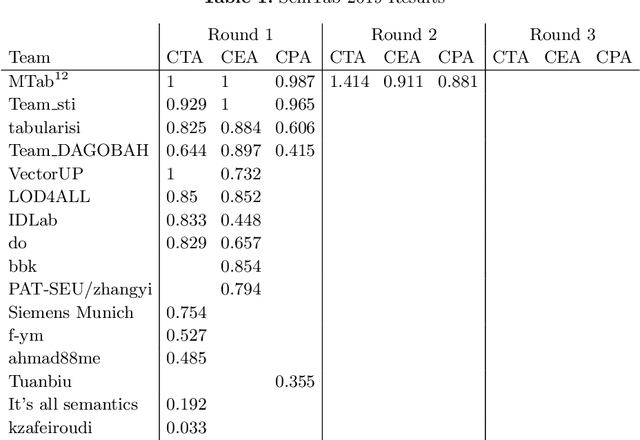
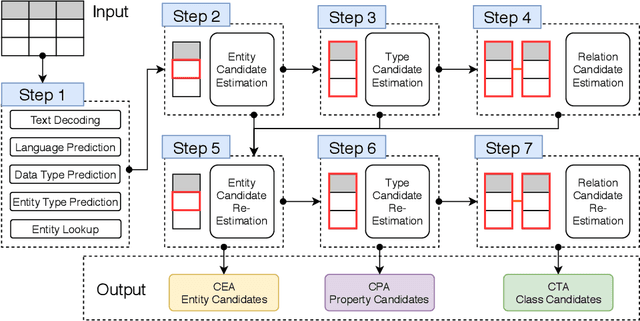
This paper presents the design of our system, namely MTab, for Semantic Web Challenge on Tabular Data to Knowledge Graph Matching (SemTab 2019). MTab combines the voting algorithm and the probability models to solve critical problems of the matching tasks. Results on SemTab 2019 show that MTab obtains promising performance for the three matching tasks.
Wikipedia2Vec: An Optimized Tool for Learning Embeddings of Words and Entities from Wikipedia
Dec 26, 2018
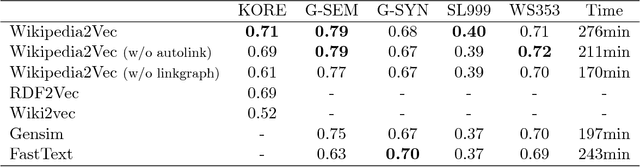
We present Wikipedia2Vec, an open source tool for learning embeddings of words and entities from Wikipedia. This tool enables users to easily obtain high-quality embeddings of words and entities from a Wikipedia dump with a single command. The learned embeddings can be used as features in downstream natural language processing (NLP) models. The tool can be installed via PyPI. The source code, documentation, and pretrained embeddings for 12 major languages can be obtained at http://wikipedia2vec.github.io.
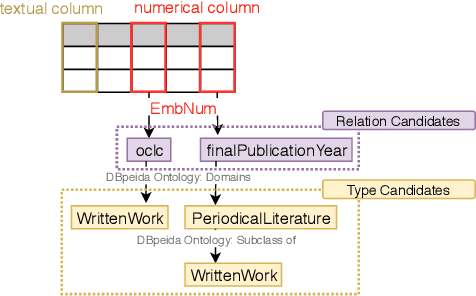
EmbNum: Semantic labeling for numerical values with deep metric learning
Aug 16, 2018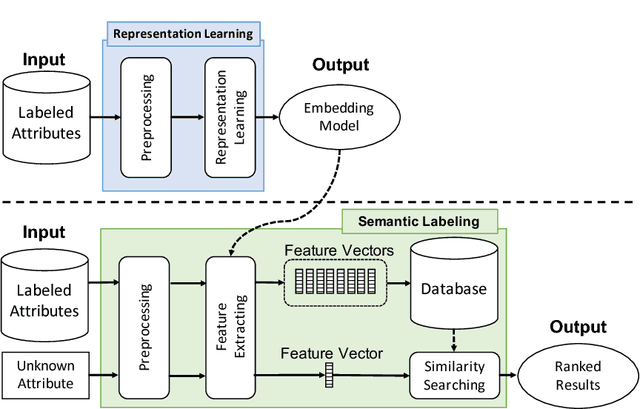

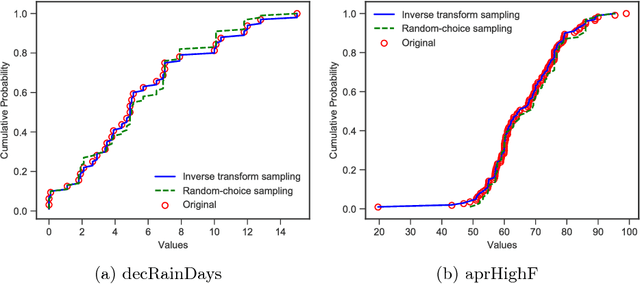
Semantic labeling for numerical values is a task of assigning semantic labels to unknown numerical attributes. The semantic labels could be numerical properties in ontologies, instances in knowledge bases, or labeled data that are manually annotated by domain experts. In this paper, we refer to semantic labeling as a retrieval setting where the label of an unknown attribute is assigned by the label of the most relevant attribute in labeled data. One of the greatest challenges is that an unknown attribute rarely has the same set of values with the similar one in the labeled data. To overcome the issue, statistical interpretation of value distribution is taken into account. However, the existing studies assume a specific form of distribution. It is not appropriate in particular to apply open data where there is no knowledge of data in advance. To address these problems, we propose a neural numerical embedding model (EmbNum) to learn useful representation vectors for numerical attributes without prior assumptions on the distribution of data. Then, the "semantic similarities" between the attributes are measured on these representation vectors by the Euclidean distance. Our empirical experiments on City Data and Open Data show that EmbNum significantly outperforms state-of-the-art methods for the task of numerical attribute semantic labeling regarding effectiveness and efficiency.