 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Structured Trajectory Extraction from Travelogues
Oct 22, 2024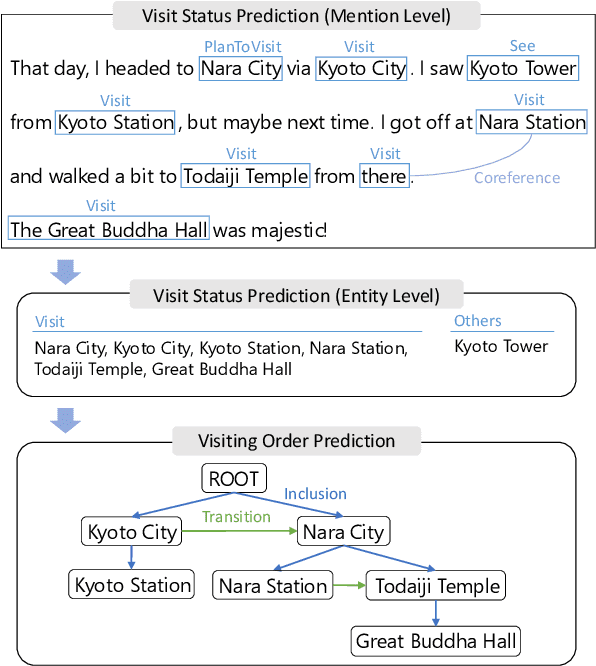

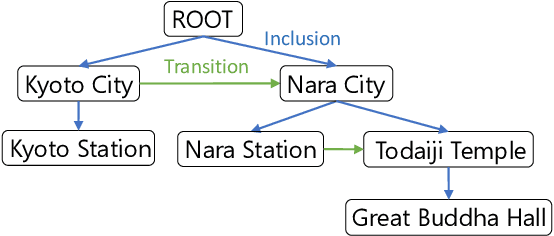
Previous studies on sequence-based extraction of human movement trajectories have an issue of inadequate trajectory representation. Specifically, a pair of locations may not be lined up in a sequence especially when one location includes the other geographically. In this study, we propose a graph representation that retains information on the geographic hierarchy as well as the temporal order of visited locations, and have constructed a benchmark dataset for graph-structured trajectory extraction. The experiments with our baselines have demonstrated that it is possible to accurately predict visited locations and the order among them, but it remains a challenge to predict the hierarchical relations.
Distilling Named Entity Recognition Models for Endangered Species from Large Language Models
Mar 13, 2024Natural language processing (NLP) practitioners are leveraging large language models (LLM) to create structured datasets from semi-structured and unstructured data sources such as patents, papers, and theses, without having domain-specific knowledge. At the same time, ecological experts are searching for a variety of means to preserve biodiversity. To contribute to these efforts, we focused on endangered species and through in-context learning, we distilled knowledge from GPT-4. In effect, we created datasets for both named entity recognition (NER) and relation extraction (RE) via a two-stage process: 1) we generated synthetic data from GPT-4 of four classes of endangered species, 2) humans verified the factual accuracy of the synthetic data, resulting in gold data. Eventually, our novel dataset contains a total of 3.6K sentences, evenly divided between 1.8K NER and 1.8K RE sentences. The constructed dataset was then used to fine-tune both general BERT and domain-specific BERT variants, completing the knowledge distillation process from GPT-4 to BERT, because GPT-4 is resource intensive. Experiments show that our knowledge transfer approach is effective at creating a NER model suitable for detecting endangered species from texts.
Arukikata Travelogue Dataset with Geographic Entity Mention, Coreference, and Link Annotation
May 23, 2023
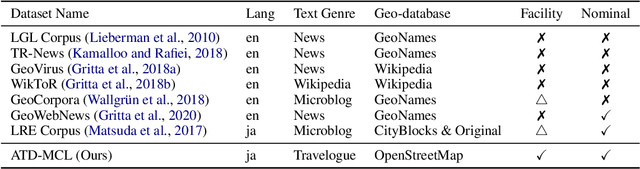
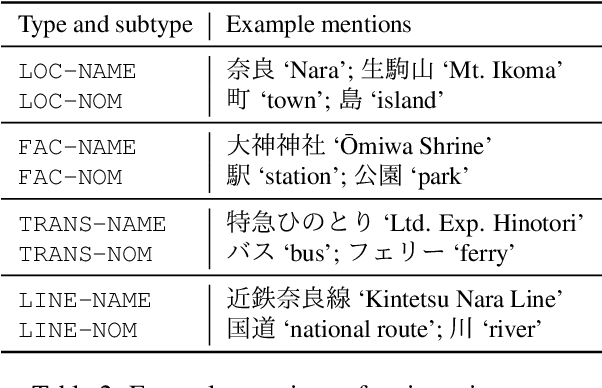

Geoparsing is a fundamental technique for analyzing geo-entity information in text. We focus on document-level geoparsing, which considers geographic relatedness among geo-entity mentions, and presents a Japanese travelogue dataset designed for evaluating document-level geoparsing systems. Our dataset comprises 200 travelogue documents with rich geo-entity information: 12,171 mentions, 6,339 coreference clusters, and 2,551 geo-entities linked to geo-database entries.
Arukikata Travelogue Dataset
May 19, 2023
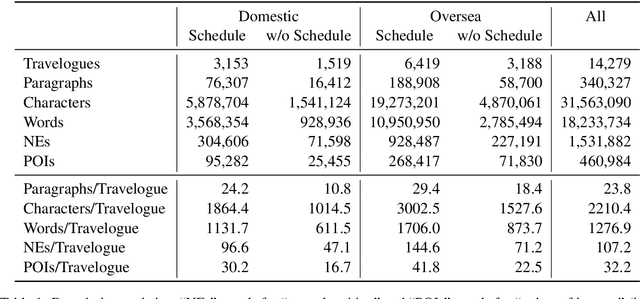
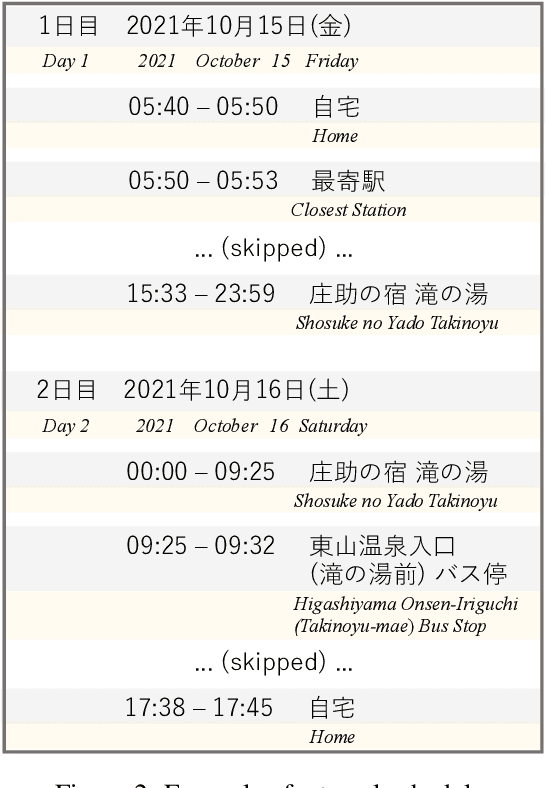
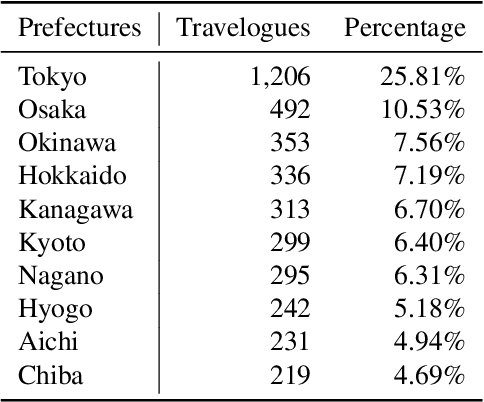
We have constructed Arukikata Travelogue Dataset and released it free of charge for academic research. This dataset is a Japanese text dataset with a total of over 31 million words, comprising 4,672 Japanese domestic travelogues and 9,607 overseas travelogues. Before providing our dataset, there was a scarcity of widely available travelogue data for research purposes, and each researcher had to prepare their own data. This hinders the replication of existing studies and fair comparative analysis of experimental results. Our dataset enables any researchers to conduct investigation on the same data and to ensure transparency and reproducibility in research. In this paper, we describe the academic significance, characteristics, and prospects of our dataset.
LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention
Oct 02, 2020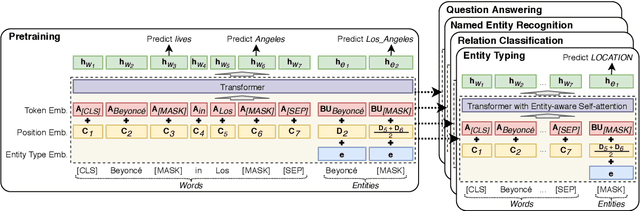
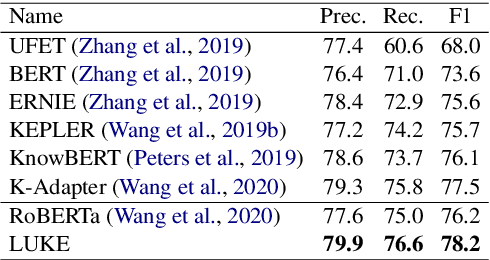
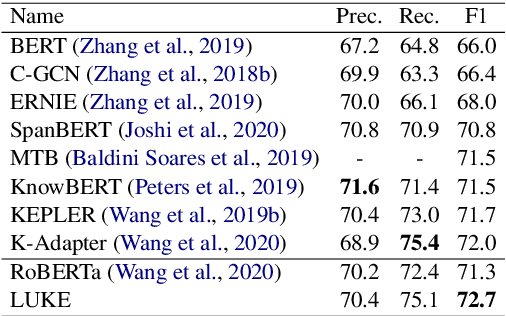
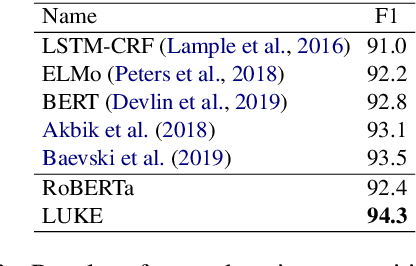
Entity representations are useful in natural language tasks involving entities. In this paper, we propose new pretrained contextualized representations of words and entities based on the bidirectional transformer. The proposed model treats words and entities in a given text as independent tokens, and outputs contextualized representations of them. Our model is trained using a new pretraining task based on the masked language model of BERT. The task involves predicting randomly masked words and entities in a large entity-annotated corpus retrieved from Wikipedia. We also propose an entity-aware self-attention mechanism that is an extension of the self-attention mechanism of the transformer, and considers the types of tokens (words or entities) when computing attention scores. The proposed model achieves impressive empirical performance on a wide range of entity-related tasks. In particular, it obtains state-of-the-art results on five well-known datasets: Open Entity (entity typing), TACRED (relation classification), CoNLL-2003 (named entity recognition), ReCoRD (cloze-style question answering), and SQuAD 1.1 (extractive question answering). Our source code and pretrained representations are available at https://github.com/studio-ousia/luke.
Length-controllable Abstractive Summarization by Guiding with Summary Prototype
Jan 21, 2020
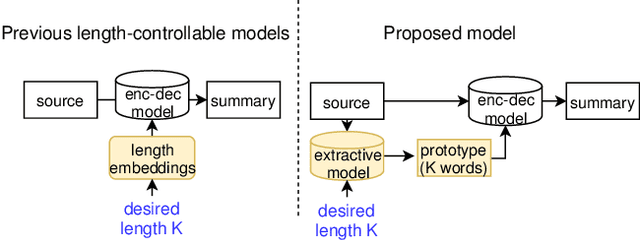
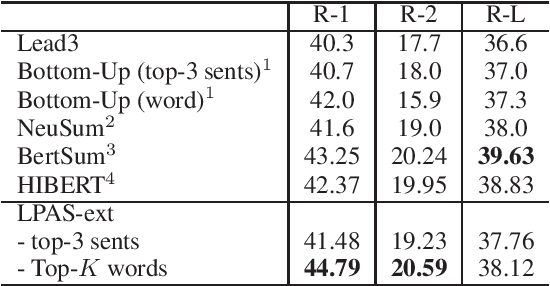
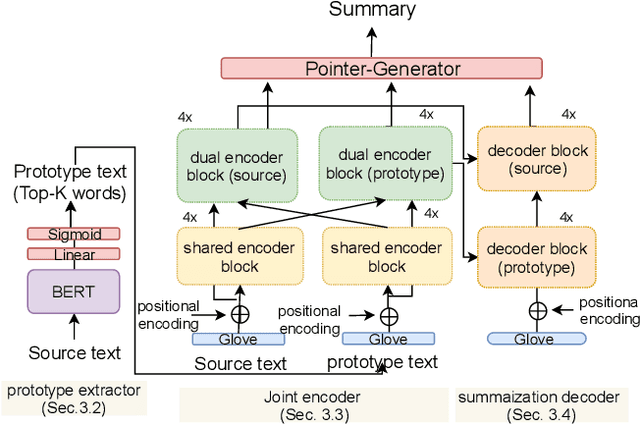
We propose a new length-controllable abstractive summarization model. Recent state-of-the-art abstractive summarization models based on encoder-decoder models generate only one summary per source text. However, controllable summarization, especially of the length, is an important aspect for practical applications. Previous studies on length-controllable abstractive summarization incorporate length embeddings in the decoder module for controlling the summary length. Although the length embeddings can control where to stop decoding, they do not decide which information should be included in the summary within the length constraint. Unlike the previous models, our length-controllable abstractive summarization model incorporates a word-level extractive module in the encoder-decoder model instead of length embeddings. Our model generates a summary in two steps. First, our word-level extractor extracts a sequence of important words (we call it the "prototype text") from the source text according to the word-level importance scores and the length constraint. Second, the prototype text is used as additional input to the encoder-decoder model, which generates a summary by jointly encoding and copying words from both the prototype text and source text. Since the prototype text is a guide to both the content and length of the summary, our model can generate an informative and length-controlled summary. Experiments with the CNN/Daily Mail dataset and the NEWSROOM dataset show that our model outperformed previous models in length-controlled settings.
Neural Attentive Bag-of-Entities Model for Text Classification
Sep 10, 2019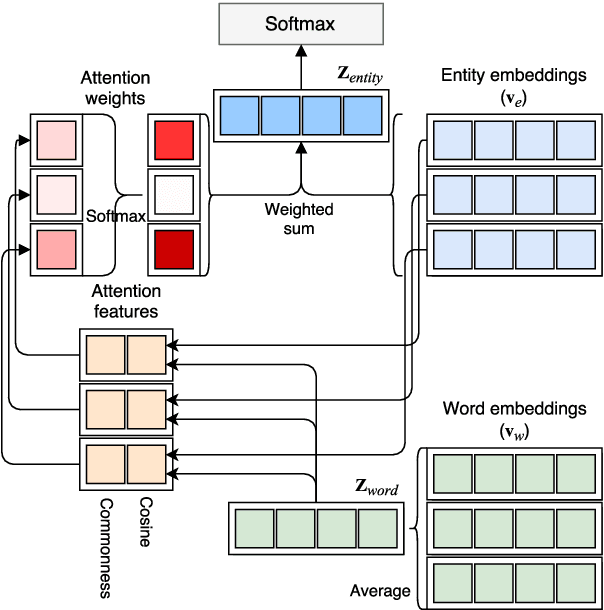
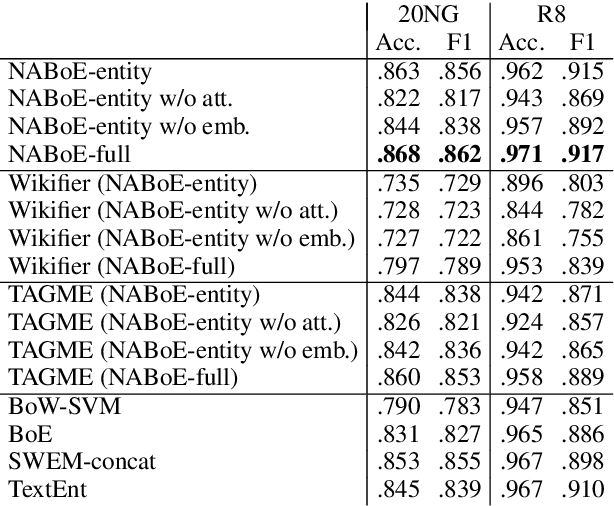
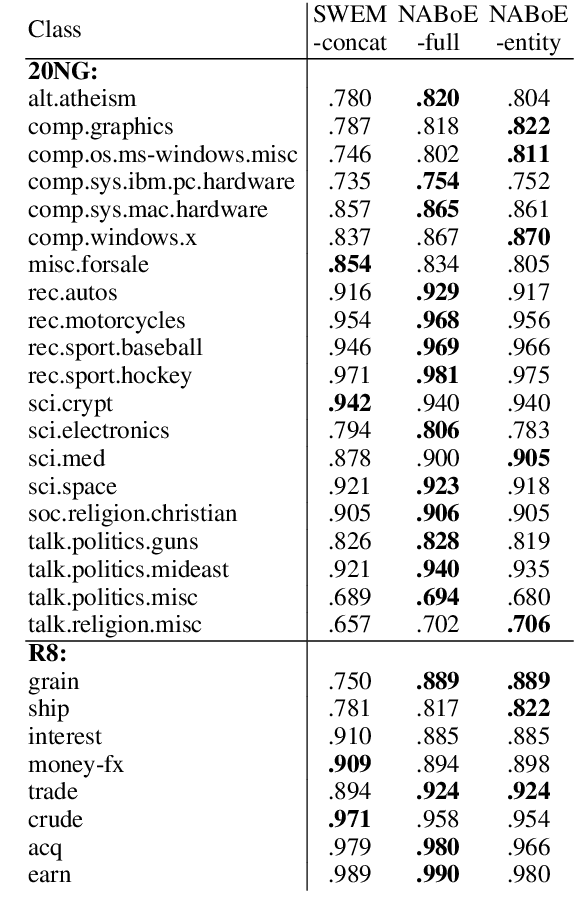

This study proposes a Neural Attentive Bag-of-Entities model, which is a neural network model that performs text classification using entities in a knowledge base. Entities provide unambiguous and relevant semantic signals that are beneficial for capturing semantics in texts. We combine simple high-recall entity detection based on a dictionary, to detect entities in a document, with a novel neural attention mechanism that enables the model to focus on a small number of unambiguous and relevant entities. We tested the effectiveness of our model using two standard text classification datasets (i.e., the 20 Newsgroups and R8 datasets) and a popular factoid question answering dataset based on a trivia quiz game. As a result, our model achieved state-of-the-art results on all datasets. The source code of the proposed model is available online at https://github.com/wikipedia2vec/wikipedia2vec.
Pre-training of Deep Contextualized Embeddings of Words and Entities for Named Entity Disambiguation
Sep 01, 2019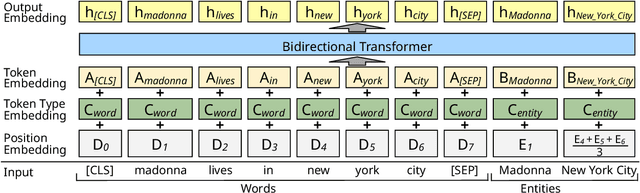

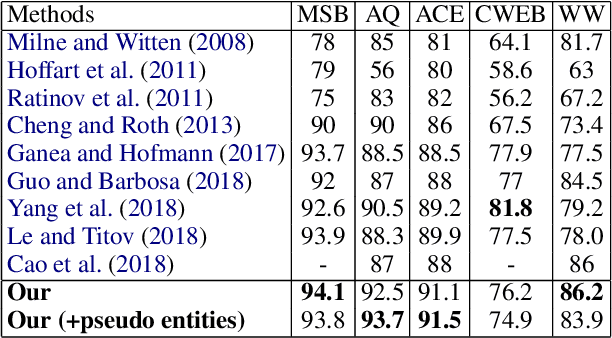
Deep contextualized embeddings trained using unsupervised language modeling (e.g., ELMo and BERT) are successful in a wide range of NLP tasks. In this paper, we propose a new contextualized embedding model of words and entities for named entity disambiguation (NED). Our model is based on the bidirectional transformer encoder and produces contextualized embeddings for words and entities in the input text. The embeddings are trained using a new masked entity prediction task that aims to train the model by predicting randomly masked entities in entity-annotated texts. We trained the model using entity-annotated texts obtained from Wikipedia. We evaluated our model by addressing NED using a simple NED model based on the trained contextualized embeddings. As a result, we achieved state-of-the-art or competitive results on several standard NED datasets.
Gated Graph Recursive Neural Networks for Molecular Property Prediction
Aug 31, 2019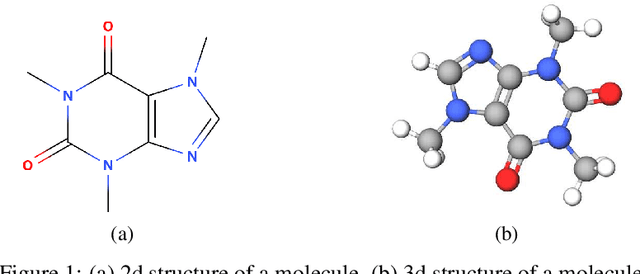
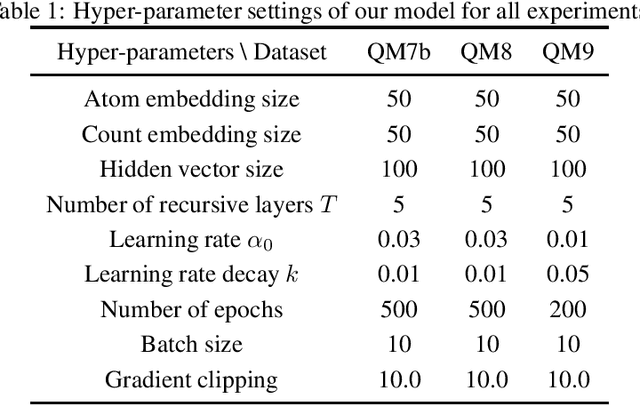
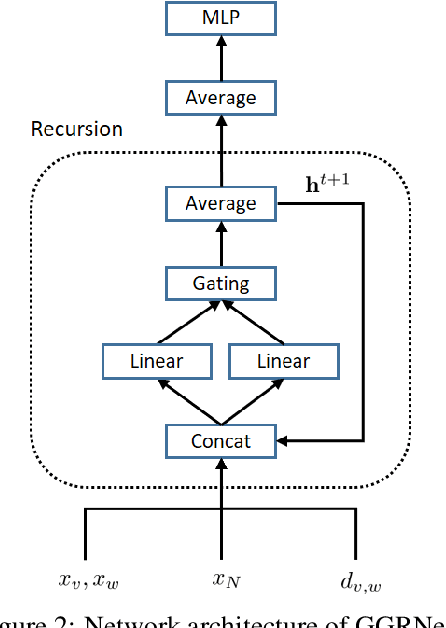
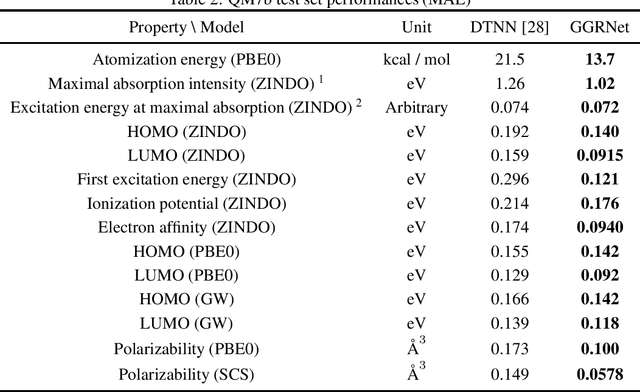
Molecule property prediction is a fundamental problem for computer-aided drug discovery and materials science. Quantum-chemical simulations such as density functional theory (DFT) have been widely used for calculating the molecule properties, however, because of the heavy computational cost, it is difficult to search a huge number of potential chemical compounds. Machine learning methods for molecular modeling are attractive alternatives, however, the development of expressive, accurate, and scalable graph neural networks for learning molecular representations is still challenging. In this work, we propose a simple and powerful graph neural networks for molecular property prediction. We model a molecular as a directed complete graph in which each atom has a spatial position, and introduce a recursive neural network with simple gating function. We also feed input embeddings for every layers as skip connections to accelerate the training. Experimental results show that our model achieves the state-of-the-art performance on the standard benchmark dataset for molecular property prediction.
Improving Multi-Word Entity Recognition for Biomedical Texts
Aug 15, 2019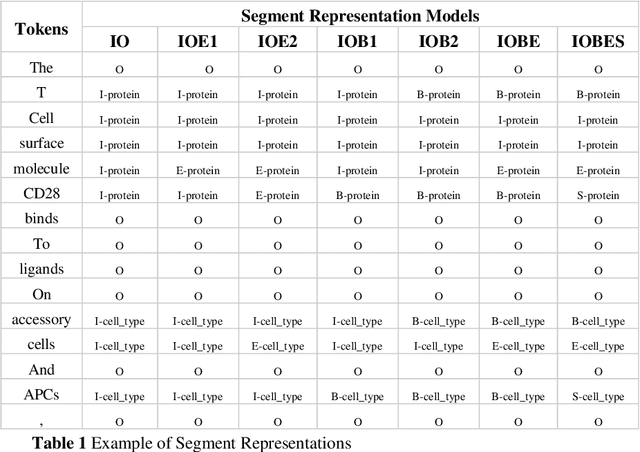
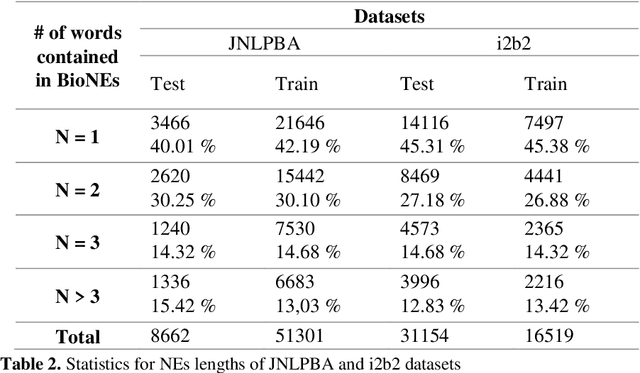
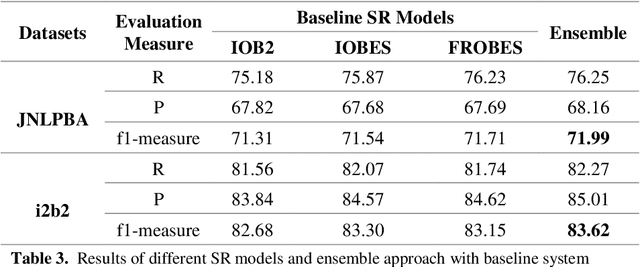
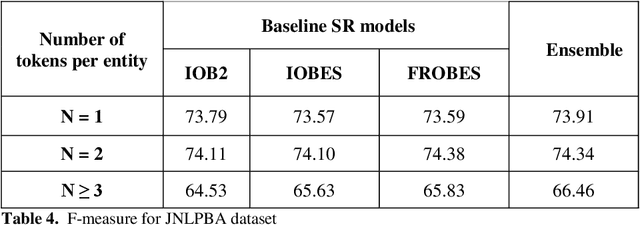
Biomedical Named Entity Recognition (BioNER) is a crucial step for analyzing Biomedical texts, which aims at extracting biomedical named entities from a given text. Different supervised machine learning algorithms have been applied for BioNER by various researchers. The main requirement of these approaches is an annotated dataset used for learning the parameters of machine learning algorithms. Segment Representation (SR) models comprise of different tag sets used for representing the annotated data, such as IOB2, IOE2 and IOBES. In this paper, we propose an extension of IOBES model to improve the performance of BioNER. The proposed SR model, FROBES, improves the representation of multi-word entities. We used Bidirectional Long Short-Term Memory (BiLSTM) network; an instance of Recurrent Neural Networks (RNN), to design a baseline system for BioNER and evaluated the new SR model on two datasets, i2b2/VA 2010 challenge dataset and JNLPBA 2004 shared task dataset. The proposed SR model outperforms other models for multi-word entities with length greater than two. Further, the outputs of different SR models have been combined using majority voting ensemble method which outperforms the baseline models performance.
* 13 pages, 2 figures, International Conference on Cognitive Informatics and Soft Computing (ICCISC-2017)