 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATD-Trans: A Geographically Grounded Japanese-English Travelogue Translation Dataset
May 13, 2026Geographic text, or textual data rich in geographic (geo-) information is a valuable source for various geographic applications, e.g., tourism management. Making such information accessible to speakers of other languages further enhances its utility; thus, accurate machine translation (MT) is essential for equity in multilingual geo-information access. To facilitate in-depth analysis for geographic text, we introduce ATD-Trans, a geographically grounded Japanese--English travelogue translation dataset, which enables evaluation of MT quality at both the overall and geo-entity levels across domestic (within Japan) and overseas regions. Our experiments on existing language models examine two factors: model language focus and geographic regions. The results highlight advantages of Japanese-enhanced models and greater difficulty in translating domestic-region geo-entities mentioned in travel blogs.
CADEL: A Corpus of Administrative Web Documents for Japanese Entity Linking
Mar 31, 2026Entity linking is the task of associating linguistic expressions with entries in a knowledge base that represent real-world entities and concepts. Language resources for this task have primarily been developed for English, and the resources available for evaluating Japanese systems remain limited. In this study, we develop a corpus design policy for the entity linking task and construct an annotated corpus for training and evaluating Japanese entity linking systems, with rich coverage of linguistic expressions referring to entities that are specific to Japan. Evaluation of inter-annotator agreement confirms the high consistency of the annotations in the corpus, and a preliminary experiment on entity disambiguation based on string matching suggests that the corpus contains a substantial number of non-trivial cases, supporting its potential usefulness as an evaluation benchmark.
Comprehensive Evaluation on Lexical Normalization: Boundary-Aware Approaches for Unsegmented Languages
May 28, 2025Lexical normalization research has sought to tackle the challenge of processing informal expressions in user-generated text, yet the absence of comprehensive evaluations leaves it unclear which methods excel across multiple perspectives. Focusing on unsegmented languages, we make three key contributions: (1) creating a large-scale, multi-domain Japanese normalization dataset, (2) developing normalization methods based on state-of-the-art pretrained models, and (3) conducting experiments across multiple evaluation perspectives. Our experiments show that both encoder-only and decoder-only approaches achieve promising results in both accuracy and efficiency.
Graph-Structured Trajectory Extraction from Travelogues
Oct 22, 2024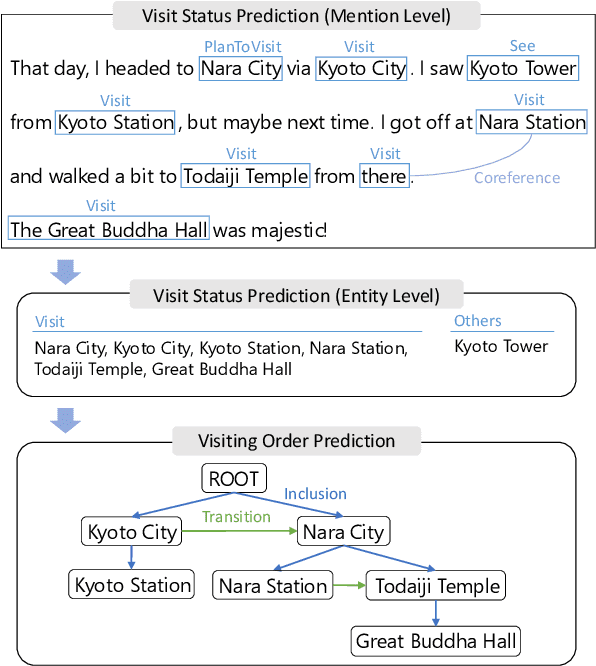

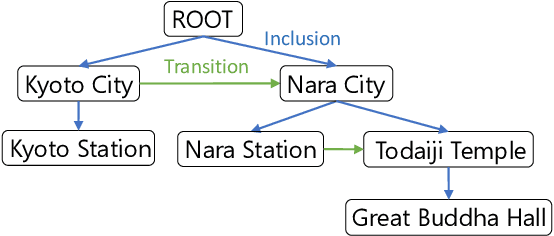
Previous studies on sequence-based extraction of human movement trajectories have an issue of inadequate trajectory representation. Specifically, a pair of locations may not be lined up in a sequence especially when one location includes the other geographically. In this study, we propose a graph representation that retains information on the geographic hierarchy as well as the temporal order of visited locations, and have constructed a benchmark dataset for graph-structured trajectory extraction. The experiments with our baselines have demonstrated that it is possible to accurately predict visited locations and the order among them, but it remains a challenge to predict the hierarchical relations.
Arukikata Travelogue Dataset with Geographic Entity Mention, Coreference, and Link Annotation
May 23, 2023
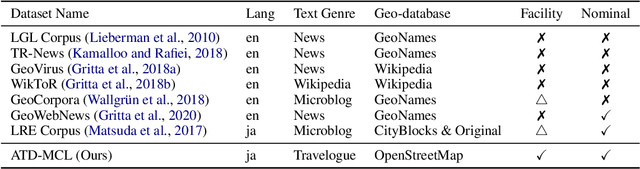
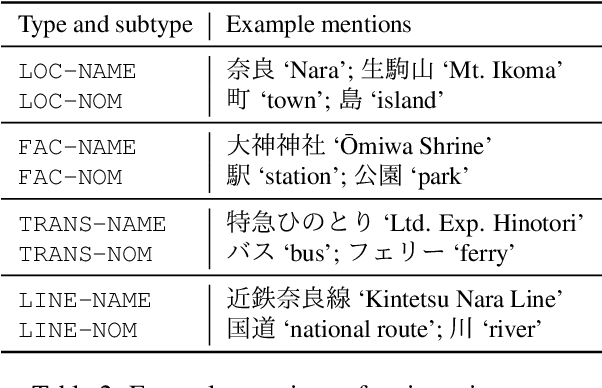

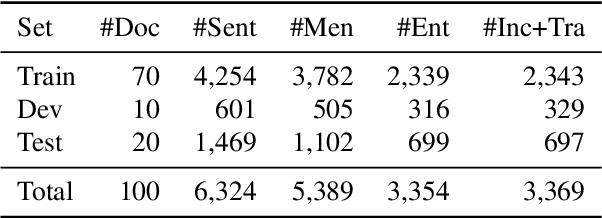
Geoparsing is a fundamental technique for analyzing geo-entity information in text. We focus on document-level geoparsing, which considers geographic relatedness among geo-entity mentions, and presents a Japanese travelogue dataset designed for evaluating document-level geoparsing systems. Our dataset comprises 200 travelogue documents with rich geo-entity information: 12,171 mentions, 6,339 coreference clusters, and 2,551 geo-entities linked to geo-database entries.
Arukikata Travelogue Dataset
May 19, 2023
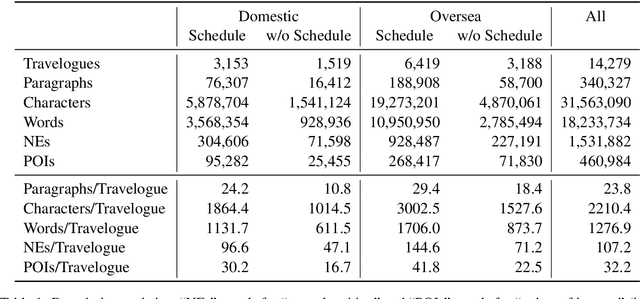
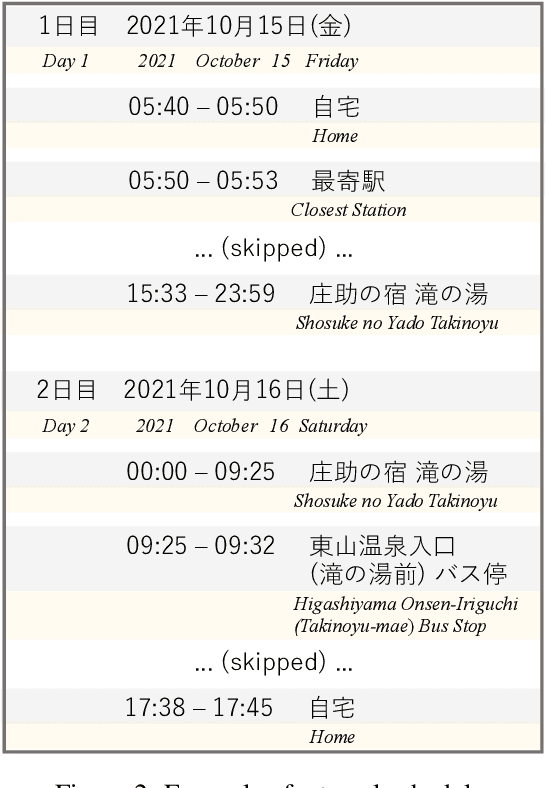
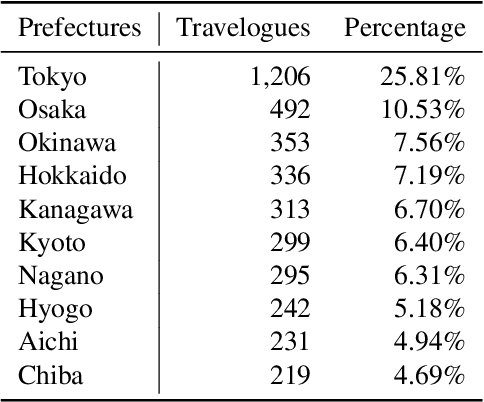
We have constructed Arukikata Travelogue Dataset and released it free of charge for academic research. This dataset is a Japanese text dataset with a total of over 31 million words, comprising 4,672 Japanese domestic travelogues and 9,607 overseas travelogues. Before providing our dataset, there was a scarcity of widely available travelogue data for research purposes, and each researcher had to prepare their own data. This hinders the replication of existing studies and fair comparative analysis of experimental results. Our dataset enables any researchers to conduct investigation on the same data and to ensure transparency and reproducibility in research. In this paper, we describe the academic significance, characteristics, and prospects of our dataset.
User-Generated Text Corpus for Evaluating Japanese Morphological Analysis and Lexical Normalization
Apr 08, 2021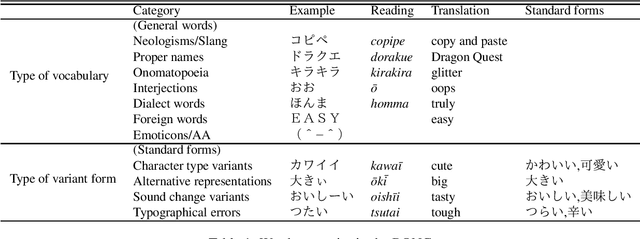
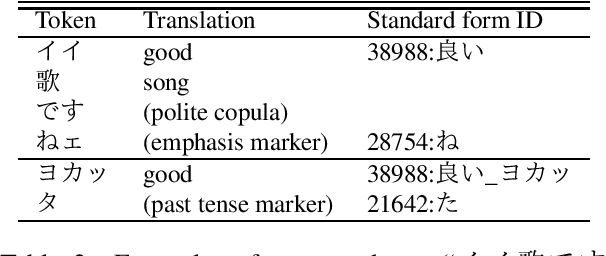

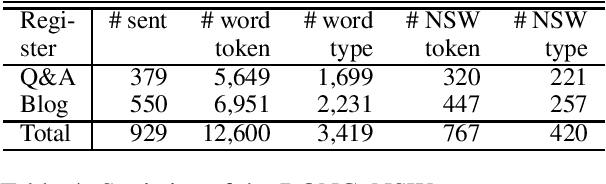
Morphological analysis (MA) and lexical normalization (LN) are both important tasks for Japanese user-generated text (UGT). To evaluate and compare different MA/LN systems, we have constructed a publicly available Japanese UGT corpus. Our corpus comprises 929 sentences annotated with morphological and normalization information, along with category information we classified for frequent UGT-specific phenomena. Experiments on the corpus demonstrated the low performance of existing MA/LN methods for non-general words and non-standard forms, indicating that the corpus would be a challenging benchmark for further research on UGT.